


四、数理统计基础
▸直观理解这一章在干什么
统计推断可以用一句话记:“从样本反推总体/参数,并量化不确定性。”
会反复用到的三件武器:
- 抽样分布:在某个总体假设下,统计量(如 $\overline X,S^2,T,F$)自己是什么分布。
- 标准化/枢轴量:把“含参数的量”变成“已知分布的量”,才能做区间估计与检验。
- 大样本思想:样本大时,$\overline X$ 近似正态(CLT),很多方法都可用“近似正态”统一理解。
简记:“先找统计量的分布(或近似分布),再做标准化。”
基本概念
定义(总体、样本、样本容量)
总体:研究对象全体;样本:从总体抽取的个体集合;样本容量为 $n$。
定义(简单随机样本)
设总体分布为 $F$,若 $X_1,\dots,X_n$ 独立同分布且均服从 $F$,称其为来自 $F$ 的简单随机样本。
定义(统计量)
统计量 $T=T(X_1,\dots,X_n)$ 是样本的函数,且不含未知参数。
定义(样本均值与样本方差)
$$
\overline{X}=\frac{1}{n}\sum_{i=1}^{n}X_i,\qquad
S^2=\frac{1}{n-1}\sum_{i=1}^{n}(X_i-\overline{X})^2.
$$
▸推导:为什么样本方差用 $\frac{1}{n-1}$
设 $X_i$ 独立同分布,$E[X_i]=\mu$,$\mathrm{Var}(X_i)=\sigma^2$。
记 $Q=\sum_{i=1}^n (X_i-\overline X)^2$,利用恒等式
$$
\sum_{i=1}^n (X_i-\overline X)^2=\sum_{i=1}^n (X_i-\mu)^2-n(\overline X-\mu)^2.
$$
取期望:
$$
E\left[\sum_{i=1}^n (X_i-\mu)^2\right]=n\sigma^2,\qquad
E\left[n(\overline X-\mu)^2\right]=n\mathrm{Var}(\overline X)=n\cdot \frac{\sigma^2}{n}=\sigma^2.
$$
因而 $E[Q]=(n-1)\sigma^2$,故 $E!\left[\frac{Q}{n-1}\right]=\sigma^2$,即 $S^2$ 无偏。
定义(经验分布函数)
$$
F_n(x)=\frac{1}{n}\sum_{i=1}^{n}\mathbf{1}(X_i\le x).
$$
定理(格利文科定理)
Glivenko–Cantelli theorem
若 $X_1,\dots,X_n$ 为来自 $F$ 的简单随机样本,则
$$
\sup_x |F_n(x)-F(x)|\xrightarrow{a.s.}0.
$$
▸直观
$F_n$ 是“样本频率版的 CDF”。该定理说明:样本越大,整条经验分布曲线会几乎处处贴近真实分布曲线。
抽样分布(正态总体)
结论(正态总体下的核心抽样分布)
设 $X_1,\dots,X_n\stackrel{iid}{\sim}N(\mu,\sigma^2)$。
样本均值:
$$
\overline X\sim N\left(\mu,\frac{\sigma^2}{n}\right).
$$样本方差的卡方分布:
$$
\frac{(n-1)S^2}{\sigma^2}\sim \chi^2(n-1).
$$均值的 t 统计量:
Student’s t distribution
$$
T=\frac{\overline X-\mu}{S/\sqrt{n}}\sim t(n-1).
$$方差比的 F 分布:
F distribution
若 $U\sim\chi^2(\nu_1)$、$V\sim\chi^2(\nu_2)$ 独立,则
$$
F=\frac{U/\nu_1}{V/\nu_2}\sim F(\nu_1,\nu_2).
$$
▸推导主线:为什么会出现 $\chi^2/t/F$
- 正态向量经正交变换仍正态;把“均值方向”和“偏差方向”分解,可得 $\overline X$ 与样本离差平方和独立。
- 标准正态平方和给出 $\chi^2$;正态除以独立的卡方平方根得到 $t$;两个独立卡方的比得到 $F$。
分位数与临界值
定义(分位数)
对分布函数 $F$,若 $F(x_\alpha)=\alpha$,则称 $x_\alpha$ 为 $\alpha$ 分位数。常写作:
$$
z_\alpha,\ t_{\alpha,\nu},\ \chi^2_{\alpha,\nu},\ F_{\alpha,\nu_1,\nu_2}.
$$
充分统计量
定义(充分统计量)
若在给定统计量 $T(X)$ 的条件下,样本 $X=(X_1,\dots,X_n)$ 的条件分布不含参数 $\theta$,则称 $T$ 为 $\theta$ 的充分统计量。
定理(因子分解定理)
Factorization theorem
若样本联合密度/概率为 $f(x;\theta)$,则 $T(x)$ 充分当且仅当可写作
$$
f(x;\theta)=g(T(x),\theta),h(x),
$$
其中 $h$ 与 $\theta$ 无关。
▸推导思路(把“参数信息”集中到 $T$)
因子分解意味着:样本中与参数相关的部分仅通过 $T(x)$ 进入;其余 $h(x)$ 只描述“与参数无关的形状”。
若 $\sigma^2$ 已知,$X_i\sim N(\mu,\sigma^2)$:
$$
f(x;\mu)\propto \exp\left(-\frac{1}{2\sigma^2}\sum_{i=1}^n (x_i-\mu)^2\right)
=\exp\left(-\frac{1}{2\sigma^2}\sum x_i^2\right)\cdot \exp\left(\frac{\mu}{\sigma^2}\sum x_i-\frac{n\mu^2}{2\sigma^2}\right).
$$
其中与 $\mu$ 有关的部分只通过 $\sum x_i$(等价于 $\overline X$)出现,因此 $\overline X$ 是 $\mu$ 的充分统计量。
五、参数估计
▸直观理解(参数估计)
参数估计分两类:
- 点估计:给一个“最像的数” $\hat\theta$。
- 区间估计:给一个“可信范围” $[L,U]$ 并附带置信度 $1-\alpha$。
三步走(做题流程):
- 在估什么($\mu$、$\sigma^2$、$p$、$\lambda$…)以及样本来自什么模型;
- 选方法:MOM(用矩匹配)、MLE(最大化似然)、或用抽样分布/枢轴量做区间;
- 评价好不好:无偏/相合/MSE/有效性/渐近正态性(看题目问什么)。
简记:“点:MOM/MLE;区间:枢轴量;好坏:无偏相合 + 方差/MSE。”
点估计
定义(点估计与估计量)
以统计量 $\hat\theta=\hat\theta(X_1,\dots,X_n)$ 估计参数 $\theta$,称 $\hat\theta$ 为估计量,取值为估计值。
方法(矩估计法)
Method of moments (MOM)
用样本矩逼近总体矩:令
$$
\frac{1}{n}\sum_{i=1}^n X_i^k \approx E[X^k],\quad k=1,2,\dots
$$
解出未知参数。
若 $X\sim\mathrm{Exp}(\lambda)$,则 $E[X]=1/\lambda$。取样本均值 $\overline X$,令 $\overline X\approx 1/\lambda$,得
$$
\hat\lambda_{\mathrm{MOM}}=\frac{1}{\overline X}.
$$
方法(极大似然估计)
Maximum likelihood estimation (MLE)
对样本 $x$,似然函数
$$
L(\theta)=f(x;\theta),\qquad \hat\theta=\arg\max_\theta L(\theta).
$$
常用对数似然 $\ell(\theta)=\ln L(\theta)$。
性质(不变性)
若 $\hat\theta$ 是 $\theta$ 的 MLE,则对任意函数 $g$,$g(\hat\theta)$ 是 $g(\theta)$ 的 MLE。
▸推导:不变性
因为对任意 $y=g(\theta)$,最大化 $L(\theta)$ 等价于在可逆映射下最大化 $L(g^{-1}(y))$,取到最大值的位置经 $g$ 映射即为 $g(\hat\theta)$。
设 $X_i\stackrel{iid}{\sim}N(\mu,\sigma^2)$,联合密度
$$
L(\mu,\sigma^2)=\prod_{i=1}^n \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x_i-\mu)^2}{2\sigma^2}\right).
$$
取对数:
$$
\ell(\mu,\sigma^2)=-\frac{n}{2}\ln(2\pi)-n\ln\sigma-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2.
$$
- 固定 $\sigma^2$ 对 $\mu$ 求导:
$$
\frac{\partial \ell}{\partial \mu}=\frac{1}{\sigma^2}\sum_{i=1}^n(x_i-\mu)=0\Rightarrow \hat\mu=\overline x.
$$ - 代回后对 $\sigma^2$ 求导:
$$
\frac{\partial \ell}{\partial \sigma^2}=-\frac{n}{2\sigma^2}+\frac{1}{2\sigma^4}\sum (x_i-\overline x)^2=0
\Rightarrow \widehat{\sigma^2}=\frac{1}{n}\sum (x_i-\overline x)^2.
$$
解释:MLE 的方差分母是 $n$;无偏样本方差分母是 $n-1$(上一节已证明原因)。
估计量评价
无偏性
$$
E[\hat\theta]=\theta.
$$
相合性
Consistency
$$
\hat\theta_n\xrightarrow{P}\theta.
$$
有效性
定义(有效性:无偏情形)
在一组无偏估计量中,若 $\hat\theta$ 的方差达到 Cramér–Rao 下界(或在所有无偏估计量中方差最小),则称 $\hat\theta$ 有效。
判据(达到 Cramér–Rao 下界)
若对某无偏估计量有
$$
\mathrm{Var}(\hat\theta)=\frac{1}{nI(\theta)},
$$
则称其达到 Cramér–Rao 下界(有效)。
▸解释:为什么“有效”只在同一评价标准下比较
无偏性与方差是两条不同维度的评价。通常“有效性”默认限定在无偏估计量类中比较方差;
若允许有偏,则更常用均方误差(MSE)统一衡量(见下)。
均方误差
定义(MSE)
$$
\mathrm{MSE}(\hat\theta)=E[(\hat\theta-\theta)^2]=\mathrm{Var}(\hat\theta)+\bigl(\mathrm{Bias}(\hat\theta)\bigr)^2,
$$
其中 $\mathrm{Bias}(\hat\theta)=E[\hat\theta]-\theta$。
▸推导(偏差-方差分解)
写成 $\hat\theta-\theta=(\hat\theta-E[\hat\theta])+(E[\hat\theta]-\theta)$,两边平方取期望:
$$
E[(\hat\theta-\theta)^2]
=E[(\hat\theta-E[\hat\theta])^2]+2(E[\hat\theta]-\theta)E[\hat\theta-E[\hat\theta]]+(E[\hat\theta]-\theta)^2.
$$
中间项为 0,得到 $\mathrm{Var}(\hat\theta)+\mathrm{Bias}^2$。
渐近正态性
定义(渐近正态性)
Asymptotic normality
若存在常数 $a_n\to\infty$ 使
$$
a_n(\hat\theta_n-\theta)\xrightarrow{d}N(0,\tau^2),
$$
则称 $\hat\theta_n$ 渐近正态。常见情形为 $a_n=\sqrt{n}$。
结论(MLE 的渐近正态性:常用形式)
在正则条件下,MLE 满足
$$
\sqrt{n},(\hat\theta_{\mathrm{MLE}}-\theta)\xrightarrow{d}N\left(0,\frac{1}{I(\theta)}\right),
$$
等价地
$$
\hat\theta_{\mathrm{MLE}}\approx N\left(\theta,\frac{1}{nI(\theta)}\right).
$$
▸直观
与中心极限定理的结构一致:估计误差通常是“许多独立小扰动的平均/和”,因此经 $\sqrt{n}$ 缩放后趋向正态;
信息量 $I(\theta)$ 则决定误差的尺度(信息越大,方差越小)。
定理(Cramér–Rao 下界)
Cramér–Rao lower bound
设正则条件成立,信息量
$$
I(\theta)=E\left[\left(\frac{\partial}{\partial\theta}\ln f(X;\theta)\right)^2\right].
$$
对任意无偏估计量 $\hat\theta$,
$$
\mathrm{Var}(\hat\theta)\ge \frac{1}{nI(\theta)}.
$$
▸推导主线(协方差不等式)
记得分函数 $U(\theta)=\frac{\partial}{\partial\theta}\ln f(X;\theta)$,则 $E[U(\theta)]=0$。
由无偏性对 $\theta$ 求导可得 $E[(\hat\theta-\theta)U(\theta)]=1$。
用 Cauchy–Schwarz:
$$
1=|E[(\hat\theta-\theta)U]|^2\le E[(\hat\theta-\theta)^2]\cdot E[U^2]=\mathrm{Var}(\hat\theta)\cdot I(\theta).
$$
$n$ 个独立样本信息量相加得到 $nI(\theta)$,即结论。
区间估计
定义(置信区间)
对未知参数 $\theta$,若对随机区间 $(L(X),U(X))$ 有
$$
P\bigl(L(X)\le \theta\le U(X)\bigr)=1-\alpha,
$$
则称其为置信度 $1-\alpha$ 的置信区间。
方法(枢轴量法)
Pivot method
构造分布不含未知参数的统计量 $Q(X,\theta)$,使
$$
P(q_1\le Q(X,\theta)\le q_2)=1-\alpha,
$$
再解出 $\theta$ 的区间。
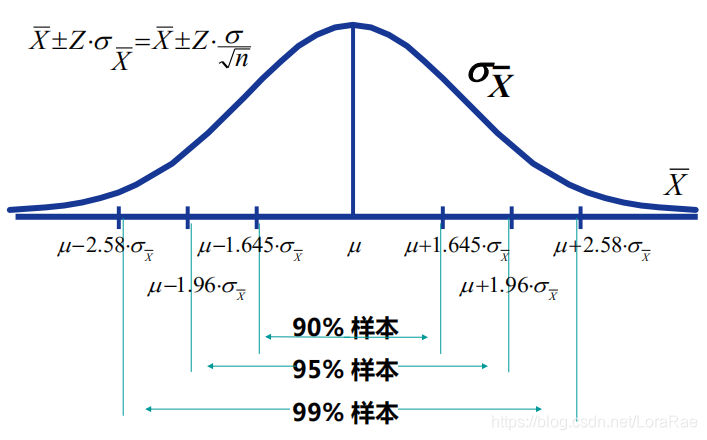
结论(正态总体均值:$\sigma^2$ 已知)
$$
\frac{\overline X-\mu}{\sigma/\sqrt{n}}\sim N(0,1),\qquad
\mu\in \left[\overline X-z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}},\ \overline X+z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}}\right].
$$
结论(正态总体均值:$\sigma^2$ 未知)
Student’s t distribution
$$
\frac{\overline X-\mu}{S/\sqrt{n}}\sim t(n-1),\qquad
\mu\in \left[\overline X-t_{1-\alpha/2,n-1}\frac{S}{\sqrt{n}},\ \overline X+t_{1-\alpha/2,n-1}\frac{S}{\sqrt{n}}\right].
$$
结论(正态总体方差)
$$
\frac{(n-1)S^2}{\sigma^2}\sim \chi^2(n-1),\qquad
\sigma^2\in\left[\frac{(n-1)S^2}{\chi^2_{1-\alpha/2,n-1}},\ \frac{(n-1)S^2}{\chi^2_{\alpha/2,n-1}}\right].
$$
若来自正态总体,$n=16$,观测到 $\overline x=10$,$s=2$,求 $95%$ 均值置信区间。
用 $t$ 区间:$t_{0.975,15}$ 查表,区间为
$$
10\pm t_{0.975,15}\frac{2}{4}.
$$
解释:样本量小且方差未知,用 $t$ 分布比用正态更保守,反映“用 $s$ 代替 $\sigma$ 带来的额外不确定性”。
六、假设检验
▸直观理解(假设检验)
假设检验不是“证明谁对”,而是:在允许一定误报率 $\alpha$ 的前提下,判断数据是否“足够反常”以至于拒绝 $H_0$。
四步走(做题流程):
- 写清楚 $H_0/H_1$(单侧/双侧;简单/复合)。
- 选统计量 $T$(来自抽样分布:$Z/t/\chi^2/F$,或 LRT/NP)。
- 先定 $\alpha$ 再定拒绝域(或等价地算 p 值)。
- 代入样本值下结论(并解释一类/二类错误与功效的含义)。
简记:“先立假设,再选统计量;先定 $\alpha$,再看 p 值/临界值;最后一句话结论。”
基本框架
定义(统计假设)
原假设 $H_0$ 与备择假设 $H_1$ 为关于参数的陈述。
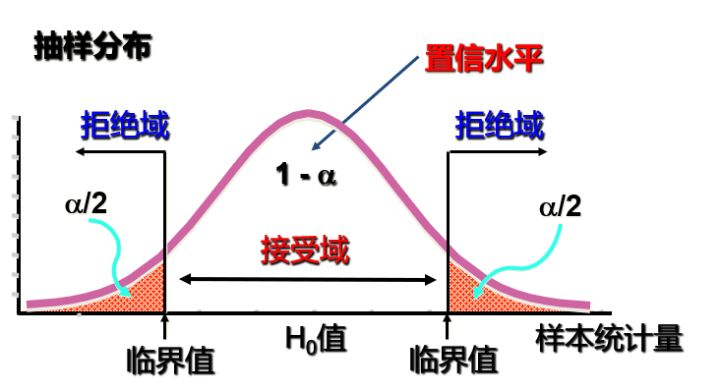
定义(拒绝域与检验水平)
给定检验统计量 $T(X)$ 与拒绝域 $W$,若 $T(X)\in W$ 则拒绝 $H_0$。
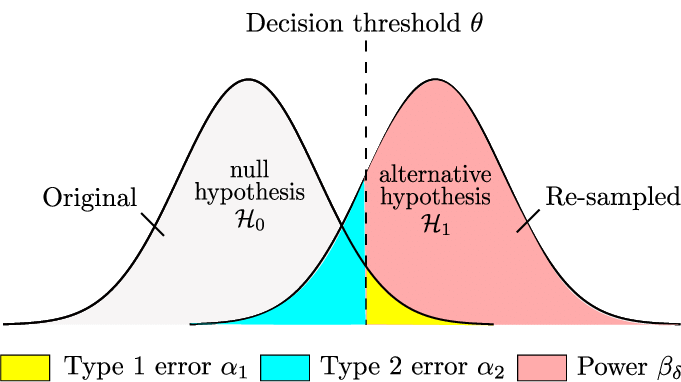
第一类错误
第一类错误概率(弃真)为
$$
\alpha=P(\text{拒绝 }H_0\mid H_0\ \text{为真}).
$$
第二类错误
第二类错误概率(取伪)为
$$
\beta(\theta)=P(\text{不拒绝 }H_0\mid \theta\in \Theta_1),
$$
其中 $\Theta_1$ 为备择假设对应的参数集合。若备择为简单假设 $\theta=\theta_1$,则常写
$$
\beta=P(\text{不拒绝 }H_0\mid \theta=\theta_1).
$$
定义(功效函数)
功效函数为
$$
\pi(\theta)=P(\text{拒绝 }H_0\mid \theta).
$$
关系($\alpha,\beta,\pi$ 的对应)
- 当 $\theta\in\Theta_0$:$\pi(\theta)=P(\text{拒绝 }H_0\mid \theta)$,其上界/指定值就是检验水平(控制第一类错误)。
- 当 $\theta\in\Theta_1$:$\beta(\theta)=1-\pi(\theta)$(第二类错误与功效互补)。
▸解释:为什么必须先定 $\alpha$,再谈 $\beta$
同一组数据下,“更容易拒绝 $H_0$”会同时:
- 增大 $\pi(\theta)$(提高发现效应的能力,降低 $\beta$);
- 也会增大 $P(\text{拒绝 }H_0\mid H_0)$(提高误报,增大 $\alpha$)。
因此检验设计通常先规定可接受的误报率 $\alpha$,再在该约束下尽量降低漏报率 $\beta$(或等价地尽量增大功效)。
设 $X_1,\dots,X_n\stackrel{iid}{\sim}N(\mu,\sigma^2)$,$\sigma$ 已知。检验
$$
H_0:\mu=\mu_0\quad \text{vs}\quad H_1:\mu=\mu_1>\mu_0.
$$
取统计量 $Z=\frac{\overline X-\mu_0}{\sigma/\sqrt{n}}$,选择拒绝域 $W={Z>z_{1-\alpha}}$。
- 第一类错误:
$$
\alpha=P_{\mu_0}(Z>z_{1-\alpha})=\alpha\quad (\text{由分位数定义}).
$$ - 第二类错误(在 $\mu=\mu_1$ 时不拒绝):
$$
\beta=P_{\mu_1}(Z\le z_{1-\alpha}).
$$
注意在 $\mu=\mu_1$ 下,
$$
Z=\frac{\overline X-\mu_0}{\sigma/\sqrt{n}}
=\frac{\overline X-\mu_1}{\sigma/\sqrt{n}}+\frac{\mu_1-\mu_0}{\sigma/\sqrt{n}}
\sim N\left(\frac{\mu_1-\mu_0}{\sigma/\sqrt{n}},,1\right).
$$
因而
$$
\beta=\Phi\left(z_{1-\alpha}-\frac{\mu_1-\mu_0}{\sigma/\sqrt{n}}\right),\qquad
\pi(\mu_1)=1-\beta.
$$
解释:$n$ 越大或效应差 $\mu_1-\mu_0$ 越大,括号里第二项越大,$\beta$ 越小,功效越高;这就是“样本量提升会降低漏报”的定量表达。
定义(p 值)
在 $H_0$ 下,p 值为“观测到同样或更极端统计量”的概率,用于衡量反对 $H_0$ 的证据强度。
Neyman–Pearson 引理与似然比检验
定理(Neyman–Pearson 引理)
Neyman–Pearson lemma
对简单假设 $H_0:\theta=\theta_0$ 与 $H_1:\theta=\theta_1$,在给定水平 $\alpha$ 下,使功效最大(最强检验)的拒绝域由似然比
$$
\Lambda(x)=\frac{f(x;\theta_0)}{f(x;\theta_1)}
$$
构造:当 $\Lambda(x)\le c$ 时拒绝 $H_0$(常数 $c$ 由水平确定)。
▸推导思路(最优化 + 交换论证)
将“在 $H_0$ 下错误率固定”的约束与“在 $H_1$ 下拒绝概率最大”的目标写成积分形式,使用交换论证可得最优拒绝域应按 $\frac{f_1}{f_0}$ 从大到小选取,等价于按 $\Lambda$ 从小到大选取。
方法(似然比检验:复合假设)
Likelihood ratio test (LRT)
对复合假设,定义
$$
\lambda(x)=\frac{\sup_{\theta\in\Theta_0}L(\theta)}{\sup_{\theta\in\Theta}L(\theta)}.
$$
小的 $\lambda(x)$ 倾向拒绝 $H_0$。
正态总体参数检验
(最常用)
 <
<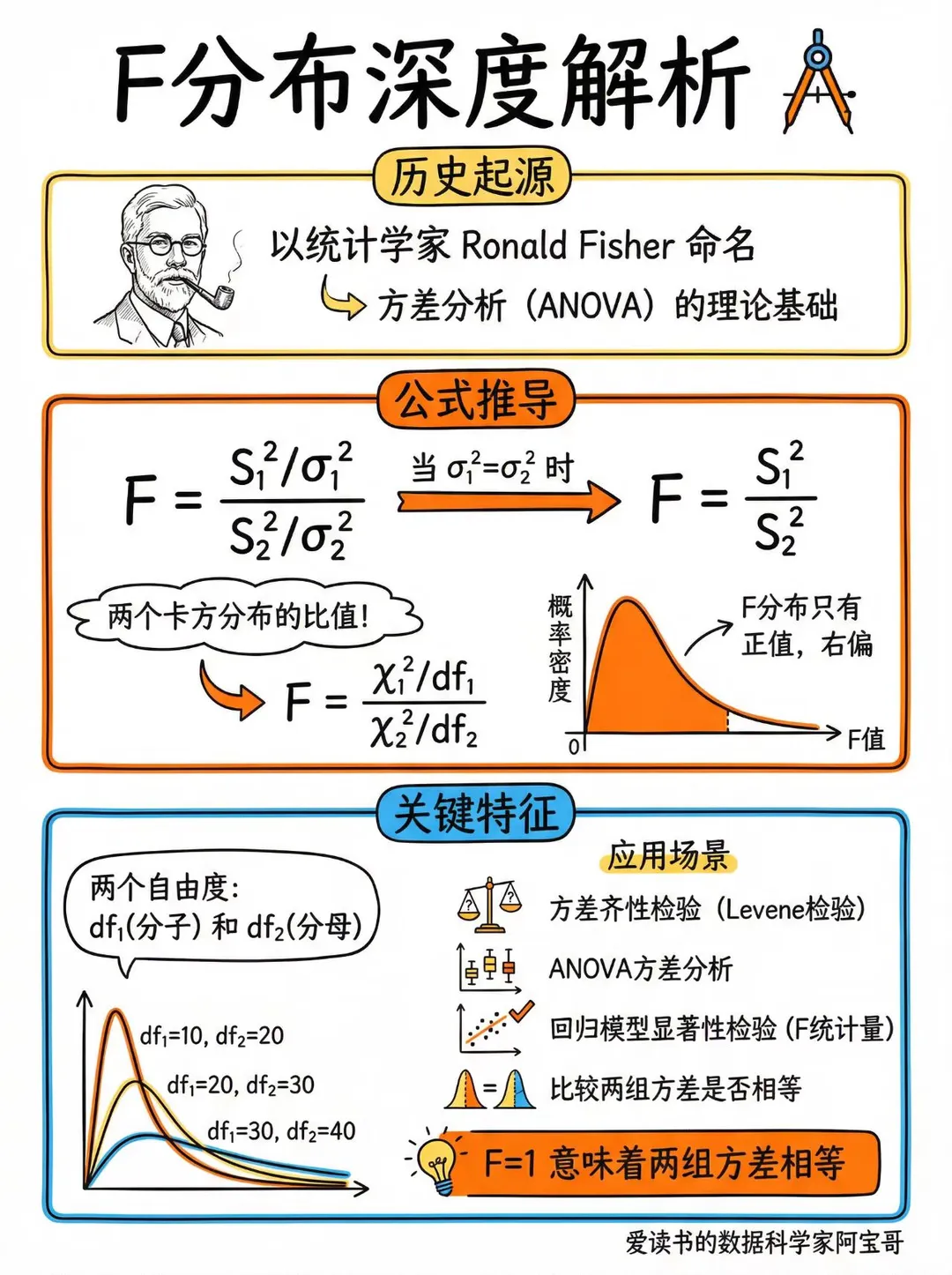
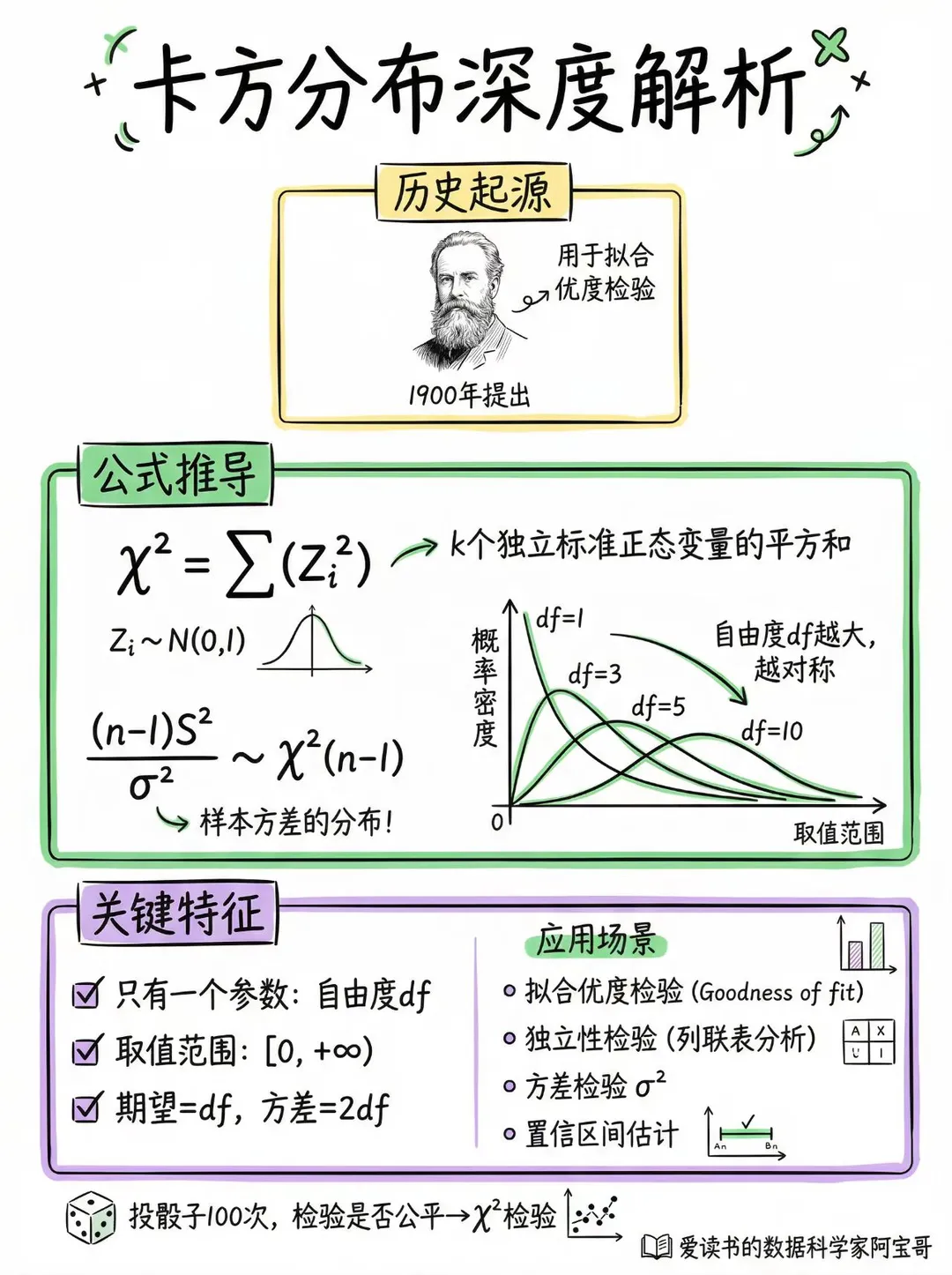
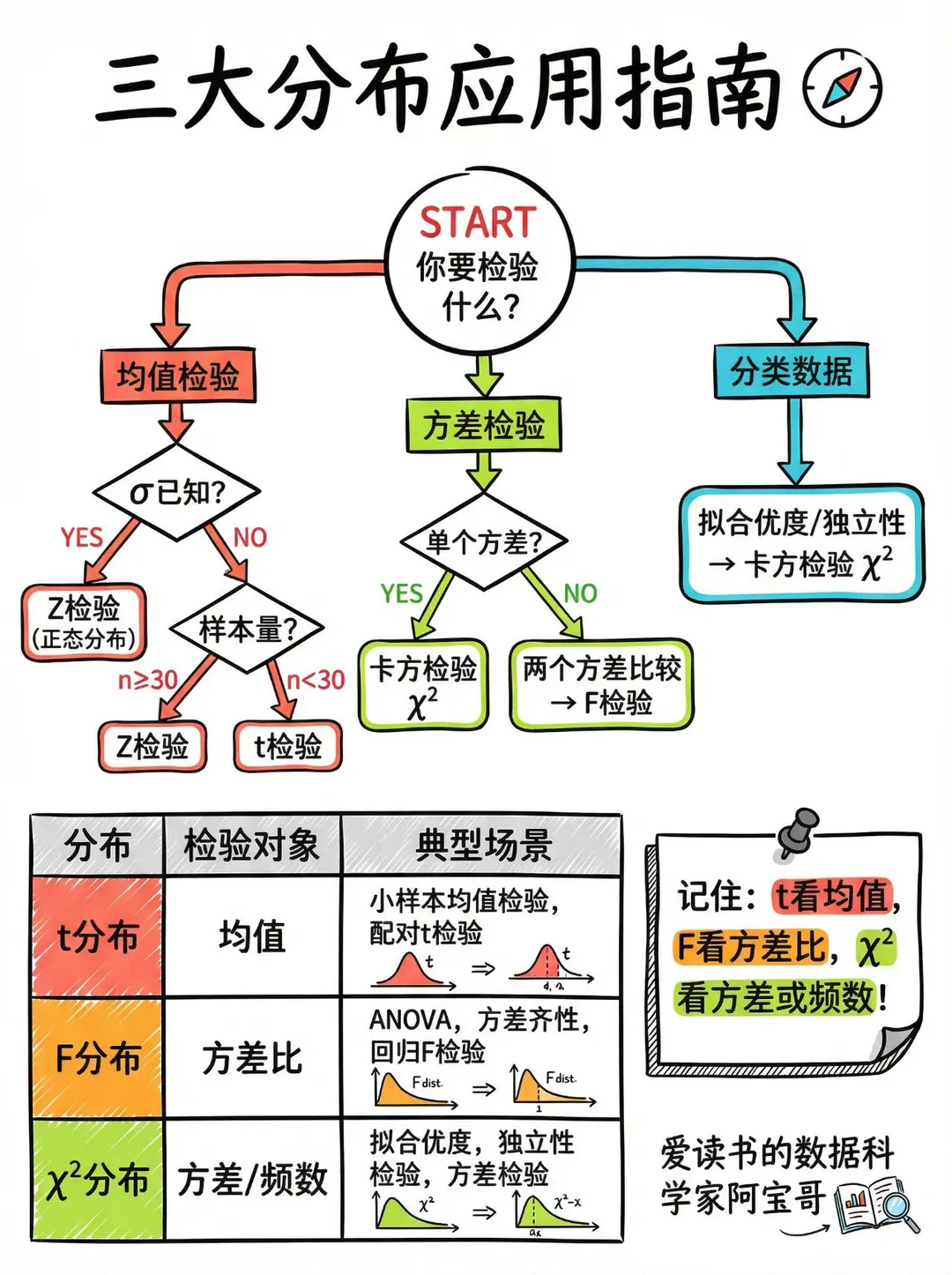
图源右下角水印,小红书@数据科学家阿宝哥
Z 检验
检验(单总体均值:$\sigma^2$ 已知,Z 检验)
Z-test
$$
Z=\frac{\overline X-\mu_0}{\sigma/\sqrt{n}}\sim N(0,1)\ (H_0).
$$
t 检验
检验(单总体均值:$\sigma^2$ 未知,t 检验)
t-test
$$
T=\frac{\overline X-\mu_0}{S/\sqrt{n}}\sim t(n-1)\ (H_0).
$$
$\chi^2$ 检验
卡方检验
检验(单总体方差:$\chi^2$ 检验)
Chi-square test
$$
\chi^2=\frac{(n-1)S^2}{\sigma_0^2}\sim \chi^2(n-1)\ (H_0).
$$
F 检验
检验(两总体方差比:F 检验)
F-test
设两样本方差为 $S_1^2,S_2^2$,则
$$
F=\frac{S_1^2}{S_2^2}\sim F(n_1-1,n_2-1)\ (H_0:\sigma_1^2=\sigma_2^2).
$$
检验 $H_0:\mu=\mu_0$ vs $H_1:\mu>\mu_0$,统计量为
$$
T=\frac{\overline X-\mu_0}{S/\sqrt{n}}.
$$
解释:分子是“与假设均值的偏差”,分母是“标准误差”(波动尺度)。当 $T$ 很大,说明偏差远超随机波动,倾向拒绝 $H_0$。
拟合优度与独立性检验(Pearson 卡方)
Pearson $\chi^2$检验
检验(拟合优度:Pearson $\chi^2$)
Pearson’s chi-square test
设类别 $1,\dots,k$ 的观测频数为 $O_i$,在 $H_0$ 下期望频数为 $E_i=np_i$,则
$$
\chi^2=\sum_{i=1}^{k}\frac{(O_i-E_i)^2}{E_i}\approx \chi^2(k-1-r),
$$
其中 $r$ 为由数据估计的参数个数。
▸推导直观(标准化偏差平方和)
每项 $\frac{O_i-E_i}{\sqrt{E_i}}$ 可视为“以 $\sqrt{E_i}$ 为尺度的偏差”,在大样本下近似正态;平方和近似卡方。
检验(列联表独立性)
若二维列联表观测频数为 $O_{ij}$,在独立性假设下
$$
E_{ij}=\frac{(\text{第 }i\text{ 行和})\cdot(\text{第 }j\text{ 列和})}{n},
$$
统计量
$$
\chi^2=\sum_{i,j}\frac{(O_{ij}-E_{ij})^2}{E_{ij}}.
$$
Kolmogorov–Smirnov 检验
(补充)
检验(K-S 检验:连续分布)
Kolmogorov–Smirnov test
以经验分布函数 $F_n$ 与理论分布 $F_0$ 的最大差异
$$
D_n=\sup_x|F_n(x)-F_0(x)|
$$
构造检验。
七、回归分析与方差分析
▸直观理解(回归 & ANOVA)
- 回归:用“直线/超平面”描述 $x$ 与 $y$ 的平均关系,核心是最小二乘 = 把 $\mathbf{Y}$ 投影到 $\mathrm{span}(\mathbf{X})$ 上。
- 方差分析:比较“组间差异”与“组内波动”,核心是把总波动分解:
$$
\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}.
$$
若组间占比显著更大,用 $F=\mathrm{MSB}/\mathrm{MSW}$ 反对“各组均值相等”。
做题口令:
- 回归:写模型 $\to$ 写 OLS 解(或正规方程)$\to$ 解释系数/残差 $\to$ 做显著性检验。
- ANOVA:算三种平方和 $\to$ 算自由度 $\to$ 算 MS $\to$ 算 $F$ 并查临界值/p 值。
一元线性回归
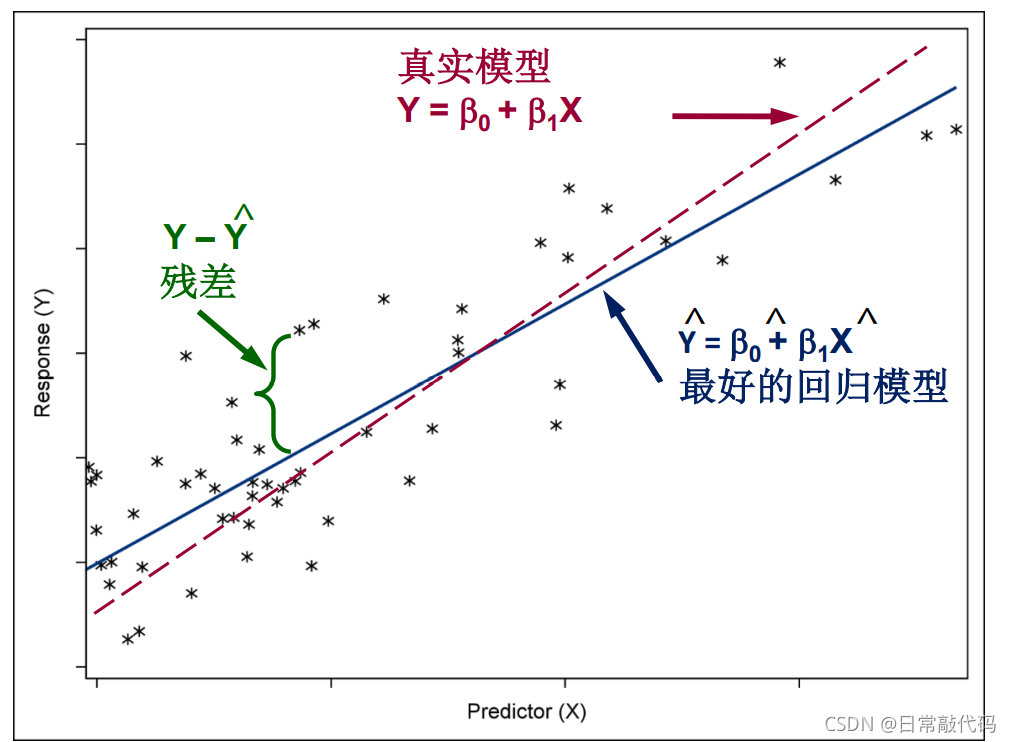
模型(一元线性回归)
$$
Y_i=\beta_0+\beta_1 x_i+\varepsilon_i,\qquad E[\varepsilon_i]=0,\ \mathrm{Var}(\varepsilon_i)=\sigma^2.
$$
方法(最小二乘估计)
Ordinary least squares (OLS)
令残差 $e_i=y_i-(\beta_0+\beta_1 x_i)$,最小化
$$
S(\beta_0,\beta_1)=\sum_{i=1}^{n}e_i^2
$$
得到估计 $\hat\beta_0,\hat\beta_1$。
▸推导(正规方程与显式解)
对 $S$ 分别对 $\beta_0,\beta_1$ 求偏导并令 0:
$$
\frac{\partial S}{\partial \beta_0}=-2\sum (y_i-\beta_0-\beta_1 x_i)=0,
$$
$$
\frac{\partial S}{\partial \beta_1}=-2\sum x_i(y_i-\beta_0-\beta_1 x_i)=0.
$$
解得正规方程:
$$
\sum y_i=n\beta_0+\beta_1\sum x_i,\qquad
\sum x_i y_i=\beta_0\sum x_i+\beta_1\sum x_i^2.
$$
令 $\overline x=\frac1n\sum x_i$,$\overline y=\frac1n\sum y_i$,
记 $S_{xx}=\sum (x_i-\overline x)^2$,$S_{xy}=\sum (x_i-\overline x)(y_i-\overline y)$,则
$$
\hat\beta_1=\frac{S_{xy}}{S_{xx}},\qquad
\hat\beta_0=\overline y-\hat\beta_1\overline x.
$$
结论(残差平方和与方差估计)
$$
\mathrm{SSE}=\sum e_i^2,\qquad
\hat\sigma^2=\frac{\mathrm{SSE}}{n-2}.
$$
结论(决定系数)
$$
R^2=1-\frac{\mathrm{SSE}}{\mathrm{SST}},\qquad \mathrm{SST}=\sum (y_i-\overline y)^2.
$$
$\hat\beta_1$ 近似表示:$x$ 增加 1 单位时,$y$ 的平均变化量。
当 $S_{xx}$ 很小($x$ 几乎不变)时,斜率估计会非常不稳定(分母很小),这也是实验设计里强调“自变量要有足够变化范围”的原因。
多元线性回归(矩阵形式)
模型(多元线性回归)
$$
\mathbf{Y}=\mathbf{X}\boldsymbol{\beta}+\boldsymbol{\varepsilon},
$$
其中 $\mathbf{X}$ 为 $n\times p$ 设计矩阵。
结论(OLS 解)
$$
\hat{\boldsymbol{\beta}}=(\mathbf{X}^\top\mathbf{X})^{-1}\mathbf{X}^\top\mathbf{Y}
$$
(假设 $\mathbf{X}^\top\mathbf{X}$ 可逆)。
▸推导(向量微分/正规方程)
最小化 $||\mathbf{Y}-\mathbf{X}\boldsymbol{\beta}||^2$。
对 $\boldsymbol{\beta}$ 求梯度并令 0:
$$
-2\mathbf{X}^\top(\mathbf{Y}-\mathbf{X}\boldsymbol{\beta})=0
\Rightarrow \mathbf{X}^\top\mathbf{X}\boldsymbol{\beta}=\mathbf{X}^\top\mathbf{Y},
$$
解得结论。
方差分析(ANOVA)
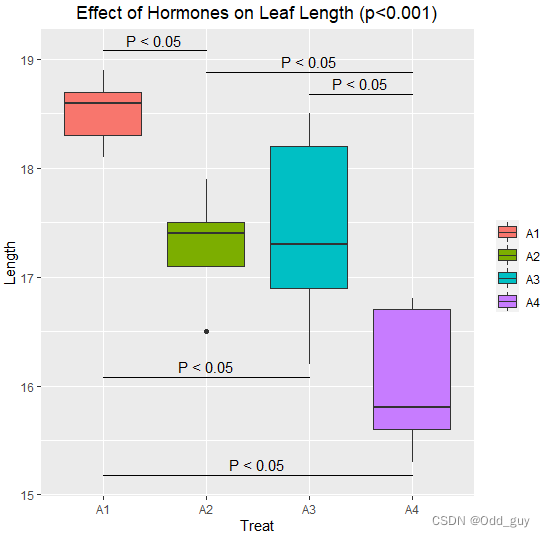
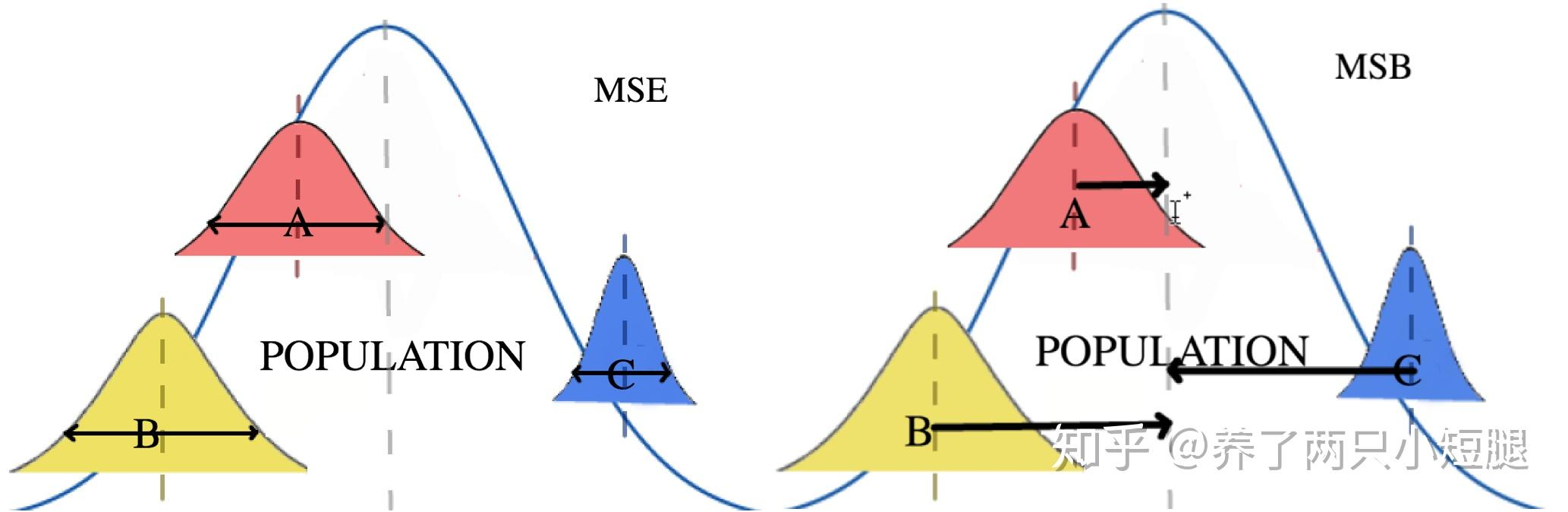
模型(单因素方差分析)
ANOVA (one-way)
$$
Y_{ij}=\mu+\tau_i+\varepsilon_{ij},\qquad \sum_i \tau_i=0.
$$
假设(单因素 ANOVA)
$$
H_0:\ \mu_1=\mu_2=\cdots=\mu_k,\qquad
H_1:\ \text{至少有一组均值不同}.
$$
▸来龙去脉:为什么“比较均值”会变成“比较方差”
若直接做多次两两 $t$ 检验,会把整体第一类错误率累积放大(多重比较问题)。
单因素 ANOVA 的做法是:先把“总体波动”拆成
- 组间波动(between groups):由组均值差异驱动;
- 组内波动(within groups):由随机误差驱动。
若 $H_0$ 为真,组间波动应当与组内噪声同量级;若 $H_1$ 为真,组间波动会显著变大。
结论(平方和分解)
$$
\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}.
$$
定义(平方和)
设第 $i$ 组样本量为 $n_i$,总样本量 $N=\sum_{i=1}^k n_i$;组均值 $\overline Y_{i\cdot}$,总体均值 $\overline Y_{\cdot\cdot}$。则
$$
\mathrm{SST}=\sum_{i=1}^{k}\sum_{j=1}^{n_i}(Y_{ij}-\overline Y_{\cdot\cdot})^2,
$$
$$
\mathrm{SSB}=\sum_{i=1}^{k}n_i(\overline Y_{i\cdot}-\overline Y_{\cdot\cdot})^2,
$$
$$
\mathrm{SSW}=\sum_{i=1}^{k}\sum_{j=1}^{n_i}(Y_{ij}-\overline Y_{i\cdot})^2.
$$
▸推导:$\mathrm{SST}=\mathrm{SSB}+\mathrm{SSW}$
对每个观测值做“加减组均值”的恒等分解:
$$
Y_{ij}-\overline Y_{\cdot\cdot}=(Y_{ij}-\overline Y_{i\cdot})+(\overline Y_{i\cdot}-\overline Y_{\cdot\cdot}).
$$
两边平方并在组内求和:
$$
\sum_{j=1}^{n_i}(Y_{ij}-\overline Y_{\cdot\cdot})^2
=\sum_{j=1}^{n_i}(Y_{ij}-\overline Y_{i\cdot})^2
+2(\overline Y_{i\cdot}-\overline Y_{\cdot\cdot})\sum_{j=1}^{n_i}(Y_{ij}-\overline Y_{i\cdot})
+\sum_{j=1}^{n_i}(\overline Y_{i\cdot}-\overline Y_{\cdot\cdot})^2.
$$
中间项为 0(因为 $\sum_{j}(Y_{ij}-\overline Y_{i\cdot})=0$)。最后一项等于 $n_i(\overline Y_{i\cdot}-\overline Y_{\cdot\cdot})^2$。
再对 $i=1,\dots,k$ 求和即得 $\mathrm{SST}=\mathrm{SSW}+\mathrm{SSB}$。
定义(自由度)
$$
\mathrm{df}_B=k-1,\qquad \mathrm{df}_W=N-k,\qquad \mathrm{df}_T=N-1.
$$
▸解释:自由度从哪里来
- 组间:$k$ 个组均值满足一个约束(加权和等于总体均值),故剩 $k-1$。
- 组内:每组 $n_i$ 个观测值相对组均值的偏差有约束(和为 0),故每组自由度 $n_i-1$,总和为 $\sum (n_i-1)=N-k$。
检验(F 检验)
$$
F=\frac{\mathrm{MSB}}{\mathrm{MSW}},\qquad
\mathrm{MSB}=\frac{\mathrm{SSB}}{k-1},\quad
\mathrm{MSW}=\frac{\mathrm{SSW}}{N-k}.
$$
▸直观(为什么是 F)
方差分析的核心是比较“组间波动”和“组内噪声”。
若各组均值确实相同,组间波动只是噪声放大后的结果,其比值服从 F;若组均值不同,组间波动会显著变大,从而 F 变大。
▸操作步骤(按图走一遍)
- 写假设:$H_0:\mu_1=\cdots=\mu_k$;$H_1$:至少一组不同。
- 算三类平方和:$\mathrm{SST},\mathrm{SSB},\mathrm{SSW}$(并检查分解恒等式)。
- 算自由度:$\mathrm{df}_B,\mathrm{df}_W$,进而 $\mathrm{MSB}=\mathrm{SSB}/\mathrm{df}_B$,$\mathrm{MSW}=\mathrm{SSW}/\mathrm{df}_W$。
- 统计量:$F=\mathrm{MSB}/\mathrm{MSW}$;查 $F_{1-\alpha}(k-1,N-k)$ 或看 p 值。
- 结论:若拒绝 $H_0$,只能说明“至少有一组均值不同”,要回答“哪几组不同”需做事后检验。
前提(常用)
- 组内误差独立:$\varepsilon_{ij}$ 相互独立
- 组内正态:$\varepsilon_{ij}\sim N(0,\sigma^2)$
- 方差齐性:各组误差方差相同(同一个 $\sigma^2$)
ANOVA 的拒绝域对应的是“总体上有没有差异”。即使 $F$ 显著,也不直接告诉“是 A vs B 还是 B vs C”。
事后检验(例如 Tukey HSD)会在控制整体错误率的前提下做组间比较,从而定位差异来源。
多重比较(Tukey HSD)
Tukey’s honestly significant difference
用于在总体差异显著后进一步比较哪几组均值差异显著。
协方差分析(ANCOVA)
Analysis of covariance
在 ANOVA 中加入协变量以控制其影响,再比较组效应。
速查表(常用结论)
▸正态总体抽样分布(速查)
$$
\overline X\sim N\left(\mu,\frac{\sigma^2}{n}\right),\quad
\frac{(n-1)S^2}{\sigma^2}\sim\chi^2(n-1),\quad
\frac{\overline X-\mu}{S/\sqrt{n}}\sim t(n-1).
$$
$$
\frac{S_1^2}{S_2^2}\sim F(n_1-1,n_2-1)\quad (H_0:\sigma_1^2=\sigma_2^2).
$$
▸置信区间(速查)
$$
\mu:\ \sigma^2\text{已知}\Rightarrow \overline X\pm z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}},\qquad
\sigma^2\text{未知}\Rightarrow \overline X\pm t_{1-\alpha/2,n-1}\frac{S}{\sqrt{n}}.
$$
$$
\sigma^2:\ \left[\frac{(n-1)S^2}{\chi^2_{1-\alpha/2,n-1}},\ \frac{(n-1)S^2}{\chi^2_{\alpha/2,n-1}}\right].
$$
▸经典检验统计量(速查)
$$
Z=\frac{\overline X-\mu_0}{\sigma/\sqrt{n}},\quad
T=\frac{\overline X-\mu_0}{S/\sqrt{n}},\quad
\chi^2=\frac{(n-1)S^2}{\sigma_0^2},\quad
F=\frac{S_1^2}{S_2^2}.
$$
$$
\chi^2_{\text{Pearson}}=\sum_{i=1}^{k}\frac{(O_i-E_i)^2}{E_i},\qquad
D_n=\sup_x|F_n(x)-F_0(x)|.
$$
▸回归与方差分析(速查)
$$
\hat\beta_1=\frac{\sum (x_i-\overline x)(y_i-\overline y)}{\sum (x_i-\overline x)^2},\quad
\hat\beta_0=\overline y-\hat\beta_1\overline x,\quad
\hat\sigma^2=\frac{\mathrm{SSE}}{n-2}.
$$
$$
R^2=1-\frac{\mathrm{SSE}}{\mathrm{SST}},\qquad
F_{\text{ANOVA}}=\frac{\mathrm{MSB}}{\mathrm{MSW}}.
$$