


要用这个方法,学一下排除偏见的常用措施。
综述地址: From Generation to Judgment- Opportunities and Challenges of LLM-as-a-judge
背景
传统自动评估指标(如 BLEU、ROUGE、METEOR)依赖 n-gram 重叠,无法捕捉语义质量。后续发展出基于嵌入的方法(如 BERTScore、BARTScore),虽引入上下文语义,但仍受限于固定向量空间的表达能力,难以处理开放域、多属性、主观性强的评估任务。
LLM-as-a-judge 的核心思想是:将大型语言模型本身作为动态、可编程、具备常识与推理能力的评估器。其优势在于:
- 可通过自然语言指令灵活定义评估维度;
- 支持细粒度、多轮、解释性反馈;
- 能处理非结构化输入(如长对话、复杂指令);
- 在缺乏参考文本(reference-free)场景下仍有效。
但该范式并非“即插即用”——其有效性高度依赖提示设计、模型选择、评估协议等技术细节。
输入输出
输入格式
论文明确区分三种主流输入结构,每种对应不同评估目标与实现方式:
Point-wise(单点评估)
- 结构:
[Instruction] + [Context] + [Response] - 用途:适用于绝对评分(如 1–5 分)、属性检测(如是否包含幻觉)
- 示例提示:
1
2
3
4
5请根据以下标准对回答进行评分(1-5分):
- 帮助性:是否解决用户问题?
- 准确性:是否事实正确?
回答:“地球是平的。”
评分: - 技术挑战:缺乏参照物,易受模型自身先验影响;需强约束避免自由发挥。
Pair-wise(成对比较)
- 结构:
[Instruction] + [Context] + [Response A] + [Response B] - 用途:偏好学习、模型选型、A/B 测试
- 典型实现:Chatbot Arena 的匿名竞技场机制即基于此,用户看不到模型身份,仅比较输出优劣。
- 输出控制技巧:
- 强制格式:
{"winner": "A"}或{"preference": "B"} - 位置平衡:交替 A/B 顺序多次评估,取多数投票以消除位置偏差(position bias)
- 强制格式:
List-wise(列表排序)
- 结构:提供 N 个候选响应(N≥3)
- 实现难点:LLM 上下文长度限制;组合爆炸(O(N!) 排序空间)
- 工程优化:
- 两两比较后归并排序(pairwise tournament)
- 使用 CoT(Chain-of-Thought)引导逐步排序:“首先比较 A 和 B,胜者再与 C 比较…”
输出格式控制
为确保结构化输出,常用以下技术:
- JSON Schema 约束(尤其在 GPT-4-Turbo、Claude 3.5 等支持 structured output 的模型中):
1
2
3
4
5{
"helpfulness": 4,
"factuality": 2,
"reason": "声称地球是平的,与科学事实不符"
} - 正则表达式后处理:从自由文本中提取数字或关键词(如“更优的是 Response B” → 提取 “B”)
- 多步验证:先让模型生成理由,再基于理由打分,提升一致性
评估属性
论文指出,不同属性需不同的提示策略与验证机制:
幻觉检测(Hallucination Detection)
- 方法:Halu-J(Wang et al., 2024a)提出“批判式判断”框架:
- Step 1:要求 judge 识别响应中所有可验证声明(verifiable claims)
- Step 2:对每个声明判断是否可由上下文或常识支持
- Step 3:汇总幻觉比例作为最终分数
- 技术细节:
- 使用 self-consistency 投票:多次采样判断结果,取众数
- 引入外部工具(如搜索引擎 API)辅助验证(但增加延迟)
逻辑一致性(Logical Consistency)
- 挑战:LLM 易被表面流畅性迷惑,忽略推理漏洞
- 解决方案:Andreas Stephan et al. (2024) 在数学推理任务中采用“反向验证”:
- 要求 judge 从结论反推前提是否成立
- 若存在不可逆步骤(如除以零、未考虑边界条件),则判为不一致
- 提示模板:
1
2
3给定证明过程,请检查每一步是否逻辑严密。特别注意:
- 是否所有变量定义明确?
- 是否每一步均可逆或有依据?
公平性评估(Fairness)
- 问题:LLM 本身存在社会偏见(Wang et al., 2023d)
- 缓解策略:
- 对抗去偏提示:在指令中显式要求“忽略姓名、性别、国籍等无关信息”
- 反事实测试:对同一内容生成多个版本(仅改变敏感属性),若评分差异显著(p<0.05),则判定存在偏见
- 集成多个 judge:使用不同训练数据来源的 LLM(如 Llama 3 vs. Mistral vs. GPT-4)投票,降低单一模型偏见
关键技术实现
监督微调(SFT)构建专用 Judge 模型
- 数据来源:
- 人工标注:如 LMSYS 的 Chatbot Arena 人类偏好数据(>500k 对话对)
- 合成数据:用 GPT-4 为开源模型输出打标,再微调较小模型(如 Mistral-7B)作为低成本 judge
- 损失函数:
- 分类任务:交叉熵(如 5 分制)
- 排序任务:Pairwise Ranking Loss(如 BPR, Bayesian Personalized Ranking)
- 架构适配:
- 对于 decoder-only 模型(如 Llama),在 response 末尾添加特殊 token
<|score_4|>,训练时预测该 token - 对于 encoder-decoder(如 T5),将评分作为目标序列生成
- 对于 decoder-only 模型(如 Llama),在 response 末尾添加特殊 token
偏好学习与 Direct Preference Optimization (DPO)
- 传统 RLHF 流程:
- SFT 阶段:训练 policy model
- Reward Modeling:用 pair-wise 数据训练 reward model(RM)
- PPO:用 RM 作为奖励信号优化 policy
- DPO 替代方案(Wang et al., 2024e):
- 直接从偏好数据中优化 policy,绕过显式 reward model
- 公式:最大化 $\log \sigma(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_\theta(y_l|x)} - \log \frac{\pi_{\text{ref}}(y_w|x)}{\pi_{\text{ref}}(y_l|x)})$
- 优势:训练更稳定,无需 reward modeling 阶段
- 与 judge 关系:DPO 中的 preference data 通常由 LLM-as-a-judge 生成
多智能体辩论式评估(Debate-based Judgment)
- 流程(Boshi Wang et al., 2023a):
- Agent A 生成回答
- Agent B 扮演“批评者”,指出漏洞
- Agent A 辩护或修正
- 第三方 judge(Agent C)基于辩论过程打分
- 技术要点:
- 角色提示需明确:“你是一名严谨的事实核查员,必须质疑每一个未经证实的主张”
- 设置最大轮次(如 3 轮)防止无限循环
- 最终评分基于“是否成功回应所有质疑”
Many-shot In-context Learning for Long-context Judges
- 问题:短上下文 judge 在评估长文本(如 10k token 报告)时遗漏关键信息
- 解决方案(Song et al., 2024b):
- 在提示中注入多个高质量评估示例(many-shot,如 10+ examples)
- 示例覆盖不同错误类型(事实错误、逻辑跳跃、冗余等)
- 实验表明:8-shot 比 0-shot 在 BioRAG 等长文档 QA 任务上 Spearman 相关性提升 0.21
基准测试
JudgeBench(Tan et al., 2024b)
- 组成:
- 12 个子任务,涵盖摘要、对话、代码、数学等
- 每个任务提供 human-labeled golden judgments
- 包含对抗样本(如故意插入矛盾句)
- 评估指标:
- Alignment Score:judge 与人类评分的 Spearman ρ
- Bias Score:在反事实对上的评分方差
- Robustness Score:对 paraphrased inputs 的评分一致性(用 ParaphraseScore 衡量)
FLASK(Fine-grained Language Skill Assessment)
- 特点:将整体质量分解为 10+ 细粒度技能(如 coherence, conciseness, informativeness)
- 实现:每个技能单独 prompt,强制模型聚焦单一维度
- 验证方式:与专家标注的 skill-level scores 计算 MAE(Mean Absolute Error)
ProxyQA(Tan et al., 2024a)
- 创新点:不直接评估长文本,而是生成一系列 yes/no 问题(proxy questions),再评估回答这些问题的能力
- 优势:将开放式评估转化为可验证的闭合任务
- 示例:
- 原始输出:“光合作用发生在叶绿体中…”
- Proxy Q1:“光合作用是否发生在线粒体?” → 正确回答应为 “No”
- Judge 评估模型对 proxy Q 的回答准确性
核心技术挑战的深层分析
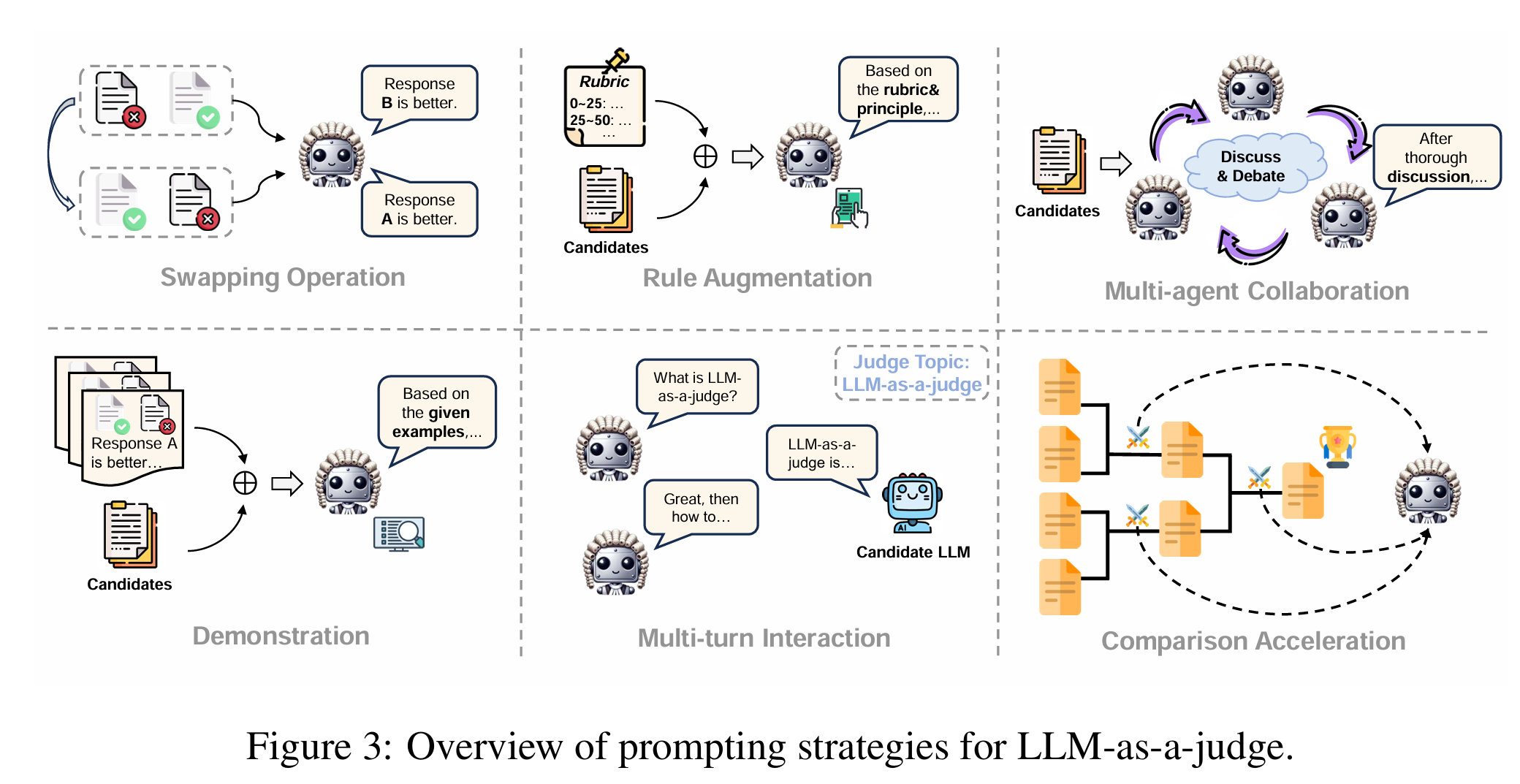
位置偏差(Position Bias)
- 现象:在 pair-wise 评估中,LLM 倾向于选择第一个或第二个选项(取决于训练数据分布)
- 量化:在 JudgeBench 中,GPT-4 对 A/B 顺序交换后的偏好反转率仅 68%,远低于理想 100%
- 缓解:
- Double-blind evaluation:随机打乱顺序,多次评估取平均
- Position-aware prompting:“请忽略 Response A 和 B 的出现顺序,仅基于内容判断”
自我增强偏见(Self-enhancement Bias)
- 问题:当用 LLM 评估同家族模型(如 GPT-4 评 GPT-3.5),可能因风格相似而高估
- 实验证据:Wang et al. (2023c) 发现 ChatGPT 在评估自身生成 vs. 人类写作文本时,对自身输出评分高 0.8 分(5 分制)
- 对策:
- 使用异构 judge(如用 Claude 评 GPT,用 Llama 评 Mistral)
- 引入 calibration set:用已知质量的 anchor responses 校准评分尺度
幻觉在 judge 自身中的传播
- 风险:judge 在解释评分理由时可能编造不存在的错误
- 检测方法:
- Self-verification:要求 judge 列出具体错误位置(如“第3句‘地球是平的’错误”),再人工验证是否属实
- Fact-checking integration:将 judge 的 claim 送入 fact-checking pipeline(如 Google Fact Check Tools API)
总结:技术落地的关键考量
LLM-as-a-judge 并非万能评估工具,其有效部署需综合考虑:
- Prompt Engineering:必须针对属性、任务、模型能力精细设计,避免模糊指令
- Output Structuring:强制 JSON 或固定格式,便于程序化解析
- Bias Mitigation:通过反事实测试、多模型集成、位置平衡等手段控制系统性误差
- Cost-Quality Tradeoff:GPT-4 作为 judge 虽强但贵,可蒸馏为小模型(如 Phi-3-Judge)用于生产环境
- Human-in-the-loop:关键场景(如医疗、法律)仍需人工复核 judge 的高风险判断
未来工作应聚焦于可验证、可校准、可解释的 judge 架构,而非单纯追求与人类评分的相关性。真正的“good judge”不仅打分准,还能指出“为什么错”、“如何改”,从而闭环驱动生成模型进化。