


一、概率论基础
样本空间与随机事件
定义(随机试验)
在相同条件下可重复进行、但结果事先不确定的试验。
定义(样本空间)
样本空间 $\Omega$ 为试验所有可能结果(样本点)的集合。
定义(随机事件)
事件 $A$ 为 $\Omega$ 的子集。事件发生指试验结果 $\omega\in A$。
事件的关系与运算
定义(包含、相等)
若 $A\subset B$,称 $A$ 蕴含 $B$;若 $A\subset B$ 且 $B\subset A$,则 $A=B$。
定义(对立事件)
事件 $A$ 的对立事件为 $A^c=\Omega\setminus A$。
定义(互斥/互不相容)
若 $A\cap B=\varnothing$,称 $A,B$ 互斥。
性质(德摩根律)
De Morgan’s laws
$$
(A\cup B)^c=A^c\cap B^c,\qquad (A\cap B)^c=A^c\cup B^c.
$$
▸推导(集合运算的逐点验证)
取任意 $\omega\in\Omega$:
- $\omega\in (A\cup B)^c \Leftrightarrow \omega\notin A\cup B \Leftrightarrow (\omega\notin A)\land(\omega\notin B) \Leftrightarrow \omega\in A^c\cap B^c$。
另一条同理(把 “$\cup$ 与 $\cap$” 对换即可)。
概率的定义:从直观到公理
直观(古典概型:等可能)
若 $\Omega$ 有限且各样本点等可能,则
$$
P(A)=\frac{|A|}{|\Omega|}.
$$
直观(几何概型)
若 $\Omega$ 为平面/空间区域、落点“均匀”,则
$$
P(A)=\frac{\text{measure}(A)}{\text{measure}(\Omega)}.
$$
直观(频率解释)
大量重复试验中事件发生频率趋于稳定值,可视为概率的经验近似。
概率公理与基本性质
公理(概率:科尔莫戈罗夫公理)
Kolmogorov axioms
在事件域($\sigma$-代数)上,概率 $P(\cdot)$ 满足:
- 非负性:$P(A)\ge 0$
- 规范性:$P(\Omega)=1$
- 可列可加性:若 $A_i$ 两两互斥,则
$$
P\left(\bigcup_{i=1}^{\infty}A_i\right)=\sum_{i=1}^{\infty}P(A_i).
$$
性质(有限可加性)
若 $A,B$ 互斥,则 $P(A\cup B)=P(A)+P(B)$。
性质(补事件)
$$
P(A^c)=1-P(A).
$$
性质(加法公式)
$$
P(A\cup B)=P(A)+P(B)-P(A\cap B).
$$
▸推导(加法公式)
将 $A\cup B$ 分解为不交并:
$$
A\cup B = A\ \dot\cup\ (B\setminus A),
$$
因而
$$
P(A\cup B)=P(A)+P(B\setminus A).
$$
又 $B = (B\setminus A)\ \dot\cup\ (A\cap B)$,故 $P(B)=P(B\setminus A)+P(A\cap B)$,代回即得。
性质(连续性:从上/从下)
若 $A_1\subset A_2\subset\cdots$,令 $A=\bigcup_{n\ge1}A_n$,则
$$
P(A_n)\uparrow P(A).
$$
若 $A_1\supset A_2\supset\cdots$,令 $A=\bigcap_{n\ge1}A_n$,则
$$
P(A_n)\downarrow P(A).
$$
条件概率、乘法公式、全概率与贝叶斯
定义(条件概率)
若 $P(B)>0$,则
$$
P(A\mid B)=\frac{P(A\cap B)}{P(B)}.
$$
定理(乘法公式)
$$
P(A\cap B)=P(B),P(A\mid B)=P(A),P(B\mid A).
$$
定理(全概率公式)
设 ${B_i}$ 为样本空间的一个划分(两两互斥且 $\bigcup B_i=\Omega$),且 $P(B_i)>0$,则
$$
P(A)=\sum_i P(B_i),P(A\mid B_i).
$$
定理(贝叶斯公式)
Bayes’ theorem
在上述划分下,
$$
P(B_j\mid A)=\frac{P(B_j),P(A\mid B_j)}{\sum_i P(B_i),P(A\mid B_i)}.
$$
▸推导(全概率与贝叶斯)
由划分:$A=\bigcup_i (A\cap B_i)$ 且各项互斥,因此
$$
P(A)=\sum_i P(A\cap B_i)=\sum_i P(B_i)P(A\mid B_i).
$$
又
$$
P(B_j\mid A)=\frac{P(A\cap B_j)}{P(A)}=\frac{P(B_j)P(A\mid B_j)}{\sum_i P(B_i)P(A\mid B_i)}.
$$
某病患病率 $P(D)=0.01$,检测灵敏度 $P(+\mid D)=0.99$,特异度 $P(-\mid D^c)=0.95$。求阳性后患病概率 $P(D\mid +)$。
先算 $P(+\mid D^c)=1-0.95=0.05$。全概率:
$$
P(+)=P(D)P(+\mid D)+P(D^c)P(+\mid D^c)=0.01\cdot0.99+0.99\cdot0.05.
$$
贝叶斯:
$$
P(D\mid +)=\frac{0.01\cdot0.99}{0.01\cdot0.99+0.99\cdot0.05}\approx 0.166.
$$
解释:即使“检验很准”,若先验患病率很低,阳性也可能主要来自假阳性。
独立性与伯努利试验
定义(独立事件)
若
$$
P(A\cap B)=P(A)P(B),
$$
则称 $A,B$ 独立。
定义(相互独立)
若任取 $k$ 个事件的交事件概率等于各自概率乘积,则称这一族事件相互独立。
模型(伯努利试验)
Bernoulli trials
重复独立试验,每次成功概率为 $p$。
分布(二项分布)
Binomial distribution
若 $X$ 为 $n$ 次独立伯努利试验中成功次数,则
$$
P(X=k)=\binom{n}{k}p^k(1-p)^{n-k},\qquad k=0,1,\dots,n.
$$
▸推导(二项分布)
固定某一具体序列(恰好 $k$ 次成功):概率为 $p^k(1-p)^{n-k}$。
这样的序列数为 $\binom{n}{k}$(从 $n$ 次里选出 $k$ 次成功的位置),故相加得结论。
抛硬币 10 次,正面概率 $p=0.5$,求恰好 6 次正面概率:
$$
P(X=6)=\binom{10}{6}0.5^{10}.
$$
解释:每个长度为 10 的序列等可能(独立且等概率),满足“6 个正面”的序列共有 $\binom{10}{6}$ 个。
二、随机变量及其分布
随机变量与分布函数
定义(随机变量)
随机变量 $X$ 是从样本空间到实数的函数:
$$
X:\Omega\to\mathbb{R}.
$$
定义(分布函数)
分布函数(CDF)定义为
$$
F_X(x)=P(X\le x).
$$
性质(分布函数的基本性质)
- $F_X(x)$ 单调不减
- $\lim\limits_{x\to-\infty}F_X(x)=0,\quad \lim\limits_{x\to+\infty}F_X(x)=1$
- 右连续:$\lim\limits_{h\downarrow 0}F_X(x+h)=F_X(x)$
▸推导(右连续的由来)
令 $A_h={X\le x+h}$,当 $h\downarrow 0$ 时集合递减且 $\bigcap_{h>0}A_h={X\le x}$。
用概率的“从上连续性”得 $P(A_h)\downarrow P(X\le x)$,即右连续。
离散型随机变量
分布列
定义(分布列 / PMF)
若 $X$ 只取可列值 ${x_k}$,则
$$
p_X(x_k)=P(X=x_k),\qquad \sum_k p_X(x_k)=1.
$$
期望
定义(期望)
$$
E[X]=\sum_k x_k,p_X(x_k).
$$
方差
定义(方差)
$$
\mathrm{Var}(X)=E[(X-E[X])^2]=E[X^2]-(E[X])^2.
$$
常见离散分布
二项分布 / 0-1 分布
0-1 分布
Bernoulli distribution 伯努利分布
$$
P(X=1)=p,\quad P(X=0)=1-p.
$$
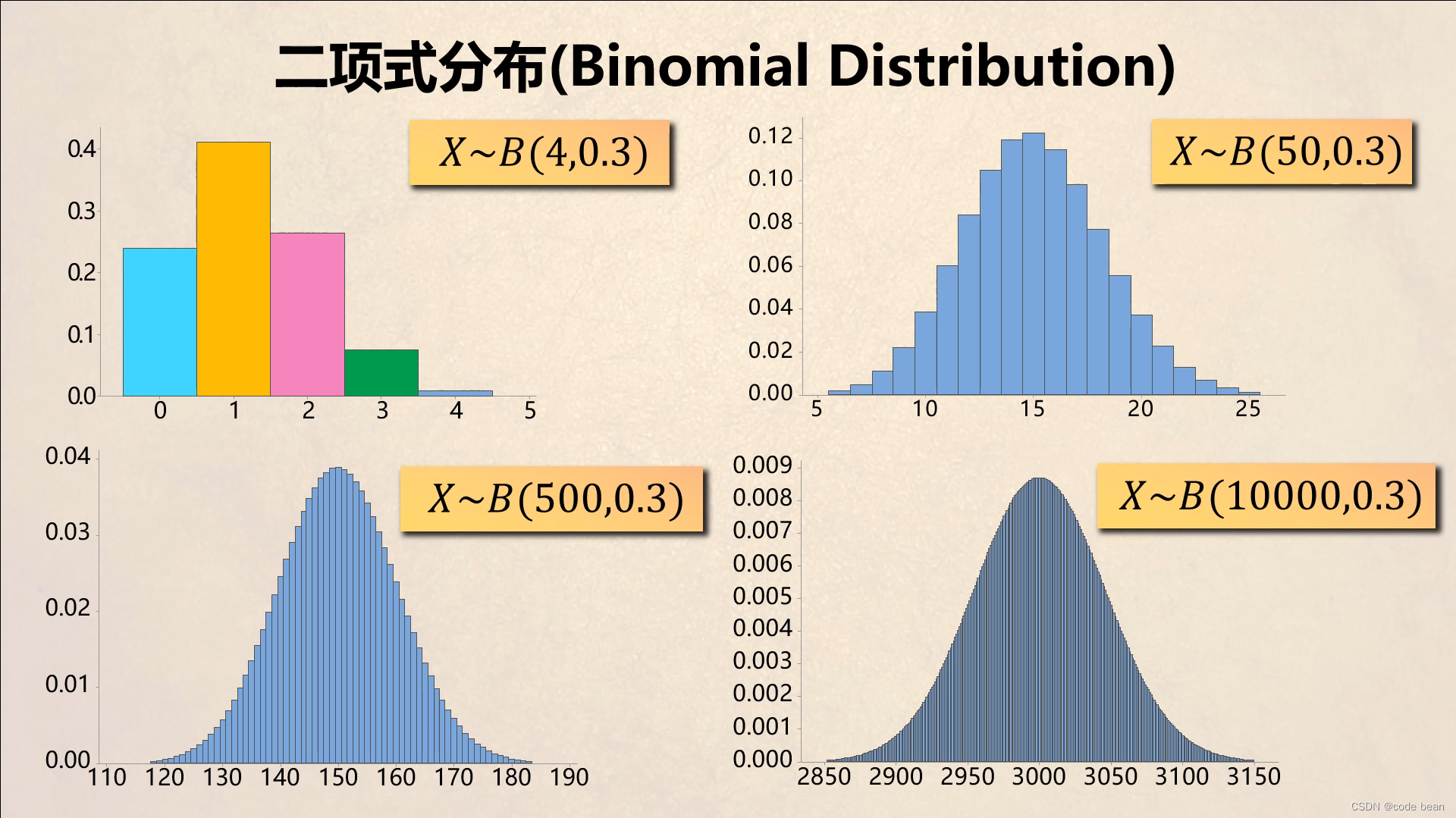
二项分布*
Binomial distribution
若 $X$ 表示 $n$ 次独立伯努利试验(每次成功概率为 $p$)的成功次数,则
$$
P(X=k)=\binom{n}{k}p^k(1-p)^{n-k},\qquad k=0,1,\dots,n.
$$
▸与正态分布的关系($n$ 的位置与含义)
这里的 $n$ 就是“重复试验次数/样本量”。当 $n$ 较大且 $p$ 不太靠近 0 或 1 时,
$$
X\approx N\bigl(np,\ np(1-p)\bigr),
$$
等价的标准化写法是
$$
\frac{X-np}{\sqrt{np(1-p)}}\approx N(0,1).
$$
这就是棣莫弗–拉普拉斯(de Moivre–Laplace)正态近似的核心形式。
泊松分布
Poisson distribution
$$
P(X=k)=e^{-\lambda}\frac{\lambda^k}{k!},\qquad k=0,1,2,\dots
$$
▸直观理解(稀有事件计数)
泊松分布描述“在固定时间/区域内事件发生的次数”。直观前提是:
- 把时间(或区域)切成很多很小的片段,每片段内事件发生概率都很小;
- 不同片段近似独立;
- 平均发生速率稳定(强度参数为 $\lambda$ 或 $\lambda t$)。
在这种结构下,总次数的分布会趋向 $e^{-\lambda}\frac{\lambda^k}{k!}$。
▸推导(由二项分布极限得到泊松分布)
设 $X_n\sim B(n,p_n)$,并令 $n\to\infty$ 时 $p_n\to 0$ 且 $np_n\to\lambda$。对固定 $k$:
$$
P(X_n=k)=\binom{n}{k}p_n^k(1-p_n)^{n-k}.
$$
- 组合数分解:
$$
\binom{n}{k}
=\frac{n(n-1)\cdots(n-k+1)}{k!}
=\frac{n^k}{k!}\prod_{j=0}^{k-1}\left(1-\frac{j}{n}\right).
$$
当 $n\to\infty$ 时,$\prod_{j=0}^{k-1}\left(1-\frac{j}{n}\right)\to 1$,故 $\binom{n}{k}\sim \frac{n^k}{k!}$。 - 因为 $np_n\to\lambda$,所以 $n^k p_n^k\to \lambda^k$。
- 处理 $(1-p_n)^{n-k}$:
$$
(1-p_n)^{n-k}=(1-p_n)^n\cdot(1-p_n)^{-k}\to (1-p_n)^n.
$$
又由 $\lim_{n\to\infty}\left(1-\frac{\lambda}{n}\right)^n=e^{-\lambda}$ 以及 $p_n\sim \lambda/n$,得 $(1-p_n)^n\to e^{-\lambda}$。
因此
$$
P(X_n=k)\to e^{-\lambda}\frac{\lambda^k}{k!}.
$$
当 $n$ 大、$p$ 小且 $np=\lambda$ 固定时,$X\sim B(n,p)$ 可近似为 $P(\lambda)$。
解释:大量独立“小概率事件”的总次数常出现泊松规律(稀有事件定律)。
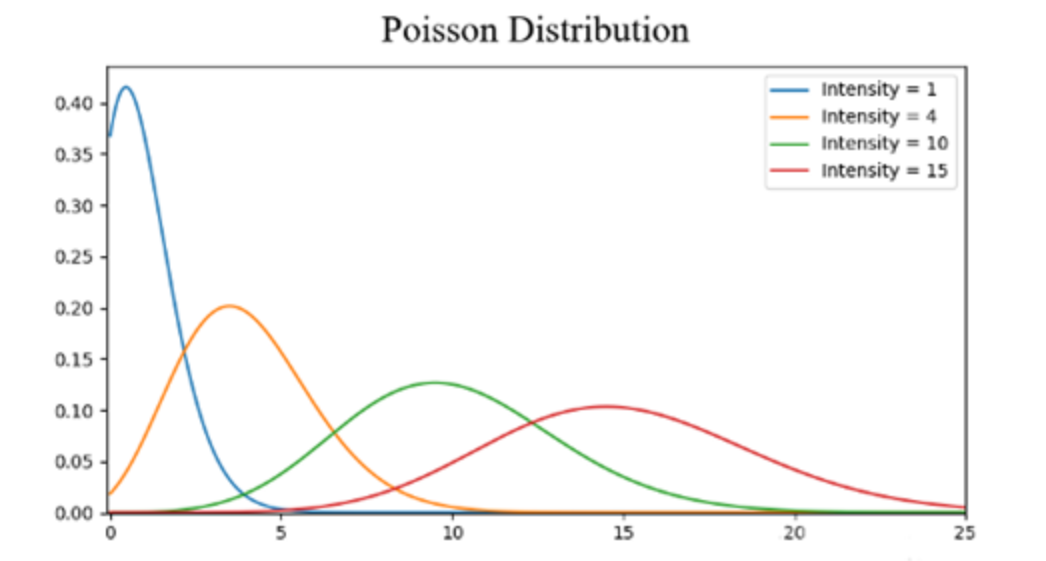
▸参数 $\lambda$(intensity/强度)的含义
- 在计数模型里(Poisson process):$\lambda$ 表示单位时间/单位面积/单位体积内的平均发生次数(到达率、强度)。例如“每分钟平均 3 次”可写作 $\lambda=3\ \mathrm{min}^{-1}$。
- 在泊松分布 $X\sim \mathrm{Poisson}(\lambda)$ 里:$\lambda$ 既是该计数的均值,也是方差:
$$
E[X]=\lambda,\qquad \mathrm{Var}(X)=\lambda.
$$
某呼叫中心平均每小时来电 2 次,假设来电次数服从泊松分布,则 1 小时内来电数 $X\sim \mathrm{Poisson}(2)$。
求“至少 1 次来电”的概率:
$$
P(X\ge 1)=1-P(X=0)=1-e^{-2}.
$$
解释:泊松分布常用补事件计算,$k=0$ 最容易。
观测 10 个相同长度时间窗内的事件次数:
$$
1,\ 0,\ 2,\ 1,\ 3,\ 2,\ 1,\ 0,\ 2,\ 1.
$$
若用 $X\sim\mathrm{Poisson}(\lambda)$ 建模,则一个自然估计是样本均值:
$$
\hat\lambda=\overline X=\frac{13}{10}=1.3.
$$
解释:因为 $E[X]=\lambda$,用样本均值估计总体均值最直接。
连续型随机变量
密度函数
定义(密度函数 / PDF)
若存在非负函数 $f_X(x)$ 使
$$
F_X(x)=\int_{-\infty}^{x} f_X(t),dt,
$$
则称 $f_X$ 为密度。并有
$$
P(a<X\le b)=\int_a^b f_X(x),dx,\qquad \int_{-\infty}^{\infty}f_X(x),dx=1.
$$
期望
定义(期望:LOTUS)
若 $g$ 可积,则
$$
E[g(X)]=\int_{-\infty}^{\infty} g(x)f_X(x),dx.
$$
▸$g(x)$ 是什么
$g$ 表示嵌套函数,可以是任何可积函数:
- $g(x)=x$ 得 $E[X]$;
- $g(x)=x^2$ 得 $E[X^2]$(进而可算方差);
- $g(x)=\mathbf{1}(x\le a)$ 得 $E[\mathbf{1}(X\le a)]=P(X\le a)=F_X(a)$。
LOTUS 的作用是:把“对随机变量的平均”变成“对数轴上函数的加权积分”。
若 $X\sim U(0,1)$,取 $g(x)=x^2$:
$$
E[X^2]=\int_0^1 x^2\cdot 1,dx=\frac{1}{3}.
$$
常见连续分布
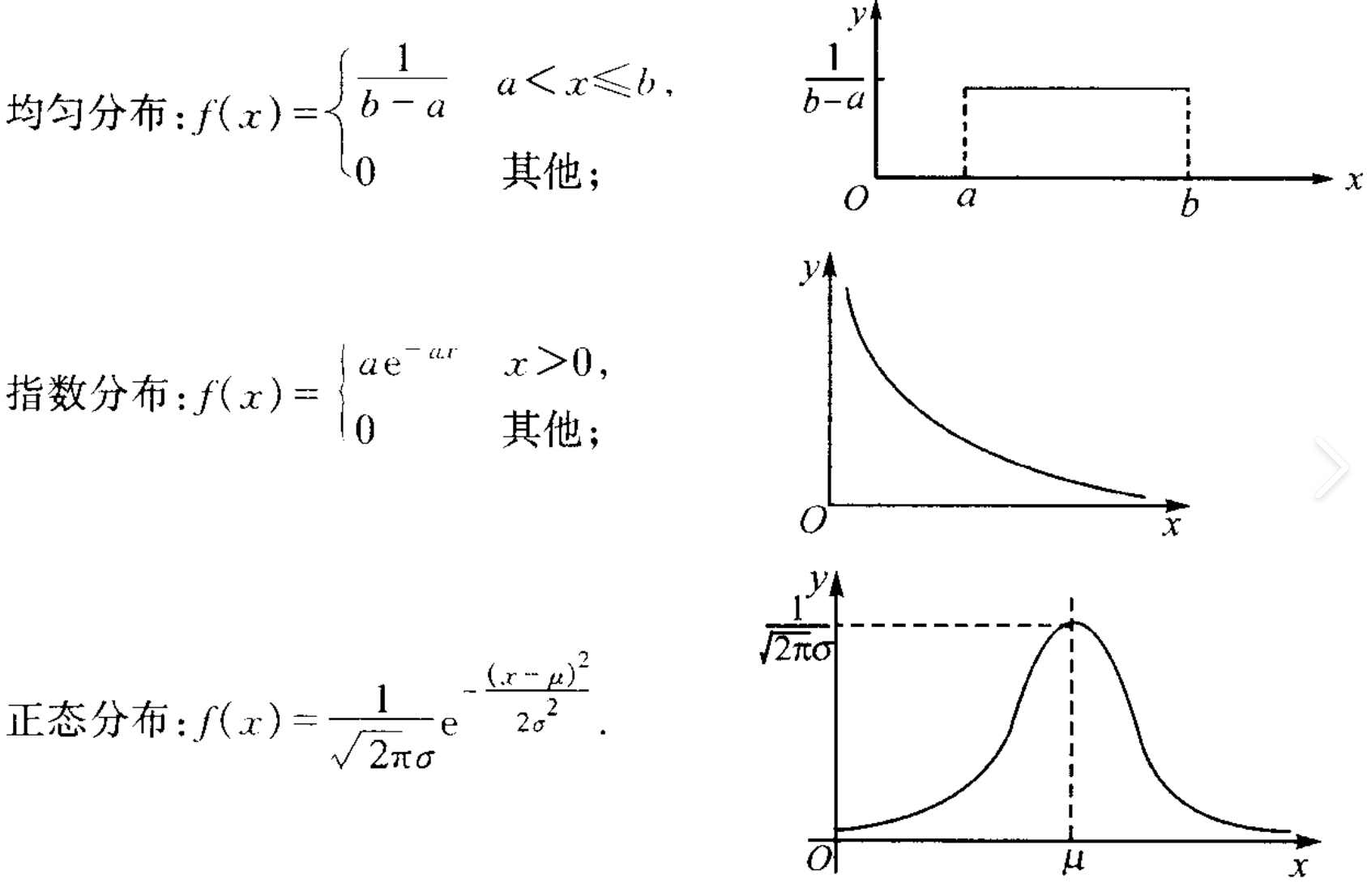
均匀分布
Uniform distribution
若 $X\sim U(a,b)$,则
$$
f_X(x)=\frac{1}{b-a}\mathbf{1}_{[a,b]}(x).
$$
▸直观理解
均匀分布表示“在区间 $[a,b]$ 上等可能落点”,同长度的小区间具有相同概率。
若 $X\sim U(0,10)$,则
$$
P(2<X<5)=\int_2^5 \frac{1}{10},dx=\frac{3}{10}.
$$
指数分布
Exponential distribution
若 $X\sim \mathrm{Exp}(\lambda)$,则
$$
f_X(x)=\lambda e^{-\lambda x}\mathbf{1}_{x\ge 0}.
$$
▸直观理解(等待时间)
指数分布常用来描述“速率为 $\lambda$ 的随机事件”的等待时间。其尾概率为
$$
P(X>t)=e^{-\lambda t},
$$
表示等待越久,“还要继续等”的概率按指数方式衰减。
▸指数分布 vs 泊松分布(联系与区别)
在泊松过程中:
- $N(t)$:长度为 $t$ 的区间内事件次数,$N(t)\sim \mathrm{Poisson}(\lambda t)$(离散计数)。
- $T$:相邻两次事件之间的等待时间,$T\sim \mathrm{Exp}(\lambda)$(连续时间)。
联系可由“0 次事件”连接:
$$
P(T>t)=P(N(t)=0)=e^{-\lambda t}.
$$
▸推导:由 $P(N(t)=0)$ 得到指数分布密度
若 $T$ 为首次到达时间,则 $P(T>t)=P(N(t)=0)$。
若 $N(t)\sim \mathrm{Poisson}(\lambda t)$,则 $P(N(t)=0)=e^{-\lambda t}$,所以
$$
F_T(t)=1-e^{-\lambda t}\ (t\ge 0),\qquad
f_T(t)=F_T’(t)=\lambda e^{-\lambda t}\mathbf{1}_{t\ge 0}.
$$
指数分布性质(无记忆性)
$$
P(X>s+t\mid X>s)=P(X>t).
$$
▸推导(无记忆性)
对指数分布:
$$
P(X>u)=\int_u^\infty \lambda e^{-\lambda x},dx=e^{-\lambda u}.
$$
因此
$$
P(X>s+t\mid X>s)=\frac{e^{-\lambda(s+t)}}{e^{-\lambda s}}=e^{-\lambda t}=P(X>t).
$$
若等车时间 $X\sim \mathrm{Exp}(\lambda)$,已等了 $s$ 分钟,求还要再等超过 $t$ 分钟的概率:
$$
P(X>s+t\mid X>s)=P(X>t)=e^{-\lambda t}.
$$
正态分布
Normal distribution
若 $X\sim N(\mu,\sigma^2)$,则
$$
f_X(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right).
$$
▸直观理解
正态分布是大量独立小扰动相加后的典型形状(中心极限定理说明其普适性)。
参数含义:$\mu$ 决定中心位置,$\sigma$ 决定分散程度。
▸推导:归一化常数 $\frac{1}{\sqrt{2\pi}\sigma}$ 从哪里来
先处理标准正态的积分
$$
I=\int_{-\infty}^{\infty}e^{-x^2/2},dx.
$$
计算 $I^2$:
$$
I^2=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}e^{-(x^2+y^2)/2},dx,dy.
$$
改用极坐标(雅可比为 $r$):
$$
I^2=\int_0^{2\pi}\int_0^{\infty}e^{-r^2/2},r,dr,d\theta
=2\pi\int_0^{\infty}e^{-r^2/2},r,dr.
$$
令 $u=r^2/2$,$du=r,dr$:
$$
I^2=2\pi\int_0^{\infty}e^{-u},du=2\pi.
$$
因此 $I=\sqrt{2\pi}$,标准正态密度为 $\frac{1}{\sqrt{2\pi}}e^{-x^2/2}$。
一般正态由标准化 $z=\frac{x-\mu}{\sigma}$ 得
$$
f_X(x)=\frac{1}{\sigma}\cdot \frac{1}{\sqrt{2\pi}}e^{-(x-\mu)^2/(2\sigma^2)}.
$$
若 $X\sim N(\mu,\sigma^2)$,令 $Z=\frac{X-\mu}{\sigma}$,则 $Z\sim N(0,1)$,从而
$$
P(X\le a)=P\left(Z\le \frac{a-\mu}{\sigma}\right)=\Phi\left(\frac{a-\mu}{\sigma}\right).
$$
随机变量函数的分布
分布函数法
方法(分布函数法)
令 $Y=g(X)$,先求 $F_Y(y)=P(Y\le y)=P(g(X)\le y)$,再对 $y$ 求导得到密度(若存在)。
设 $X\sim N(0,1)$,令 $Y=|X|$。对 $y\ge 0$:
$$
F_Y(y)=P(|X|\le y)=P(-y\le X\le y)=\Phi(y)-\Phi(-y)=2\Phi(y)-1.
$$
对 $y$ 求导得到密度:
$$
f_Y(y)=2\varphi(y)\mathbf{1}_{y\ge 0},
$$
其中 $\varphi$ 为标准正态密度。
单调变换公式
定理(单调变换的密度公式)
若 $g$ 严格单调可导,$Y=g(X)$,则
$$
f_Y(y)=f_X\bigl(g^{-1}(y)\bigr)\left|\frac{d}{dy}g^{-1}(y)\right|.
$$
▸推导(单调变换)
若 $g$ 单调增,则
$$
F_Y(y)=P(g(X)\le y)=P(X\le g^{-1}(y))=F_X(g^{-1}(y)).
$$
两边对 $y$ 求导:
$$
f_Y(y)=f_X(g^{-1}(y))\cdot (g^{-1})’(y).
$$
单调减时得到负号,统一写成绝对值。
若 $X\sim U(0,1)$,取 $Y=-\ln X$。
因为 $x=e^{-y}$($y\ge 0$),且 $\left|\frac{dx}{dy}\right|=e^{-y}$,
$$
f_Y(y)=f_X(e^{-y})e^{-y}=1\cdot e^{-y},\quad y\ge 0,
$$
所以 $Y\sim \mathrm{Exp}(1)$。解释:把 $(0,1)$ 上的“均匀”通过对数拉伸后,变成右尾指数衰减。
若 $X\sim U(0,1)$,令 $Y=\sqrt{X}$。则 $x=y^2$($0\le y\le 1$),且 $\left|\frac{dx}{dy}\right|=2y$:
$$
f_Y(y)=f_X(y^2)\cdot 2y=1\cdot 2y,\quad 0\le y\le 1.
$$
设 $X\sim N(0,1)$,令 $Y=X^2$。对 $y\ge 0$:
$$
F_Y(y)=P(X^2\le y)=P(-\sqrt{y}\le X\le \sqrt{y})=2\Phi(\sqrt{y})-1.
$$
对 $y$ 求导(链式法则):
$$
f_Y(y)=\frac{1}{\sqrt{y}}\varphi(\sqrt{y})\mathbf{1}_{y>0}
=\frac{1}{\sqrt{2\pi y}}e^{-y/2}\mathbf{1}_{y>0}.
$$
多维随机变量
(二维为主)
联合分布与联合密度
定义(联合分布函数)
$$
F_{X,Y}(x,y)=P(X\le x,\ Y\le y).
$$
定义(联合密度)
若存在 $f_{X,Y}(x,y)\ge 0$ 使
$$
P((X,Y)\in D)=\iint_D f_{X,Y}(x,y),dx,dy,
$$
则称 $f_{X,Y}$ 为联合密度。
边缘分布与条件分布
定义(边缘密度)
$$
f_X(x)=\int_{-\infty}^{\infty} f_{X,Y}(x,y),dy,\qquad
f_Y(y)=\int_{-\infty}^{\infty} f_{X,Y}(x,y),dx.
$$
定义(条件密度)
若 $f_Y(y)>0$,则
$$
f_{X\mid Y}(x\mid y)=\frac{f_{X,Y}(x,y)}{f_Y(y)}.
$$
独立性
定义(独立性判定)
若
$$
f_{X,Y}(x,y)=f_X(x)f_Y(y),
$$
则 $X,Y$ 独立(连续情形;离散情形同理把密度换成分布列)。
数字特征
期望
定义(数学期望)
若 $X$ 离散,取值为 ${x_k}$,则
$$
E[X]=\sum_k x_k,P(X=x_k).
$$
若 $X$ 连续、密度为 $f_X$,则
$$
E[X]=\int_{-\infty}^{\infty}x,f_X(x),dx.
$$
性质(线性性)
$$
E[aX+bY+c]=aE[X]+bE[Y]+c.
$$
▸推导(线性性)
离散情形由求和分配律直接得到;连续情形由积分线性性得到。一般可统一视为“对概率测度积分”的线性性。
方差
定义(方差)
$$
\mathrm{Var}(X)=E\bigl[(X-E[X])^2\bigr].
$$
性质(展开公式)
$$
\mathrm{Var}(X)=E[X^2]-(E[X])^2.
$$
性质(缩放与平移)
$$
\mathrm{Var}(aX+b)=a^2\mathrm{Var}(X).
$$
▸推导(方差展开与缩放)
展开:
$$
\mathrm{Var}(X)=E[X^2-2XE[X]+(E[X])^2]=E[X^2]-2(E[X])^2+(E[X])^2.
$$
缩放:
$$
\mathrm{Var}(aX+b)=E[(aX+b-aE[X]-b)^2]=E[a^2(X-E[X])^2]=a^2\mathrm{Var}(X).
$$
协方差与相关系数
定义(协方差)
$$
\mathrm{Cov}(X,Y)=E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y].
$$
定义(相关系数)
$$
\rho_{XY}=\frac{\mathrm{Cov}(X,Y)}{\sqrt{\mathrm{Var}(X)}\sqrt{\mathrm{Var}(Y)}}.
$$
不等式
性质(切比雪夫不等式)
Chebyshev’s inequality
若 $\mathrm{Var}(X)<\infty$,则对任意 $\varepsilon>0$:
$$
P(|X-E[X]|\ge \varepsilon)\le \frac{\mathrm{Var}(X)}{\varepsilon^2}.
$$
▸推导(由马尔可夫不等式)
对非负随机变量 $Z$ 有马尔可夫不等式:$P(Z\ge a)\le \frac{E[Z]}{a}$。
取 $Z=(X-E[X])^2$,$a=\varepsilon^2$,即得
$$
P(|X-E[X]|\ge \varepsilon)=P((X-E[X])^2\ge \varepsilon^2)\le \frac{E[(X-E[X])^2]}{\varepsilon^2}.
$$
若已知 $E[X]=10,\ \mathrm{Var}(X)=4$,则
$$
P(|X-10|\ge 3)\le \frac{4}{9}.
$$
解释:不需要知道具体分布,只靠均值与方差就能给出“偏离均值概率”的上界。