


综述地址:
此方向是直接面向未来的、关于从AGI到ASI的研究的组成部分,值得探索。
正在开启相关项目,先进行初步整理。
“It is not the most intellectual of the species that survives; it is not the strongest that survives; but the species that survives is the one that is able best to adapt and adjust to the changing environment in which it finds itself.”
—— Charles Darwin
背景
当前主流大型语言模型(Large Language Models, LLMs)在完成预训练和指令微调(Instruction Tuning)后即进入“冻结”状态(frozen state),其行为完全由输入提示(prompt)驱动。这种静态部署范式(static deployment paradigm)虽在封闭任务上表现优异,但在开放、动态、长期交互环境中暴露出根本性局限:
- 知识固化(Knowledge Staleness):无法吸收新事实(如 2025 年 FDA 批准的新药名称),导致回答过时;
- 策略僵化(Strategy Rigidity):面对结构新颖的任务(如多跳工具调用链、跨域推理)缺乏适应能力;
- 错误不可逆(Error Irreversibility):一旦推理路径偏离,无法在后续步骤中自我纠正或从失败中学习。
为突破上述瓶颈,研究者提出 Self-Evolving Agents(自进化智能体) ——一种能在部署后持续优化自身能力的系统。其核心理念并非“一次训练、终身使用”,而是“终身学习、动态演化”(lifelong learning with dynamic evolution)。这类智能体不仅响应环境,更能主动改造自身内部结构以提升未来性能。
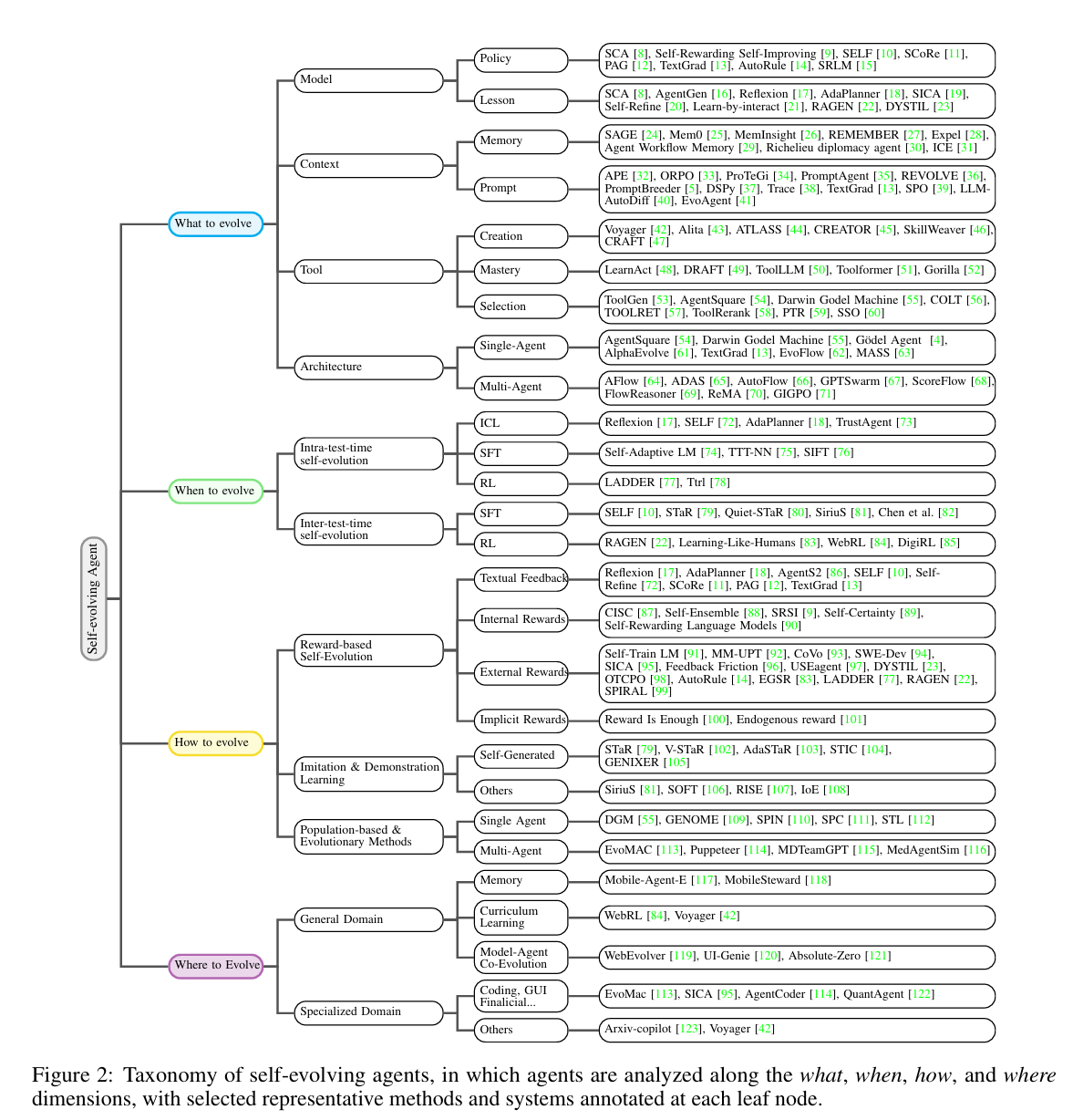
概念
自进化智能体标志着 AI 从 静态模型 向 动态生命体 的范式转变。其核心在于:
- 多组件协同演化(model + context + tool + architecture);
- 主动环境交互与自我反思;
- 无需人工干预的终身学习能力。
形式化定义
论文首先将智能体系统的环境(包括用户和执行环境,如 Linux shell)定义为 部分可观测马尔可夫决策过程
(Partially Observable Markov Decision Process, POMDP),表示为元组:
$$
E = (G, S, A, T, R, \Omega, O, \gamma)
$$
其中各要素定义如下:
- $ G $:潜在目标集合(set of potential goals)。每个 $ g \in G $ 是智能体需要完成的任务目标,例如用户查询(user query);
- $ S $:状态集合(set of states)。每个 $ s \in S $ 表示环境的内部状态(internal state of the environment);
- $ A $:动作集合(set of actions)。每个动作 $ a \in A $ 可以是文本推理(textual reasoning)、外部知识检索(retrieval of external knowledge)和工具调用(tool calls)的组合;
- $ T $:状态转移概率函数(state transition probability function),输入状态-动作对 $ (s, a) $,输出下一个状态的概率分布 $ T(s’|s, a) $;
- $ R $:反馈/奖励函数(feedback/reward function),条件于特定目标 $ g \in G $。反馈 $ r = R(s, a, g) $ 通常采用标量分数(scalar score)或文本反馈(textual feedback)的形式。函数签名为 $ R: S \times A \times G \rightarrow \mathbb{R} $;
- $ \Omega $:观测集合(set of observations),智能体可访问的观测集合;
- $ O $:观测概率函数(observation probability function),输入状态-动作对 $ (s, a) $,输出下一个观测的概率分布 $ O(o’|s, a) $;
- $ \gamma $:折扣因子(discount factor)。
【理解】该公式将智能体与环境的交互建模为 POMDP,核心机制如下:整个过程形成”观测 $ o \in \Omega $ → 推断状态 $ s \in S $ → 选择动作 $ a \in A $ → 状态转移 $ T $ → 获得反馈 $ R $ → 更新观测 $ O $”的完整循环。环境具有真实状态空间 $ S $(智能体无法直接看到),智能体只能通过观测空间 $ \Omega $ 间接感知环境,观测概率函数 $ O(o’|s, a) $ 决定了在状态 $ s $ 和执行动作 $ a $ 后观测到 $ o’ $ 的概率,体现了”部分可观测”特性;智能体执行动作 $ a \in A $(文本推理、知识检索、工具调用的组合)后,状态转移函数 $ T(s’|s, a) $ 决定环境如何从状态 $ s $ 转移到 $ s’ $;反馈函数 $ R(s, a, g) $ 根据当前状态 $ s $、执行的动作 $ a $ 和目标任务目标 $ g \in G $ 给出反馈 $ r $(标量分数或文本反馈);折扣因子 $ \gamma $ 用于权衡即时奖励与长期回报。
▸为什么智能体环境需要用 POMDP?
在真实环境中,智能体通常无法完全观测:
- 网页导航:看到 DOM 结构(观测),但不知道后端数据是否已更新(状态)
- 代码执行:看到输出(观测),但不知道内存中的完整状态(状态)
- 用户交互:看到用户输入(观测),但不知道用户的真实意图或上下文(状态)
与完全可观测 MDP 的区别
- 完全可观测 MDP:智能体直接知道状态 $s$,决策更简单
- POMDP:智能体只能看到观测 $o$,需要:通过观测概率函数 $O(o|s)$ 推断可能的状态、维护对状态的信念belief state)、基于历史观测序列做决策
在此框架下,智能体系统被形式化为四元组:
$$
\Pi = (\Gamma, \lbrace\psi_i\rbrace, \lbrace C_i\rbrace, \lbrace W_i\rbrace)
$$
- $ \Gamma $:架构组件(Architecture),决定智能体系统的控制流或协作结构,通常表示为节点序列($N_1, N_2, \ldots$),可通过图结构或代码结构组织;
- $ \lbrace\psi_i\rbrace $:模型组件集合(Model),即底层 LLM/MLLM 集合(如 Llama-3、Qwen-Max);
- $ \lbrace C_i\rbrace $:上下文信息集合(Context),包含 prompt $P_i$ 和记忆 $M_i$ 等;
- $ \lbrace W_i\rbrace $:工具/API 集合(Tool),即可供调用的外部功能集合(如搜索引擎、代码解释器、数据库接口)。
【理解】该公式定义了自进化的核心机制:变换函数 $ f $ 以当前智能体系统 $ \Pi = (\Gamma, \lbrace\psi_i\rbrace, \lbrace C_i\rbrace, \lbrace W_i\rbrace) $ 为输入,结合任务执行过程中的轨迹 $ \tau = (o_0, a_0, o_1, a_1, \ldots) $(记录了”观测到什么、做了什么”的完整序列)和反馈 $ r $(记录了”效果如何”,可来自外部环境奖励或内部评估信号),输出演化后的新系统 $ \Pi’ = (\Gamma’, \lbrace\psi’_i\rbrace, \lbrace C’_i\rbrace, \lbrace W’_i\rbrace) $。四个组件同时演化:架构 $ \Gamma \rightarrow \Gamma’ $(调整节点拓扑或数据流)、模型 $ \lbrace\psi_i\rbrace \rightarrow \lbrace\psi’_i\rbrace $(更新参数或切换模型)、上下文 $ \lbrace C_i\rbrace \rightarrow \lbrace C’_i\rbrace $(优化 prompt 或更新记忆)、工具 $ \lbrace W_i\rbrace \rightarrow \lbrace W’_i\rbrace $(添加新工具或改进现有工具),实现”从经验中学习并自我改进”。
每个节点 $N_i$ 包含三个组件:底层模型 $ \psi_i $、上下文信息 $ C_i $、可用工具集合 $ W_i $。
智能体策略:在每个节点 $N_i$ 处,智能体策略是一个函数 $ \pi_{\theta_i}(\cdot|o) $,它以观测 $ o $ 为输入,输出下一个动作的概率分布。策略参数 $ \theta_i = (\psi_i, C_i) $,动作空间是自然语言空间与工具空间 $ W_i $ 的并集。
任务表示:给定任务 $ T = (E, g) $,其中 $ E $ 表示环境,$ g \in \mathcal{G} $ 表示对应的目标。智能体系统遵循拓扑结构 $ \Gamma $ 生成轨迹 $ \tau = (o_0, a_0, o_1, a_1, \ldots) $,并在任务执行过程中接收反馈 $ r $。反馈 $ r $ 可来自外部环境或内部信号(如自信度或评估器的反馈)。
自进化策略(Self-evolving strategy):自进化策略是一个变换 $ f $,它将当前智能体系统映射到新状态,条件为生成的轨迹 $ \tau $ 和外部/内部反馈 $ r $:
$$
f(\Pi, \tau, r) = \Pi’ = (\Gamma’, \lbrace\psi’_i\rbrace, \lbrace C’_i\rbrace, \lbrace W’_i\rbrace)
$$
自进化智能体的目标:设 $ U $ 是一个效用函数,通过分配标量分数 $ U(\Pi, \mathcal{T}) \in \mathbb{R} $ 来衡量智能体系统 $ \Pi $ 在给定任务 $ \mathcal{T} $ 上的性能。效用可能来自任务特定的反馈 $ r $(如奖励信号或文本评估),也可能结合其他性能指标(如完成时间、准确性或鲁棒性)。
给定任务序列 $(\mathcal{T}_0, \mathcal{T}_1, \ldots, \mathcal{T}_n)$ 和初始智能体系统 $\Pi_0$,自进化策略 $f$ 递归地生成演化序列 $(\Pi_1, \Pi_2, \ldots, \Pi_n)$ :
$$
\Pi_{j+1} = f(\Pi_j, \tau_j, r_j)
$$
其中 $\tau_j$ 和 $r_j$ 分别是任务 $\mathcal{T}_j$ 上的轨迹和反馈。
设计自进化智能体的总体目标是构造策略 $ f $,使得跨任务的累计效用最大化:
$$
\max_f \sum_{j=0}^n U(\Pi_j, \mathcal{T}_j)
$$
该公式揭示了自进化智能体的本质:通过策略 $ f $ 对智能体系统 $ \Pi $ 的四个组件(架构 $ \Gamma $、模型 $ \lbrace\psi_i\rbrace $、上下文 $ \lbrace C_i\rbrace $、工具 $ \lbrace W_i\rbrace $)进行迭代优化,以实现跨任务性能的持续提升。
对比其他范式
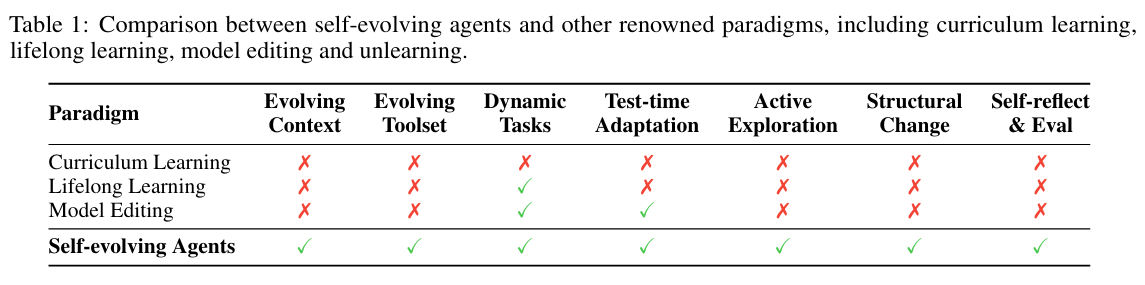
关键区别:自进化智能体是唯一同时具备 结构性自修改能力(structural self-modification)、主动环境交互(active exploration) 和 多组件协同演化(multi-component co-evolution) 的范式。其他方法仅在单一维度上改进,无法实现系统级适应。
核心维度:What / When / How / Where
为系统理解自进化机制,论文提出四维分析框架(Four-Dimensional Framework),分别对应“演化什么”、“何时演化”、“如何演化”、“在何场景演化”。
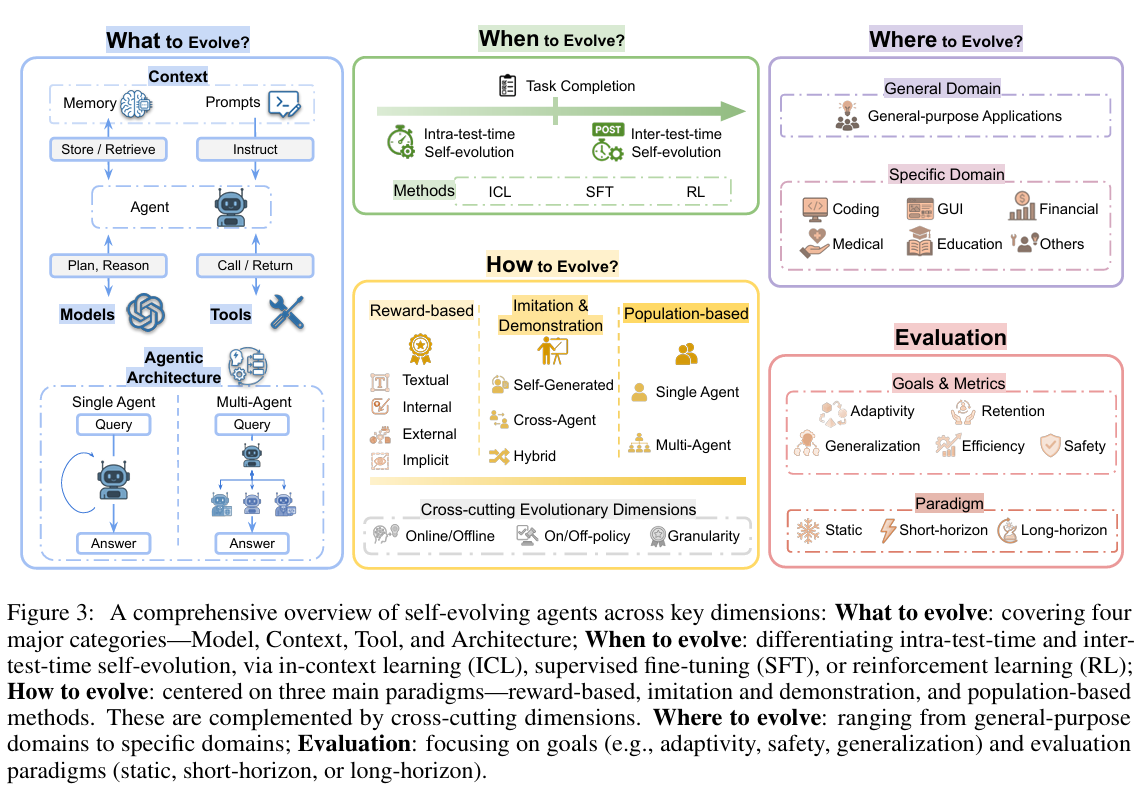
What to Evolve(演化对象)
自进化智能体可对以下四个核心组件进行修改:
Model(模型参数)
- 机制:
- 监督微调(Supervised Fine-Tuning, SFT):利用 self-generated 成功轨迹作为训练数据。
- 例:SCA(Self-Challenging Agent)让 LLM 生成 Code-as-Task 问题(如”实现快速排序”)→ 执行代码 → 验证输出正确性 → 保留成功样本 → 微调模型。此过程形成闭环,使模型在编程能力上持续提升。
- 强化学习(Reinforcement Learning, RL):以任务完成度为 reward,通过策略梯度方法(如 PPO)更新 policy。
- 例:RAGen(Reinforcement Learning for Agent Generation)在 multi-turn 对话环境中使用 PPO 优化 agent 的 action selection policy,同时联合优化 memory retrieval 策略。
- 监督微调(Supervised Fine-Tuning, SFT):利用 self-generated 成功轨迹作为训练数据。
- 挑战:计算成本高、需高质量 reward signal、易受 reward hacking 影响。
Context(上下文)
上下文包含 Prompt 与 Memory,是无需修改模型即可实现快速适应的关键。
Prompt Optimization(提示优化):
- SPO(Self-supervised Prompt Optimization):LLM 自动生成 instruction-response 对,通过 self-preference 比较(如”哪个回答更简洁?”)优化 prompt 模板。
- PromptAgent:将 prompt 优化视为 planning 问题,使用 Monte Carlo Tree Search(MCTS)搜索最优 prompt 序列(如”先 plan 再 act” vs “边做边想”)。
- TextGrad:将 prompt 视为可微变量,通过”文本梯度”反向传播误差。例如,若输出被评价为”太冗长”,则自动在 prompt 中加入”concise”或”limit to 3 sentences”等约束。
Memory Evolution(记忆演化):
- 短期记忆(Short-term Memory):上下文窗口内的 token 缓存,支持 ADD/UPDATE/DELETE 操作。
- Mem0:构建 production-ready 的向量数据库存储 episodic memory(如”用户昨天问过糖尿病用药”),支持基于语义相似度的检索。
- 长期记忆(Long-term Memory):结构化知识图谱或摘要库,用于跨会话知识积累。
- Agent Workflow Memory:记录 multi-turn interaction 中的 workflow state(如 tool call history、subgoal status、失败原因),并在 future task 中复用。例如,若上次因”未登录”失败,则下次自动插入 login 步骤。
- 动态剪枝(Dynamic Pruning):基于遗忘曲线(forgetting curve)或 utility score(如访问频率、任务相关性)删除低价值记忆,防止 memory bloat。
- 短期记忆(Short-term Memory):上下文窗口内的 token 缓存,支持 ADD/UPDATE/DELETE 操作。
Tool(工具)
工具是智能体与外部世界交互的桥梁,其演化包括创建、掌握与选择。
Tool Creation(工具创建):
- Voyager:在《我的世界》(Minecraft)中自主发明新工具(如自动采矿脚本),通过”生成代码 → 执行 → 验证效果 → 保存成功脚本”闭环实现 open-ended invention。
- CREATOR:区分 abstract reasoning(高层规划)与 concrete reasoning(底层执行),自动生成专用工具函数(如”calculate_tax(income)”)。
- CRAFT:构建 specialized toolset,通过 retrieval-augmented generation 动态组合基础工具(如”search + summarize + translate”)。
Tool Mastery(工具掌握):
- LearnAct:通过分析 API 错误返回(如 HTTP 400 Bad Request),迭代优化 tool usage documentation(如修正参数格式)。
- DRAFT(Dynamic Retrieval and Feedback Tool):self-driven interaction with tools → build internal model of tool behavior(如”该 API 响应延迟高,需加 retry 机制”)。
Tool Selection & Retrieval(工具选择与检索):
- ToolGen:将工具编码为 semantic tokens,统一进行 retrieval 与 calling via generation(即”生成工具名”而非”选择工具名”)。
- ATLASS(Autonomous Tool Learning and Selection System):closed-loop framework where LLM selects tools based on task decomposition and past success rate.
Architecture(架构)
架构指智能体内部模块的组织方式,其演化涉及单智能体流程优化与多智能体协作拓扑调整。
单智能体架构优化:
- TextGrad:将 workflow 中每个节点(如 “plan”, “act”, “reflect”)视为可优化模块,通过 textual feedback 反向调整节点 prompt(如将”plan”改为”generate three alternative plans and select the best”)。
- AlphaEvolve:使用 evolutionary algorithm 搜索最优 node composition(如是否需要 separate verifier module)。
多智能体架构优化:
- ReMA(Role-Evolving Multi-Agent):通过群体强化学习协调”thinker”与”executor”角色,动态调整通信拓扑(如 thinker 直接向 executor 发送 refined plan)。
- Multi-Agent Design:搜索 multi-agent collaboration graph(谁与谁通信)以最大化 team performance(如在医疗诊断中,symptom-analyzer 与 drug-recommender 需高频交互)。
- Agentsquare:automatic agent search in modular design space(如从 planner/retriever/executor 模块库中自动组合最优 agent)。
【理解】传统 AI 系统仅更新模型参数;而自进化智能体实现了 四维协同演化(model + context + tool + architecture),从而获得更强的适应性与泛化能力。
When to Evolve(演化时机)
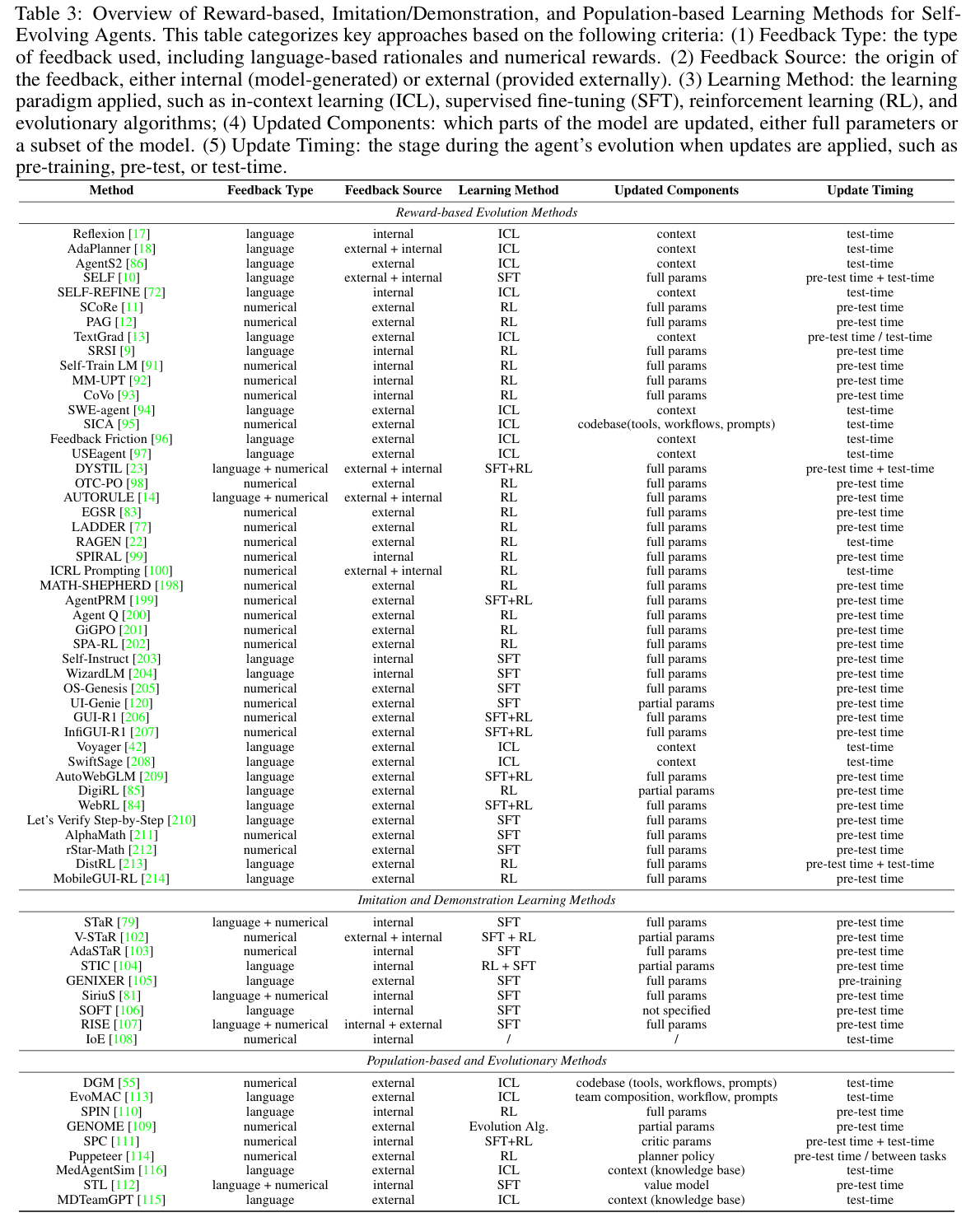
演化可在两个时间尺度发生:
Intra-test-time Evolution(测试时演化)
- 定义:在单次任务执行过程中实时调整,不涉及模型参数更新。
- 技术:
- AdaPlanner:根据环境反馈动态切换 planning mode(如从 BFS 切换到 heuristic search,当发现状态空间过大时)。
- Self-Refine:generate → critique → refine 循环,最多迭代 N 次。例如,初始回答”巴黎是法国首都” → critique:”未说明埃菲尔铁塔位置” → refine:”巴黎是法国首都,埃菲尔铁塔位于其市中心”。
- LADDER(Learning by Adapting During Deployment with Examples and Reflection):当遇到难题时,自动生成变体问题集,通过 test-time RL 快速适应(如调整 temperature 或 top-p)。
- 特点:低延迟、高灵活性,适用于 online 场景。
Inter-test-time Evolution(测试间演化)
- 定义:跨任务间积累经验并更新系统,通常涉及离线训练。
- 技术:
- Expel(Experiential Prompting for Lifelong Learning):将 past experiences 存入 memory bank,新任务中检索相似案例用于 in-context learning(ICL)。
- AgentGen:生成 synthetic environments(PDDL/Gym 格式),构建 curriculum for offline training(如从简单导航到复杂多目标规划)。
- STaR(Self-Taught Reasoner):将失败轨迹中的 self-generated explanations(如“我忽略了边界条件”)转化为训练数据,用于 SFT。
- 特点:性能提升显著,但需计算资源与时间,适用于 offline 场景。
【理解】Intra-test-time 演化提供 immediate adaptation,而 inter-test-time 演化实现 long-term capability growth。二者常结合使用,形成“在线微调 + 离线精炼”的混合范式。
How to Evolve(演化机制)
演化机制可分为三类:
Reward-Based Evolution(基于奖励的演化)
奖励信号的设计是自进化智能体的核心,决定了学习过程的性质、效率和有效性。按奖励来源分为以下四类:
Textual Feedback(文本反馈)
- 利用 LLM 的天然模态——自然语言,提供详细、可解释的改进指令。与标量奖励不同,文本反馈包含细粒度的批评和可操作的建议。
- Reflexion:提出”语言强化学习”(verbal reinforcement learning),智能体用自然语言反思过去的尝试,将这些反思存储为情景记忆以指导未来决策。
- AdaPlanner:通过允许 LLM 智能体根据计划内和计划外反馈修订计划,实现闭环自适应规划,同时通过代码风格提示缓解幻觉,并利用技能发现。
- Self-Refine 和 SELF:探索迭代自反馈和自纠正,证明即使是最先进的模型也可以通过多轮、基于语言的自我批评得到改进,无需额外的监督数据或外部强化。
- TextGrad:将 prompt 视为可微变量,通过”文本梯度”反向传播误差。
- 其他工作:AgentS2、SCoRe、PAG 等。
Internal Rewards(内部奖励)
- 利用模型内部的概率估计或确定性等内部指标,而非外部信号。这种方法利用模型的内在理解来指导改进,无需依赖外部监督。
- CISC(Confidence-Informed Self-Consistency):通过置信度分数对推理路径加权,提高准确性和计算效率,有效从多个候选中过滤高质量解决方案。
- Self-Ensemble:通过将选择分为更小、更易管理的组并聚合预测,缓解置信度失真,减少过度自信偏差。
- Self-Rewarding Language Models:证明模型可以作为自己的奖励函数,通过自指令和自评估循环生成训练数据。
- 其他工作:Self-Rewarding Self-Improving、scalable best-of-N selection via self-certainty 等。
External Rewards(外部奖励)
- 来自模型外部的奖励,如环境、多数投票或显式规则。
- Majority Voting:使用多个模型输出的一致性作为正确性的代理,提供自生成但基于共识的奖励信号。
- Environment Feedback:包括基于工具的信号,是智能体 LLM 研究的核心(如 SWE-Dev、SICA、Feedback Friction、USEagent、DYSTIL),智能体通过与真实世界环境和工具的直接交互学习。
- Rule-based Rewards:使用显式约束或逻辑规则作为可验证信号,在数学推理、游戏和结构化问题解决领域特别有效。
Implicit Rewards(隐式奖励)
- 假设 LLM 可以从即使未明确标记为奖励的反馈信号中学习。
- Reward Is Enough:证明 LLM 可以使用嵌入在上下文窗口中的简单标量信号执行上下文内强化学习,在无需显式 RL 微调或监督的情况下改进响应。
- Endogenous Reward:揭示标准的下一个 token 预测隐式学习了一个通用奖励函数,可以从模型 logits 中提取而无需额外训练。
- PIT(ImPlicit Self-ImprovemenT):通过最大化以参考响应为条件的响应质量差距,从人类偏好数据中隐式学习改进目标,无需额外人工努力。
按奖励粒度分为以下三类(后面还会提到):
Outcome-Based Reward(结果导向奖励)
- 仅在 episode 结束时获得稀疏奖励。
- AutoWebGLM:使用预训练 reward model 判断最终网页是否满足 query(如”找到 iPhone 16 价格” → 检查页面是否含价格信息)。
- DigiRL:Vision-Language Model(VLM)作为 evaluator,输入 (instruction, final screenshot) → 输出 success/failure。
- WebRL:提出 ORM(Outcome-Supervised Reward Model),在动态网页环境中判断任务完成度,支持 curriculum learning。
- DPO(Direct Preference Optimization):直接最大化偏好响应的似然,同时最小化与参考策略的 KL 散度。
- RRHF:采用排序损失方法,通过排序响应概率将多个响应的模型概率与人类偏好对齐,无需辅助价值模型。
Process-Based Reward(过程导向奖励)
- 对每一步推理打分,提供 dense supervision,解决 sparse reward 问题。过程监督奖励模型(PRM)已被证明比结果监督奖励模型(ORM)更可靠,特别是在需要复杂推理的领域。
- Math-Shepherd:用 MCTS 生成多条解题路径,统计每个 step 在成功路径中的出现频率 → 作为 correctness label → 训练 PRM(Process Reward Model)。
- AlphaMath:训练价值模型评估解路径中的步骤正确性,通过 MCTS 框架内的探索和利用更新策略和价值模型。
- rStar-Math:迭代 co-evolve policy 与 PRM:policy 生成轨迹 → PRM 打分 → DPO 更新 policy。
- Agent Q:在 MCTS 中集成 step-wise verifier(LLM 判断当前 step 是否合理),仅保留 verified 路径用于训练,避免错误累积。
- AgentPRM:提出迭代演化策略和过程奖励模型的方法。
Hybrid Reward(混合奖励)
- 结合最终任务成功的清晰性(结果导向)和中间步骤的细粒度指导(过程导向),克服仅结果信号的稀疏性,同时将智能体的逐步推理与最终任务目标对齐。
- GiGPO(Generalized Incentive-Guided Policy Optimization):同时使用 episode-level reward(任务是否完成)和 step-level reward(由轻量 critic 提供),解决 long-horizon credit assignment 问题。
- SPA-RL:提出奖励分解方法,将增量进展归因于多步轨迹中的每一步,基于最终任务完成度有效分配结果导向奖励,创建密集的中间进展奖励。
Imitation and Demonstration(模仿与示范)
模仿和示范学习是一种范式,自进化智能体通过从高质量示例中学习来改进其能力,这些示例可能由智能体自身、其他智能体或外部来源生成。与依赖显式奖励信号的基于奖励的方法不同,基于模仿的方法专注于通过迭代自训练和引导机制复制和细化成功的行为模式。
Self-Generated Demonstration Learning(自生成示范学习)
Bootstrapping Reasoning Capabilities(引导推理能力):
- 基础框架使语言模型能够通过迭代自训练引导其推理能力。该过程涉及为问题生成推理链,在正确解上微调,并重复此循环以逐步改进性能,无需真实推理路径。
- Verifier-guided self-training:使用单独的验证器模型在将生成的推理链纳入训练数据之前评估其质量,增强自改进的可靠性。
- Adaptive data sampling:动态调整训练数据的组成,基于模型在各种推理任务上的性能,从而缓解对特定问题类型的过拟合。
Multimodal Self-Training(多模态自训练):
- 将自训练扩展到多模态领域,在生成跨越视觉和文本模态的高质量示范方面面临独特挑战。
- 视觉语言模型可以通过训练自己生成的图像描述和视觉推理链来迭代改进。
- 多模态大语言模型可以作为强大的数据生成器,通过高级提示工程和质量过滤机制在不同模态和任务中生成多样化的训练示例。
Cross-Agent Demonstration Learning(跨智能体示范学习)
Multi-Agent Bootstrapped Reasoning(多智能体引导推理):
- 框架使多智能体系统能够通过引导推理从彼此的成功示范中学习。系统维护一个包含不同智能体生成的成功交互轨迹的经验库,促进高效的知识共享和协作改进。
- 每个智能体可以利用整个系统的集体经验,从而加速学习过程并实现多样化解决方案策略的发现。
- SiriuS:构建 experience library,agents 共享 successful trajectories。
Domain-Specific Demonstration Learning(领域特定示范学习):
- 在推荐系统等领域,Self-optimized fine-tuning 使基于 LLM 的推荐系统能够从自己的成功推荐模式中学习,创建反馈循环,随时间增强个性化。
- 系统从成功的用户交互中生成高质量推荐示范,并使用这些来微调底层语言模型,最终导致更准确和个性化的推荐。
Hybrid Demonstration Learning(混合示范学习)
Recursive Self-Improvement(递归自改进):
- 训练智能体通过结构化自反思和示范生成系统地改进其行为。这种方法使语言模型智能体能够内省其推理过程,识别改进领域,并生成纠正性示范以解决这些弱点。
- 这种递归过程建立了持续改进循环,智能体在自我诊断和自我纠正方面变得越来越熟练,导致更稳健和适应性强的行为。
Confidence-Guided Demonstration Selection(置信度引导示范选择):
- 利用模型的不确定性估计来确定哪些示范最有可能对学习产生积极贡献,过滤掉可能有害或低质量的示例。
- 通过确保仅使用高置信度、高质量的示例进行训练,这种方法有助于维护学习过程的完整性。
- SOFT(Self-Optimized Feedback Training):通过 internal feedback 优化示范质量。
Population-Based Evolution(基于种群的演化)
基于种群和进化的方法代表了与之前讨论的基于奖励和基于模仿的方法根本不同的智能体演化范式。这些方法从生物进化和集体智能中汲取灵感,同时维护多个智能体变体,允许并行探索解空间,并通过选择、变异、交叉和竞争交互等机制实现多样化能力的出现。
Single Agent Evolution(单智能体演化)
Learning from Evolution(从进化中学习):
- Darwin Gödel Machine (DGM):通过自改进智能体的开放端演化实现,维护所有历史版本的存档,使能够从任何过去的”物种”分支而非线性优化。系统通过允许智能体直接修改自己的 Python 代码库实现自引用改进,进化由编码基准上的经验性能驱动,父代选择平衡性能分数与多样性探索的新颖性奖励。
- GENOME(Nature-Inspired Population-Based Evolution):直接将遗传算法应用于语言模型参数演化,维护种群并在模型权重上使用交叉、变异和选择算子。GENOME+ 通过粒子群优化概念扩展了这一点,添加了继承机制和集成方法,证明无梯度进化优化可以通过参数空间探索有效改进模型能力。
Self-Play from Multiple Rollouts(从多次 rollout 的自对弈):
- SPIN(Self-Play Fine Tuning):通过让当前模型与先前版本竞争建立基础,创建进化压力,只有改进的策略在没有外部注释的情况下生存。
- SPC:通过复杂的对抗协同进化推进,其中”狡猾生成器”学习创建欺骗性错误,而”步骤批评者”演化以检测越来越细微的错误,使用自动验证在没有人工步骤级注释的情况下维持改进。
- STL(Self-Teaching Learning):通过迭代前瞻搜索演示自教学演化,其中价值模型从自己的探索性 rollout 生成训练数据,结合数值价值学习与自然语言推理链以引导持续改进。
Multi-Agent Evolution(多智能体演化)
System Architecture Evolution(系统架构演化):
- EvoMAC(Evolutionary Multi-Agent Collaboration):模仿多智能体系统的神经网络训练框架,实现”文本反向传播”,其中编译错误和测试失败作为损失信号驱动智能体团队组成和个体提示的迭代修改。专门的”更新团队”分析文本反馈以识别有问题的智能体并生成修改指令,有效在智能体配置空间而非模型参数中实现基于梯度的优化。
- Puppeteer:采用不同方法,专注于协调策略演化而非团队组成变化。系统采用通过强化学习演化其决策策略的集中式编排器,动态选择在每个步骤激活哪些智能体,同时平衡任务性能与计算成本。这种”木偶师-木偶”范式展示了架构演化如何在协调层面发生,发现高效的协作模式和涌现行为。
Knowledge-Based Evolution(基于知识的演化):
- MDTeamGPT:通过双知识库系统建立基础,实现 CorrectKB 用于存储成功案例,ChainKB 用于捕获失败反思,使系统能够通过结构化案例检索和推理增强从成功和错误中学习。
- MedAgentSim:展示如何将这种基于知识的演化应用于真实世界诊断场景,从患者交互中积累经验,并使用检索增强生成随时间改进咨询质量。
- PiFlow:将此范式应用于科学发现,维护原理-结果对的轨迹,并使用它们通过信息理论优化引导假设生成。
【理解】Reward-based 方法依赖 explicit feedback,而 imitation 方法利用 implicit knowledge;population-based 则探索 diverse strategies。三者可融合,如用 population 生成 demos → 用 reward 过滤 → 用于 SFT。
Where to Evolve(应用场景)
| 场景 | 特点 | 代表工作 |
|---|---|---|
| General-Purpose | 开放域任务(问答、工具使用) | AutoWebGLM, Expel, Alita |
| Web Navigation | 动态 HTML 环境,DOM 结构复杂 | WebArena, MiniWoB++, WebRL |
| GUI Automation | Android/iOS 屏幕操作,需视觉理解 | DigiRL, AITW |
| Code Generation | 编程任务,需执行验证 | Voyager, SCA |
| Strategic Games | 多人博弈、谈判,需心理建模 | Richelieu (AI Diplomacy) |
| Mathematical Reasoning | 形式化证明、解题,需符号推理 | Math-Shepherd, rStar-Math |
【理解】不同场景对演化维度有不同侧重,根本原因在于任务特性与约束条件的差异。Web Navigation 侧重 tool mastery 与 process reward,原因在于:动态 HTML 环境中的 DOM 结构复杂且频繁变化,智能体需要掌握大量网页操作工具(如 click、type、scroll、wait),且长轨迹任务中稀疏奖励(仅在最终页面满足 query 时获得)导致学习困难,因此需要 process reward 对每一步操作(如”成功定位到搜索框”)进行即时反馈,同时通过 tool mastery 学习不同网站的操作模式(如电商网站的”登录→搜索→筛选→购买”流程)。Strategic Games 侧重 architecture evolution,原因在于:多人博弈环境需要复杂的心理建模与策略推理能力,单一模块无法同时处理”预测对手意图”、”制定欺骗策略”、”评估联盟关系”等多层次任务,因此需要演化架构,动态添加 specialized modules(如 deception detection module、alliance negotiation module),形成多智能体协作拓扑。类似地,Code Generation 侧重 model evolution(通过执行验证生成训练数据),Mathematical Reasoning 侧重 context evolution(优化推理链 prompt)与 process reward(对每个推理步骤打分)。
Cross-cutting Evolutionary Dimensions(交叉演化维度)
智能体自进化是一个多方面的过程,由多个交叉维度定义,这些维度塑造了智能体如何学习、适应和改进。本节将系统比较主要自进化方法家族:基于奖励、基于模仿/示范和基于种群—.沿几个关键轴,如学习范式(在线 vs 离线)、策略一致性(在线策略 vs 离线策略)和奖励粒度(过程导向、结果导向或混合)。
Online and Offline Learning(在线与离线学习)
Offline Learning(离线学习)
- 学习阶段与实时任务执行解耦。离线过程通常涉及离线数据生成、过滤和模型微调的循环,专注于在部署前构建强大且通用的基础模型。
- LLM Bootstrapping:模型使用自己生成的内容增强自己的能力。例如,Self-Instruct 展示语言模型如何通过生成新指令(与其自己的响应配对)引导自己的指令遵循能力,创建用于微调的合成数据集。WizardLM 展示了如何逐步演化这些自生成指令的复杂性,推动模型在更具挑战性任务上的能力。
- GUI 和 Web 智能体:离线学习通常涉及利用预收集的高质量轨迹进行监督微调(SFT)。OS-Genesis 引入了反向任务合成方法用于自动轨迹创建。UI-Genie 采用统一的奖励模型进行轨迹评估和自改进循环,迭代生成高质量轨迹。两种方法都专注于策划丰富的 SFT 数据集以增强智能体解决复杂任务的能力。
- 离线强化学习:GUI-R1 和 InfiGUI-R1 利用基于规则的奖励,并在离线 GUI 数据集上应用 R1 风格训练。
Online Learning(在线学习)
- 使智能体能够在与实时或模拟环境交互时持续学习和适应。每次动作的反馈用于实时更新智能体的策略、计划或知识库,允许对动态或未见情况的更大适应性。
- Voyager:展示了一个 LLM 驱动的智能体,通过持续探索、生成自己的任务课程并从直接经验构建持久技能库来学习玩 Minecraft。
- AdaPlanner:专注于在任务内适应其计划;它生成初始计划,从环境接收反馈,并在线细化计划。
- SwiftSage:以快速-慢速思维过程运行,可以反思其快速、直观模式的失败,并切换到更深思熟虑、使用工具的慢速模式,基于任务难度在线适应其策略。
- 强化学习:DigiRL 展示如何在野外使用自主 RL 训练设备控制智能体,而 DistRL 提出异步分布式框架使此类设备上训练可行。MobileGUI-RL 通过引入合成任务生成管道结合轨迹感知奖励的组相对策略优化(GRPO)解决在线移动环境中训练 GUI 智能体的特定挑战。
On-policy and Off-policy Learning(在线策略与离线策略学习)

On-policy Learning(在线策略学习)
- 要求智能体仅从当前策略生成的经验中学习,确保策略一致性,但通常以样本效率为代价。
- Reflexion:通过其迭代自反思机制体现这种方法。智能体使用当前策略生成响应,接收失败反馈,并立即将此反馈纳入其推理过程以进行下一次迭代。
- GRPO 和 DAPO:继续这条路径并展示多次 rollout 的有效性。智能体总是从当前行为中学习,保持严格的策略一致性。
- 优势:在智能体设置中,在线策略方法提供出色的学习稳定性,避免困扰离线策略方法的分布不匹配问题。
- 劣势:样本效率低,因为每次策略更新都需要新数据收集,对于生成高质量轨迹成本高昂的复杂多步推理或工具使用场景,计算成本高。
Off-policy Learning(离线策略学习)
- 允许智能体从不同策略生成的经验中学习,包括先前版本、其他智能体或人类示范,显著提高样本效率,代价是潜在的分布不匹配。
- DPO-based off-policy:模型 $M_{t+1}$ 从先前版本 $M_t$ 生成的偏好数据中学习。系统通过 DPO 的内置 KL 散度约束与参考策略处理分布偏移,防止新策略偏离数据生成策略太远。
- Ranking-based supervision:通过基于排名的监督从多样化响应源(包括其他模型、人类和不同采样策略)中学习。该方法通过将对齐视为排名问题而非要求策略一致性,巧妙地避免了分布偏移。
- Multi-agent off-policy:在多智能体设置中,智能体从包含先前策略版本生成的成功交互轨迹的”经验库”中学习,实现昂贵的多智能体协调数据的高效重用。
- 优势:在样本效率方面表现出色,允许智能体利用历史数据、专家示范和跨智能体学习。对于成功轨迹罕见且生成昂贵的多步推理特别有价值。
- 劣势:面临分布偏移、奖励黑客(智能体利用训练和部署策略之间的不一致)的挑战,需要仔细正则化以保持训练稳定性。
▸区别:Online/Offline Learning vs On-policy/Off-policy Learning
关键区别:
Online/Offline Learning:关注学习时机(When to learn)
- Online:实时与环境交互时学习,数据收集与模型更新同时进行
- Offline:先收集数据,再离线训练,学习与执行解耦
On-policy/Off-policy Learning:关注策略一致性(What data to learn from)
- On-policy:只从当前策略生成的数据中学习,策略与数据生成策略一致
- Off-policy:可以从不同策略(历史版本、其他智能体、人类)生成的数据中学习
组合关系与应用:
Online + On-policy:实时交互,只用当前策略数据
- Reflexion:智能体执行任务 → 接收失败反馈 → 立即用自然语言反思 → 将反思存入记忆 → 下次迭代使用(当前策略生成的数据,实时更新)
- GRPO/DAPO:智能体执行多次 rollout → 从当前策略生成的轨迹中学习 → 实时更新策略
Online + Off-policy:实时交互,但可利用历史数据
- DPO-based off-policy:模型 $M_{t+1}$ 在实时部署中,利用先前版本 $M_t$ 生成的偏好数据学习,通过 KL 散度约束处理分布偏移
- AdaPlanner:在线执行任务时,利用历史成功/失败经验优化当前计划
Offline + On-policy:离线训练,但只用当前策略数据(较少见)
- 通常用于:先用当前策略生成一批数据 → 离线训练 → 但数据必须来自当前策略(确保一致性)
Offline + Off-policy:离线训练,利用历史/其他策略数据
- DPO/RRHF:利用历史版本或其他模型生成的偏好数据,离线训练新模型
- Self-Instruct/WizardLM:利用模型自己生成的数据(可视为”过去的自己”),离线微调
- OS-Genesis/UI-Genie:利用预收集的高质量轨迹(可能来自不同策略版本),离线 SFT
eg:智能体学习玩MineCraft
假设智能体要学习在 Minecraft 中建造房子:
Online + On-policy(实时 + 当前策略):
- 智能体现在开始玩游戏 → 尝试建造 → 失败了 → 立即反思”我应该先收集木头” → 立即更新自己的策略 → 下次尝试时用新策略
- 特点:边玩边学,只用自己当前策略的经验
Online + Off-policy(实时 + 历史数据):
- 智能体现在开始玩游戏 → 尝试建造 → 同时参考昨天自己玩的录像(历史策略数据)→ 看到昨天成功的方法 → 结合当前经验学习
- 特点:边玩边学,但可以利用历史经验
Offline + On-policy(离线 + 当前策略):
- 智能体先玩 100 局游戏,记录所有经验 → 停止游戏 → 用这 100 局的数据(都是当前策略生成的)训练模型 → 训练完再继续玩
- 特点:先收集数据再学,但只用当前策略的数据
Offline + Off-policy(离线 + 历史数据):
- 智能体收集了 1000 局游戏数据(包括自己不同版本、其他智能体、人类玩家的录像)→ 停止游戏 → 用这些混合数据训练模型 → 训练完再继续玩
- 特点:先收集数据再学,可以利用各种来源的数据
Reward Granularity(奖励粒度)
奖励粒度是奖励设计中的另一个关键选择,它决定了智能体在什么详细级别接收其学习信号。奖励粒度范围从评估整体任务完成的粗粒度结果导向奖励,到评估智能体轨迹每一步的细粒度过程导向奖励。
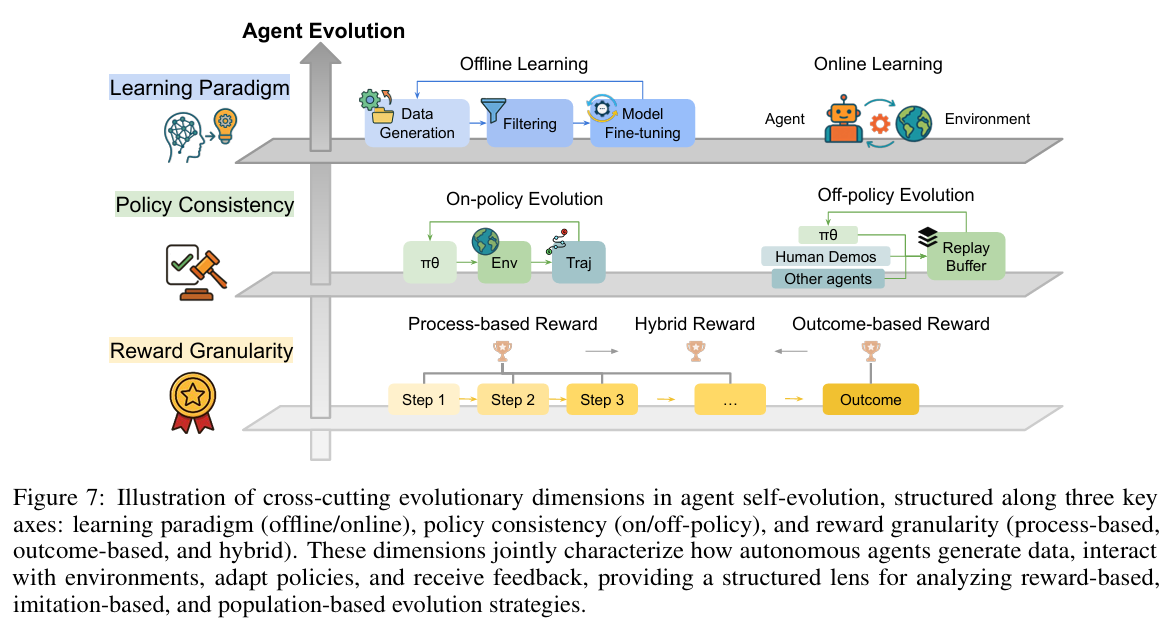
Outcome-Based Reward(结果导向奖励)
- 基于预定义任务的成功完成评估智能体的反馈机制。此奖励仅由智能体轨迹的最终状态确定,无论中间步骤如何。
- DPO(Direct Preference Optimization):直接最大化偏好响应的似然,同时最小化与参考策略的 KL 散度。
- RRHF:采用排序损失方法,通过排序响应概率将多个响应的模型概率与人类偏好对齐,无需辅助价值模型。
- Rejection sampling fine-tuning:如 AutoWebGLM 使用的方法,采用预设计的奖励模型评估轨迹结果,识别成功轨迹,并使用此高质量数据更新模型。
- DigiRL:将 GUI 导航任务建模为马尔可夫决策过程(MDP),并在 episode 结束时使用基于 VLM 的评估器获得最终稀疏奖励。
- WebRL:开发了稳健的结果监督奖励模型(ORM)以解决动态 Web 环境中固有的反馈稀疏性。ORM 在自演化课程框架内评估任务成功,使智能体能够从不成功的尝试中学习并逐步改进。
Process-Based Reward(过程导向奖励)
- 与提供单一、延迟信号的结果导向奖励相比,过程导向奖励范式通过评估智能体轨迹中的每一步提供更精确和细粒度的反馈。
- PRM vs ORM:过程监督奖励模型(PRM)已被证明比结果监督奖励模型(ORM)更可靠,特别是在需要复杂推理的领域,如解决数学问题。
- Math-Shepherd:提出自动过程注释框架,利用蒙特卡洛树搜索(MCTS)通过评估每个步骤推导正确答案的潜力来收集步骤级监督。
- AlphaMath:训练价值模型评估解路径中的步骤正确性,通过 MCTS 框架内的探索和利用更新策略和价值模型。
- rStar-Math 和 AgentPRM:都提出迭代演化策略和过程奖励模型的方法,生成逐步更高质量的推理路径,无需手动标签。
- Agent Q:在 MCTS 过程中集成步骤级验证机制以收集高质量轨迹,然后用于通过 DPO 训练迭代细化策略。
Hybrid Reward(混合奖励)
- 通过结合最终任务成功的清晰性(结果导向)和中间步骤的细粒度指导(过程导向),提供更全面的学习信号。
- GiGPO:通过引入双级奖励机制解决长视野智能体训练的不稳定性。它提供基于整个轨迹最终成功的 episode 级奖励,同时为中间动作分配局部、步骤级奖励。这种双重信号提供高级方向目标和低级纠正指导。
- SPA-RL:提出奖励分解方法,弥合稀疏结果信号和密集过程反馈之间的差距。它基于最终任务完成将增量进展归因于多步轨迹中的每一步,有效分配结果导向奖励跨过程步骤。这种方法创建密集的中间进展奖励,增强强化学习有效性,同时保持与最终任务目标的对齐。
其他维度
除了学习范式、策略一致性和奖励粒度的核心轴外,还有其他重要维度区分自进化方法:
Feedback Type(反馈类型)
- 反馈的性质差异很大:基于奖励的方法利用标量奖励、自然语言信号或模型置信度;模仿方法专注于示范轨迹和理由;基于种群的方法使用适应度分数或竞争信号。反馈类型从根本上决定了智能体使用什么信息来改进。
Data Source(数据来源)
- 基于奖励的方法通常通过智能体-环境交互或工程规则生成数据,而模仿学习通常依赖于人类或专家生成的示范。基于种群的方法从多个智能体或世代的集体经验中汲取,实现多样化探索但需要大量协调。
Sample Efficiency(样本效率)
- 模仿学习通常是最样本高效的,前提是有高质量的示范可用,因为智能体可以直接模仿专家行为。基于奖励的方法效率中等,效率高度敏感于奖励稀疏性。基于种群的演化往往样本效率低,因为它通常需要通过许多试验评估大量智能体变体。
Stability(稳定性)
- 基于奖励的学习对奖励函数的质量和设计敏感,存在奖励黑客或意外行为的风险。模仿学习严重依赖于示范的质量和多样性。基于种群的方法对种群大小和多样性敏感,小型或同质种群面临过早收敛的风险。
Scalability(可扩展性)
- 可扩展性由数据或反馈收集的可行性和并行化学习的能力决定。基于奖励的方法在反馈自动化时(例如,通过模拟器)扩展良好。模仿学习通常受到收集示范成本的瓶颈。基于种群的方法可以扩展到大规模计算,但资源密集。
评估
核心挑战:自进化智能体需要纵向评估(增长轨迹),而非传统静态”单次”评估。需捕获:随时间适应、知识积累/保留、长期泛化、跨任务技能转移、灾难性遗忘缓解。
指标
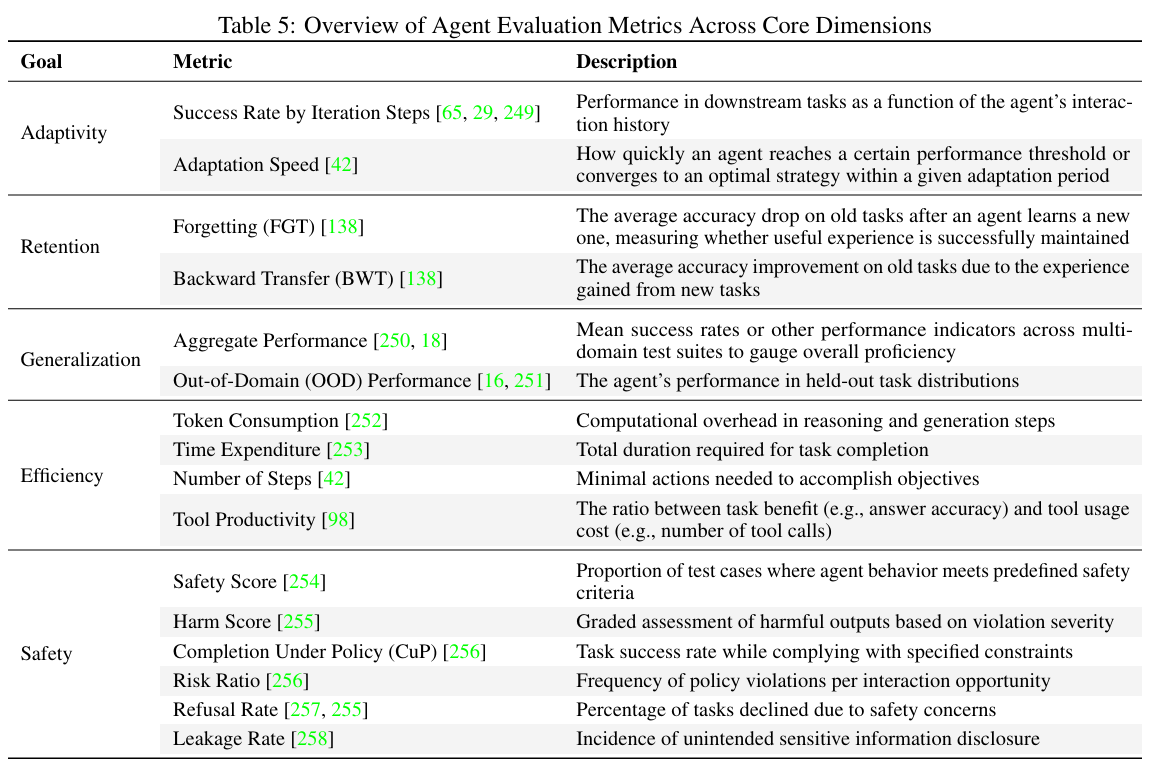
五个核心维度:Adaptivity(适应性)、Retention(保留)、Generalization(泛化)、Efficiency(效率)、Safety(安全性)
Adaptivity(适应性)
定义:衡量智能体通过经验改进域内任务性能的能力,量化学习曲线和性能提升程度。
关键指标:
- Success Rate by Iteration Steps:跟踪下游任务性能作为智能体交互历史的函数
- Adaptation Speed:智能体达到性能阈值或收敛到最优策略的速度
特点:非静态成功率,而是随时间/步骤/迭代动态评估
Retention(保留)
核心问题:灾难性遗忘(新知识侵蚀旧知识)和扩展交互中的知识保留
关键指标:
- Forgetting (FGT):评估学习新任务后旧任务的平均准确率下降
- Backward Transfer (BWT):评估新任务经验对旧任务的准确率改进
公式:
设 $J_{i,t}$ 为 LLM 智能体在完成 $t$ 个任务后对任务 $i$ 的性能:
$$
\text{FGT}_t = \frac{1}{t-1} \sum_{i=1}^{t-1} \left[\max_{j \in {i,i+1,\ldots,t}} (J_{j,i}) - J_{t,i}\right]
$$
$$
\text{BWT}_t = \frac{1}{t-1} \sum_{i=1}^{t-1} (J_{t,i} - J_{i,i})
$$
解释:
- FGT:衡量有用经验是否成功维持(值越小越好)
- BWT:正 BWT 表明新学习对旧任务产生积极影响,标志成功的知识转移
Generalization(泛化)
定义:将积累知识应用于新的、未见域或任务的能力
评估方法:
- Aggregate Performance:计算跨多域测试套件的聚合性能指标(如平均成功率)
- Out-of-Domain (OOD) Performance:使用保留任务分布进行域外评估,模拟真实世界新颖性场景
Efficiency(效率)
关键指标:
- Token Consumption:推理和生成步骤的计算成本
- Time Expenditure:任务完成所需总时长
- Number of Steps:完成任务所需的最少动作数
- Tool Productivity:任务收益与工具使用成本的比率(如答案准确率 vs 工具调用次数)
目标:在保持任务性能的同时最小化资源利用(较低值 = 更高效)
Safety(安全性)
核心关注:检查智能体在持续演化过程中是否发展出不安全或不良行为模式
关键指标:
- Safety Score:行为被标记为”安全”的测试用例比例
- Harm Score:基于手写评分标准,部分触发有害标准时获得部分分数
- Completion Under Policy (CuP):严格遵守规则/策略集的同时成功完成任务的比例
- Risk Ratio:特定维度上违反规则的频率(不合规的定量衡量)
- Refusal Rate:因任务攻击性/恶意/不安全而拒绝执行的任务比例
- Leakage Rate:无意泄露敏感/私人信息的频率
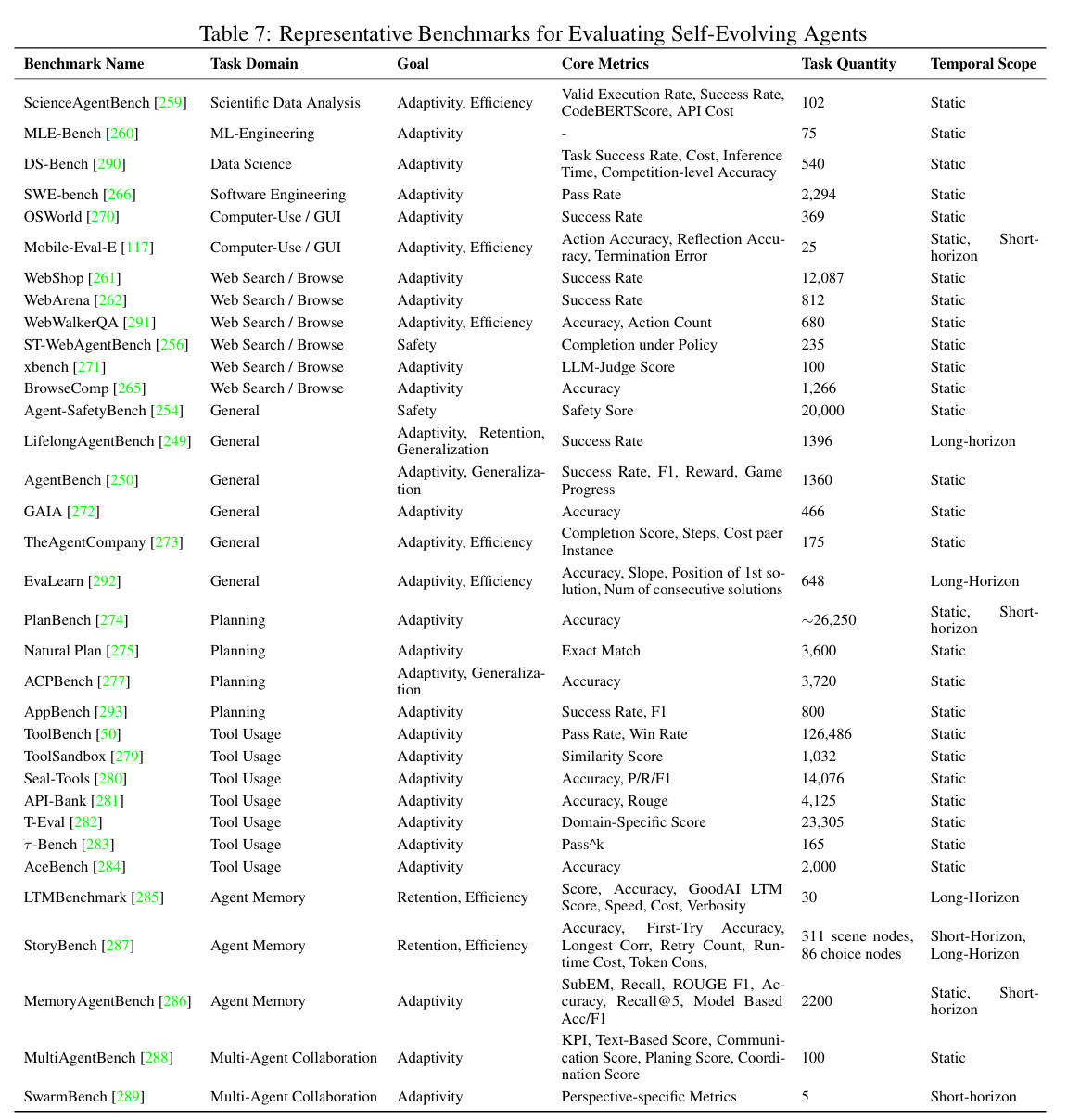
Benchmarks
范式
三类评估范式(按时间范围分类):
- Static Assessment(静态评估):特定时间点的即时性能
- Short-horizon Adaptive Assessment(短期自适应评估):相对短时间段内的适应和改进
- Long-horizon Lifelong Learning Ability Assessment(长期终身学习能力评估):跨扩展时期的持续学习
Static Assessment(静态评估)
特点:评估特定时间点的即时性能,与传统 AI 评估一致
用途:建立基线性能、比较不同架构、评估离散训练阶段后的能力
局限:不捕获动态、持续学习或长期演化方面
External Task-Solving Evaluation(外部任务解决评估)
科学数据分析/ML 工程:
- ScienceAgentBench:生成和执行数据分析代码
- MLE-Bench:解决 Kaggle 风格问题
网络搜索/浏览:
- WebShop、WebArena、X-WebAgentBench、Mind2Web、BrowseComp:模拟真实网络交互、复杂浏览场景、安全约束下的任务完成
软件工程:
- SWE-bench 系列:使用真实 GitHub issues 评估代码修复能力
计算机使用:
- OSWorld:涉及各种桌面和网络应用的开放端任务统一环境
通用智能体:
- AgentBench、GAIA、TheAgentCompany:跨多个知识域和专业任务的广泛问题解决能力
Internal Agent Components Evaluation(内部智能体组件评估)
Planning(规划):
- PlanBench、Natural Plan、AutoPlanBench、ACPBench:评估理解动态环境、制定策略、分解复杂问题、执行推理的能力
Tool Usage(工具使用):
- 简单基准:ToolAlpaca、ToolBench(基本选择和参数映射)
- 复杂基准:ToolSandbox、Seal-Tools、API-Bank、T-Eval、τ-Bench、AceBench(多轮交互、隐式状态依赖、嵌套调用)
Memory Management(记忆管理):
- LTMbenchmark、MemoryAgentBench、StoryBench:评估多轮交互、动态场景、长程依赖中的信息保留和利用
Multi-Agent Collaboration(多智能体协作):
- MultiAgentBench、SwarmBench:评估协作/竞争设置中的协调、通信、涌现群体智能
Metrics for Static Assessment(静态评估指标)
典型指标:准确率、成功率、进度率、完成率
域特定指标:CodeBertScore、有效执行率、通过率、F1 分数
特点:为孤立调用或固定任务集提供单一性能分数
Short-Horizon Adaptive Assessment(短期自适应评估)
定义:评估智能体在相对短时间段或有限交互次数内适应和改进的能力
场景:
- 相同任务实例上通过更多尝试改进性能
- 适应相同任务类型的新实例
两种评估方式:
- 用时间维度增强传统基准
- 专门设计支持短期动态学习的基准和指标
Augmented Traditional Benchmarks(增强的传统基准)
方法:引入新维度跟踪随时间性能,分析性能作为迭代/步骤/示例数量的函数
代表性工作:
- ADAS:ARC 基准上智能体系统迭代次数的保留测试准确率
- AWM:WebArena 地图测试分割下在线评估过程中的累积成功率(使用示例数量标记演化进度)
- WebEvolver:Mind2web-Live 下自改进迭代的成功率
Benchmarks with Built-in Dynamic Evaluation(内置动态评估的基准)
MemoryAgentBench:
- 测试时学习(TTL)维度:评估智能体在单次交互会话中直接从对话学习新任务的能力
- 评估任务类型:多类分类、推荐
- 评估方式:智能体需利用先前提供的信息(如上下文中的标记示例、长电影相关对话历史)执行新任务(如句子映射到类标签、推荐相关电影)
Metrics and Methods for Evaluating Short-Horizon Adaptations(评估短期适应的指标和方法)
关键指标:
- Success Rate by Iteration Steps:跟踪智能体与环境交互更多或多次尝试任务时的性能改进
- Learning Curve Analysis:可视化性能(成功率、准确率)在有限训练步骤/episode/交互次数上的变化
- Adaptation Speed:衡量智能体在短期内达到性能阈值或收敛到最优策略的速度
优势:有效评估初始学习能力和立即适应性,广泛用于当前自进化智能体
局限:有限时间窗口难以评估长期知识保留(灾难性遗忘缓解)和跨不同/顺序任务的真正终身学习能力
Long-Horizon Lifelong Learning Ability Assessment(长期终身学习能力评估)
核心关注:智能体在不同环境中持续获取、保留和重用知识的能力,跨扩展时期的能力
独特挑战:
- 灾难性遗忘
- 跨不同任务的稳健知识转移
- 扩展时期的有效资源管理
- 演化数据分布上持续评估时的数据泄露缓解
代表性基准:
LTMBenchmark:
- 专注领域:长期记忆(LTM)评估
- 评估方式:通过动态对话测试评估 LLM 智能体的记忆保留和持续学习
- 特点:使用受控干扰的交错对话模拟真实世界回忆挑战
- 关键指标:任务准确率、记忆跨度加权的 LTM 分数、效率衡量(测试/小时、成本)
LifelongAgentBench:
- 设计:跨域相互依赖任务序列(数据库 DB、操作系统 OS、知识图谱 KG)
- 要求:智能体逐步建立在先前获得的技能上
- 功能:跟踪跨延长学习轨迹的性能改进和知识保留
动态基准构建:
- BenchmarkSelf-Evolving:通过迭代持续更新现有基准
- 方法:持续更新基准数据集或重构原始基准来演化基准本身
- 发现:随着基准演化,模型性能可能下降,突出持续适应的困难
关键指标:
- Forgetting (FGT)、Backward Transfer (BWT)、Cost-per-Gain
- 长期泛化指标:评估持续演化的域外任务集上的性能,或衡量跨许多域长期学习后仍能有效执行的任务广度
长期终身学习能力评估对于全面评估自进化智能体的核心承诺至关重要:它们持续学习、保留知识和在扩展时期内有效泛化的能力。它们对于评估保留、对真正新场景的泛化以及长期运行的效率至关重要。该领域仍然是评估自进化智能体研究的关键前沿。
未来方向
个性化
核心挑战:
- 冷启动问题:智能体需在初始数据有限时逐步构建用户档案,准确理解用户意图
- 数据依赖:现有方法依赖高质量、大规模用户数据,实际部署中难以满足
- 技术挑战:长期记忆管理、外部工具集成、个性化生成(确保输出与用户事实/偏好一致)
现有方法:
- TWIN-GPT:利用电子健康记录创建患者数字孪生,提升临床试验预测准确性
- 自生成偏好数据:快速个性化 LLM,减少对标记数据的依赖
关键问题:
- 避免强化偏见和刻板印象
- 个性化规划与执行的效率问题
评估需求:
- 内在评估:使用 ROUGE、BLEU 等指标直接评估个性化生成文本质量
- 外在评估:通过推荐系统、分类任务等间接评估个性化效果
- 动态基准:需要灵活、动态的基准以评估长尾个性化数据管理能力
- 轻量指标:传统指标无法捕获演化动态,需要更轻量、自适应的评估方法
泛化
核心矛盾:专业化 vs 广泛适应性,影响可扩展性、知识转移和协作智能。
Scalable Architecture Design(可扩展架构设计)
挑战:
- 专业化-泛化权衡:为特定任务优化的智能体难以转移到新环境
- 计算成本:动态推理成本随适应机制复杂度非线性增长,限制现实资源下的泛化能力
进展:
- 配备反思和记忆增强能力的智能体在资源受限模型中显示出泛化潜力
- 限制:在需要长期持续适应的复杂真实世界场景中仍遇瓶颈
Cross-Domain Adaptation(跨域适应)
现状:
- 当前方法依赖域特定微调,限制新环境适应性
新方向:
- 测试时缩放:推理时动态分配计算资源到不熟悉场景,避免增加模型参数
- 元学习:快速少样本适应新域
关键问题:智能体需准确判断何时需要补充计算资源,并有效分配跨多样化推理任务
Continual Learning and Catastrophic Forgetting(持续学习与灾难性遗忘)
核心挑战:
- 稳定性-可塑性困境:在基础模型智能体中特别尖锐
- 计算成本:为每个新任务重新训练成本过高
缓解方法:
- 参数高效微调
- 选择性记忆机制
- 增量学习策略
开放问题:在效率与防止模型漂移之间实现最优平衡,特别是在资源约束或严格隐私考虑下
Knowledge Transferability(知识可转移性)
关键限制:
- LLM 智能体难以将新获得的知识传播到其他智能体,限制协作潜力
- 基础模型可能依赖浅层模式匹配,而非开发稳健的内部世界模型
未来方向:
- 理解知识可可靠泛化和传达给其他智能体的条件
- 量化智能体知识可转移性限制,识别协作瓶颈
- 设计机制鼓励形成稳健、可泛化的世界模型
安全可控
风险来源:
- 用户相关风险:模糊或误导性指令导致有害行动
- 环境风险:暴露于恶意内容(如钓鱼网站链接)
现有方法:
- TrustAgent:实施预规划、规划中、规划后策略促进安全行为
关键挑战:
- 难以准确区分必要和无关的敏感信息
- 任务相关 vs 无关信息的精确识别
- 目标涉及欺骗或不道德方法时的行动管理
- 持续学习不确定性加剧安全挑战
未来方向:
- 收集更大规模、多样化的真实世界场景数据
- 细化智能体宪法:开发更清晰、易理解的规则和案例库
- 探索更安全的训练算法
- 调查隐私保护措施对智能体效率的影响
多智能体生态系统
Ecosystems of Multi-Agents
- Balancing Individual and Collective Reasoning(平衡个体与集体推理)
核心问题:
- 集体讨论增强诊断推理,但智能体可能过度依赖群体共识,削弱独立推理能力
解决方向:
- 动态机制调整个体与集体输入的相对权重
- 防止决策由单个或小部分智能体主导
- 开发明确的知识库和标准化更新方法(利用成功/失败经验)
- Efficient Frameworks and Dynamic Evaluation(高效框架与动态评估)
进展:
- 自适应奖励模型和优化的动态网络结构增强协作自改进
关键差距:
- 缺乏智能体动态管理和更新知识的明确机制
未来需求:
- 新框架整合持续学习和自适应协作机制
- 动态评估基准:现有基准多为静态,无法捕获智能体角色的长期适应性和持续演化
- 纳入动态评估方法,反映持续适应、演化交互和多样化贡献
附录:关键参考文献索引
| 工作 | 核心贡献 | 来源 |
|---|---|---|
| Promptbreeder | Evolutionary prompt optimization | arXiv:2309.16797 |
| SCA | Self-challenging for code tasks | arXiv:2303.17651 |
| TextGrad | Textual gradient-based optimization | ICLR 2024 |
| MAS-Zero | Multi-agent self-evolution | arXiv:2505.14996 |
| AgentGen | Synthetic environment generation | ICML 2024 |
| Reflexion | Self-reflection via natural language | arXiv:2303.11366 |
| AdaPlanner | Closed-loop adaptive planning | AAAI 2024 |
| Self-Refine | Iterative self-critique & refine | arXiv:2303.11147 |
| RAGen | RL for agent generation | arXiv:2504.20073 |
| Mem0 | Scalable long-term memory | arXiv:2504.19413 |
| Expel | Experiential learning | arXiv:2312.16848 |
| Agent Workflow Memory | Multi-turn workflow storage | arXiv:2409.07429 |
| Richelieu | Structural self-modification in diplomacy | NeurIPS 2024 |
| PromptAgent | Strategic prompt planning | ACL 2024 |
| SPO | Self-supervised prompt optimization | arXiv:2502.06855 |
| EvoAgent | Evolutionary multi-agent generation | arXiv:2406.14228 |
| Voyager | Open-ended embodied agent | arXiv:2305.16291 |
| Alita | Generalist self-evolving agent | arXiv:2505.20286 |
| ATLASS | Closed-loop tool selection | arXiv:2503.10071 |
| CREATOR | Tool creation for reasoning | ICLR 2025 |
| SkillWeaver | Web agent skill discovery | WWW 2025 |
| CRAFT | Specialized toolset customization | arXiv:2309.17428 |
| LearnAct | Action learning for tool mastery | EMNLP 2024 |
| DRAFT | Self-driven tool interaction | arXiv:2410.08197 |
| ToolLLM | Mastering 16000+ APIs | NeurIPS 2024 |
| ToolGen | Unified tool retrieval & calling | ACL 2025 |
| Agentsquare | Automatic agent search | arXiv:2410.06153 |
| Darwin Gödel Machine | Open-ended self-improvement | arXiv:2505.22954 |
| AlphaEvolve | Evolutionary workflow search | GECCO 2025 |
| ReMA | Multi-agent role coordination | AAMAS 2025 |
| SiriuS | Experience sharing | arXiv:2312.17025 |
| WebRL | ORM for web tasks | arXiv:2406.12373 |
| DigiRL | VLM-based sparse reward for GUI | arXiv:2406.11896 |
| EvoMAC | Multi-agent co-evolution | arXiv:2410.16946v1 |
| Math-Shepherd | MCTS-based process annotation | ICLR 2025 |
| Agent Q | Step-wise verification + DPO | NeurIPS 2024 |
| GiGPO | Dual-level reward for stability | ICML 2025 |
| AutoWebGLM | Outcome-based self-evolution | arXiv:2406.12373 |
| rStar-Math | Iterative PRM evolution | arXiv:2501.04519 |