


综述地址:
- A Survey on Large Language Model-based Agents for Statistics and Data Science
- A Survey of AI Scientists
原先只整理了DS Agent,后续整合加入了AI Scientist。两个细分方向笔者都做过项目也都比较感兴趣,对以上两份综述进行了初步对比整合阅读。
【TBD】DS Agent的综述一年前(2024.12)出的已有些过时,后续计划自行增补2025年DS Agent信息。
定义
数据科学智能体(Data Science Agent)
数据科学智能体是以大语言模型(LLM)为核心推理引擎,通过自然语言接口接收用户指令,并在受控执行环境(如容器化沙箱)中自动完成统计分析、机器学习建模、数据可视化等任务的软件系统。其核心特征包括:
- 输入为自然语言指令(例如:“对鸢尾花数据集做聚类”)
- 输出包含可执行代码、运行结果、以及自然语言解释
- 具备错误检测、诊断与自我修正能力(即“反思”机制)
- 支持端到端自动化或人机交互式执行模式
典型应用场景包括:Kaggle竞赛辅助、商业BI分析、学术研究中的探索性数据分析(EDA)、自动化报告生成等。
人工智能科学家(AI Scientist)
AI Scientist 是一类面向完整科学研究生命周期的自主智能系统,不仅处理数据,还参与知识发现、假设生成、实验设计、结果解释、论文撰写乃至投稿准备等高阶认知活动。其终极目标是实现端到端可验证、可复现、可审计的科研自动化。
区别在于:
- Data Science Agent 关注“如何执行分析”(How to analyze),聚焦于任务执行层面,更多涉及写DS的代码部分,除了理解、建模,也需要较强的Coder;
- AI Scientist 关注“为何开展这项研究”及“如何表达科学发现”(Why to study & How to communicate),涵盖科研全流程的认知闭环。
DS Agent 技术实现
系统架构
主流数据科学智能体通常由以下六个核心模块构成:
自然语言理解(NLU)模块
- 功能:将用户模糊指令解析为结构化任务描述
- 技术实现:
- 利用 LLM 的 zero-shot 或 few-shot 能力提取意图、实体(如数据路径、目标变量)、约束条件(如”使用随机森林”、”5折交叉验证”)
- 通过命名实体识别(NER)提取关键信息:数据集路径、目标变量名、分析方法偏好
- 使用意图分类模型区分任务类型:分类、回归、聚类、可视化等
- 支持多轮对话,通过上下文理解用户真实意图
任务规划器(Task Planner)
- 功能:将高层目标分解为有序子任务 DAG(有向无环图)
- 技术实现:
- 基于 ReAct(Reason + Act)或 ToT(Tree of Thoughts)框架,生成带依赖关系的任务列表
- 每个任务含
task_id与dependent_task_ids - 采用链式思维(Chain-of-Thought)分解复杂任务为可管理的子步骤
- 支持动态调整:根据执行结果重新规划后续任务
- 使用约束求解器确保任务依赖关系的正确性
代码生成器(Code Generator)
- 功能:为每个子任务生成可执行 Python/R 代码
- 技术实现:
- 结合动态上下文(如数据 schema、缺失值分布、包版本)调用 LLM
- 常使用 system prompt 注入最佳实践(如”优先使用 sklearn.pipeline”)
- 集成领域知识库,确保生成的代码符合统计和数据科学最佳实践
- 支持代码模板和模式复用,提高生成代码的质量和一致性
- 使用检索增强生成(RAG)技术,从代码库中检索相似示例作为参考
执行沙箱(Execution Sandbox)
- 功能:安全运行代码并捕获标准输出、错误日志、返回值
- 技术实现:
- 基于 Docker 容器隔离,预装 Python 3.9+、R 4.3+、Jupyter、SQL 引擎
- 限制 CPU/内存/GPU 使用;支持超时中断
- 实施多层安全机制:代码静态分析、运行时监控、资源限制
- 支持持久化执行状态,允许增量执行和断点恢复
- 捕获完整执行轨迹:标准输出、标准错误、变量状态、内存使用情况
反思与调试器(Reflection Module)
- 功能:分析执行失败原因并触发修正策略
- 技术实现:
- 将异常信息(如 KeyError、ImportError)作为新 prompt 输入,引导 LLM 生成替代方案
- 支持多轮重试(如最多3次)
- 采用自洽性检查:验证代码逻辑、数据一致性、结果合理性
- 从历史执行中学习常见错误模式,提供更精准的修复建议
- 支持用户交互反馈,将人工修正纳入学习循环
结果解释器(Result Interpreter)
- 功能:将数值、图表、模型指标转化为自然语言总结
- 技术实现:
- 使用模板填充(如”准确率为 {acc:.3f}”)或 LLM 生成解释
- 示例解释:”该模型性能优于基线,表明特征工程有效”
- 支持多模态输出解释:数值结果、图表解读、统计显著性说明
- 生成可操作的建议:下一步分析方向、潜在改进点
- 提供可解释性分析:特征重要性、模型决策路径可视化
任务规划机制
以 Data Interpreter 为例详解:
用户输入:
“I want to train a classifier to classify breast cancer using the data from /Users/xxx/breast_cancer_wisconsin_diagnostic.csv. The target variable is ‘diagnosis’. Use any model you think is appropriate. Perform 5-fold cross-validation during training and print the final accuracy.”
系统处理流程:
意图解析:
LLM 提取结构化元数据:1
2
3
4
5
6
7{
"goal": "train classification model",
"dataset_path": "/Users/xxx/breast_cancer_wisconsin_diagnostic.csv",
"target_column": "diagnosis",
"validation_method": "5-fold CV",
"output_metric": "accuracy"
}任务分解:
规划器生成三个串行子任务:- Task 1 (
id=1, deps=[]): Load and preprocess the dataset - Task 2 (
id=2, deps=[1]): Train model with 5-fold cross-validation - Task 3 (
id=3, deps=[2]): Evaluate and print final accuracy
- Task 1 (
依赖执行:
系统按拓扑序依次执行,确保前序任务成功后再启动后续任务。
代码生成与执行流程
上下文构建
在生成 Task 1 代码前,系统会预读取数据文件头几行(安全模式下仅读 schema),获取:
- 列名列表(如
['id', 'diagnosis ', 'radius_mean', ...]) - 数据类型(int64, float64, object)
- 缺失值统计(
df.isnull().sum())
若发现列名含不可见字符(如 'diagnosis '),系统会在 prompt 中显式提醒:“注意目标列名可能包含尾随空格”。
执行与错误处理(ReAct 范式)
- 首次执行失败:因代码中使用
'diagnosis',但实际列为'diagnosis ',抛出KeyError: 'diagnosis' - 错误捕获:沙箱返回异常堆栈
- 反思触发:系统构造新 prompt:
“执行失败:KeyError: ‘diagnosis’。当前 DataFrame 列名为:[‘id’, ‘diagnosis ‘, ‘radius_mean’, …]。请修正列名引用。”
- 修正生成:
1
2
3# 修正:去除空格
df = df.rename(columns=lambda x: x.strip())
y = df['diagnosis'].map({'M': 1, 'B': 0}) - 重试成功:最终输出准确率 0.9649
此过程体现 ReAct(Reason + Act) 范式:先推理错误根源,再采取具体修正行动。
用户交互模式
Data Interpreter 支持两种运行模式:
全自动模式(
--auto_run True):- 系统连续执行所有子任务,中间不暂停
- 适用于简单、确定性高的任务(如标准 EDA)
- 缺点:无法人工干预,出错需重跑全部步骤,token 消耗高
交互式模式(
--auto_run False):- 每步生成代码后暂停,等待用户确认、修改或跳过
- 用户可插入断点、保存中间变量、调整超参
- 支持增量执行:后续任务可复用已生成的变量(通过全局命名空间)
- 适合复杂、探索性任务
该设计在自动化效率与用户控制权之间取得平衡。
关键技术设计趋势
Planning
任务分解策略:
- 采用链式思维(Chain-of-Thought)将复杂任务分解为可管理的子步骤
- 使用树状思维(Tree-of-Thoughts)探索多个可能的执行路径
- 动态规划:根据中间结果调整后续任务序列
依赖关系管理:
- 构建有向无环图(DAG)表示任务依赖
- 拓扑排序确保任务执行顺序的正确性
- 支持并行执行:识别可独立执行的任务子集
Reasoning
上下文理解:
- 维护会话历史,理解多轮对话中的隐含信息
- 识别用户意图的细微差别(如”探索性分析” vs “验证性分析”)
- 结合领域知识进行智能推断
统计推理:
- 理解统计假设检验的适用条件
- 选择合适的分析方法(参数 vs 非参数检验)
- 解释统计显著性结果的含义
Reflection & Iteration
错误诊断:
- 分析执行失败的根因(数据问题、逻辑错误、环境配置)
- 从错误堆栈中提取关键信息
- 识别常见错误模式(如数据类型不匹配、缺失值处理不当)
迭代改进:
- 基于执行结果评估代码质量
- 生成替代方案并比较优劣
- 从用户反馈中学习,避免重复错误
Multi-agent Collaboration
专业化分工:
- 数据分析代理:专注于数据清洗和探索
- 建模代理:负责模型选择和训练
- 可视化代理:生成图表和报告
- 评估代理:评估模型性能和结果质量
协作机制:
- 代理间通过消息传递共享信息
- 协调资源分配,避免冲突
- 汇总各代理的输出生成最终结果
Knowledge Integration
领域知识注入【2025年出的几个DS Agent这块的trick已经玩出花了】:
- 集成统计和数据科学最佳实践
- 使用检索增强生成(RAG)从知识库中检索相关信息【如何抽取?什么粒度/格式?如何rerank? RAG很简单,怎么选知识库的材料、以什么形式建库、怎么召回知识等等来确保增强有效且高效不简单。】
- 结合领域特定术语库确保用词准确
代码模式复用【2025代码RAG增强的方法效果还没有特别好的】:
- 维护常用代码模板库
- 从历史执行中提取成功模式
- 根据任务类型推荐合适的代码片段
System Desiign
工程问题,但是实际实验也需要注意。
安全性保障:
- 代码静态分析:检查恶意代码、危险操作
- 资源限制:CPU、内存、磁盘使用上限
- 沙箱隔离:防止对宿主系统的破坏
可复现性:
- 记录完整的执行环境信息(包版本、系统配置)
- 固定随机种子确保结果一致性
- 导出可复现的脚本和配置文件
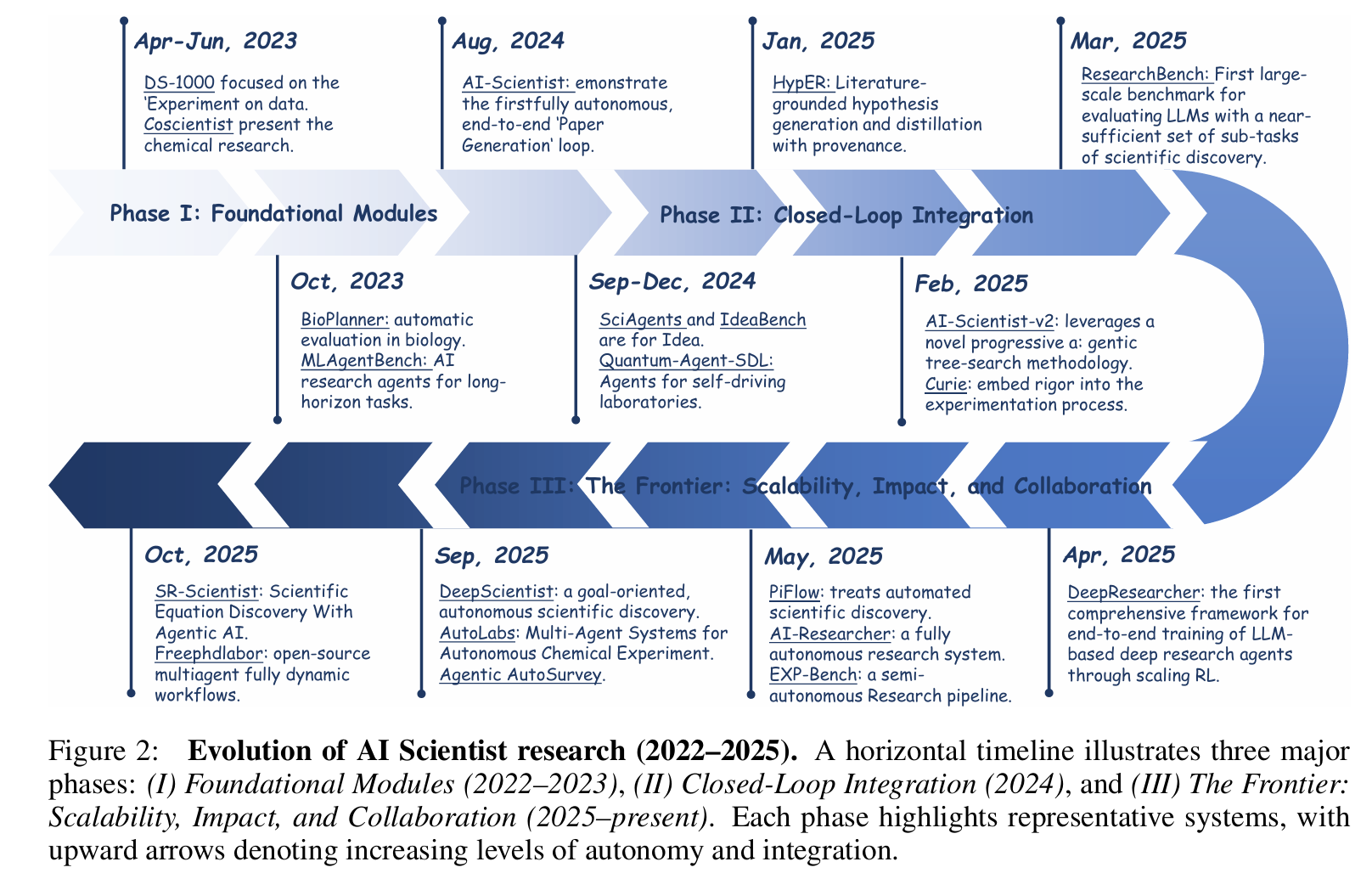
AI Scientist 科研自动化框架
根据《A Survey of AI Scientist》,完整科研流程被形式化为以下几个阶段,每阶段均有明确输入、输出与技术方法。
Contemporary AI Scientist systems transcend these limitations by integrating foundation models with closed-loop scientific reasoning (observe → hypothesize → experiment → analyze → publish), through agentic planning, principle-driven inference, and adaptive self-correction mechanisms.
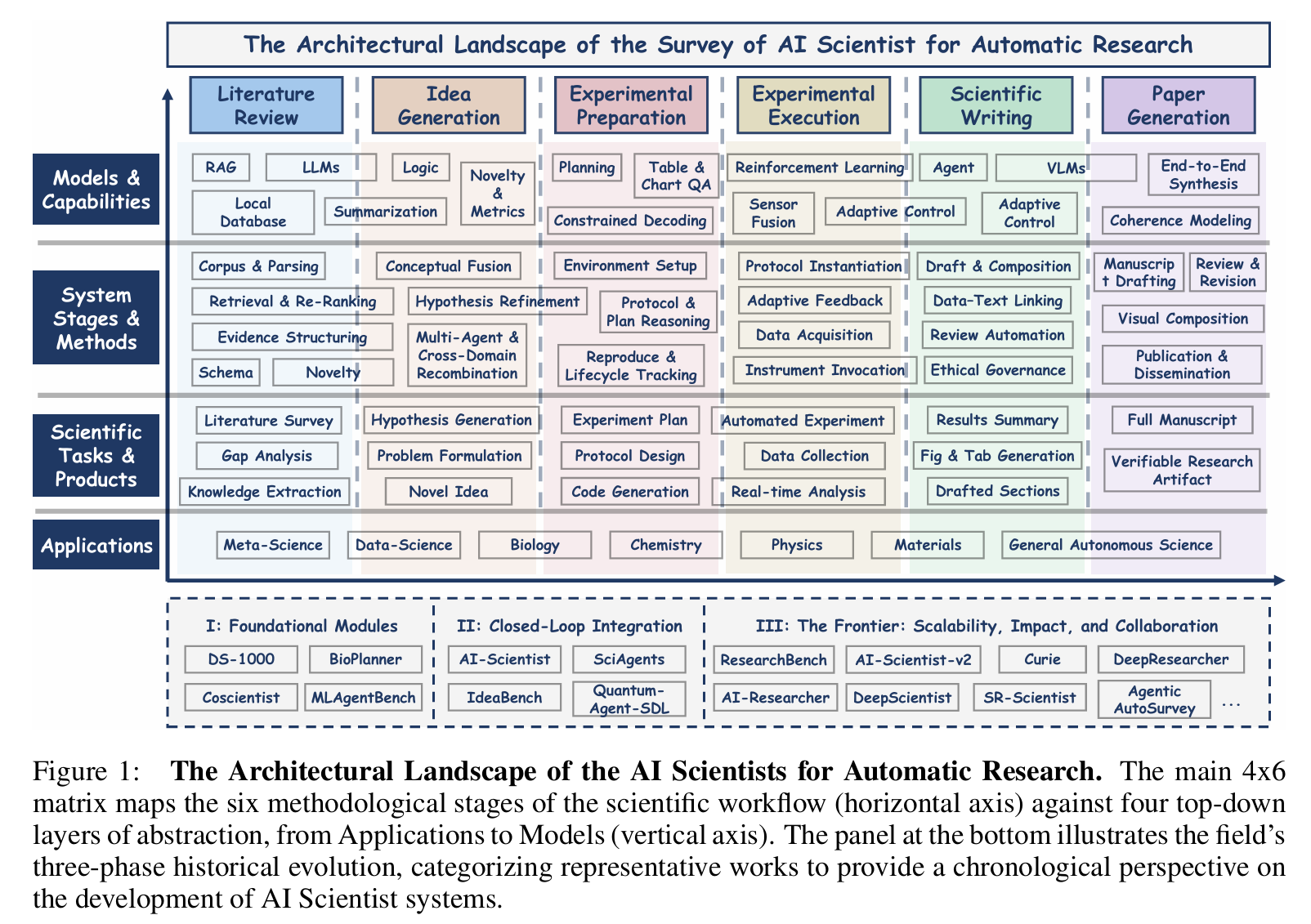
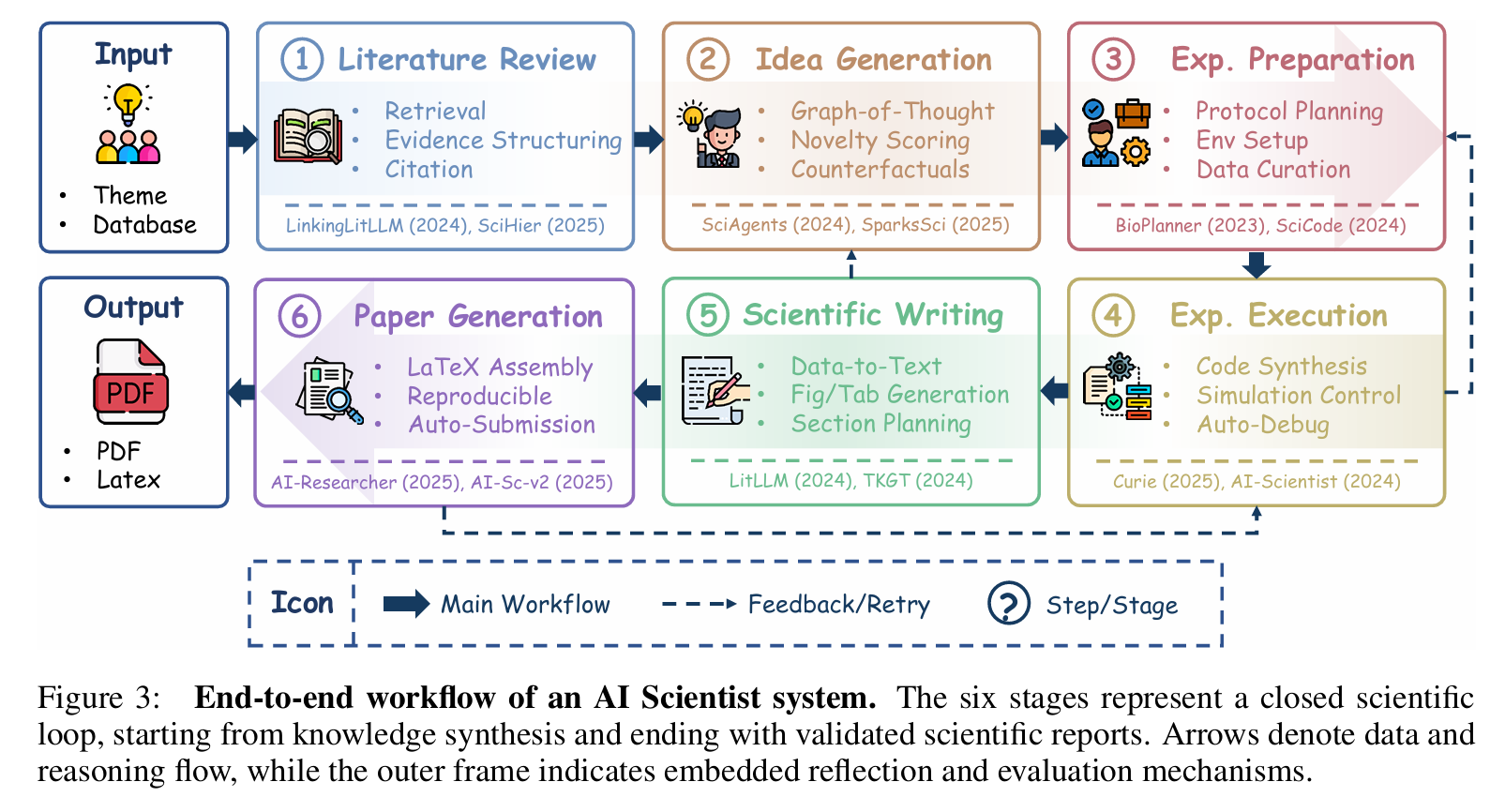
文献综述(Literature Review)
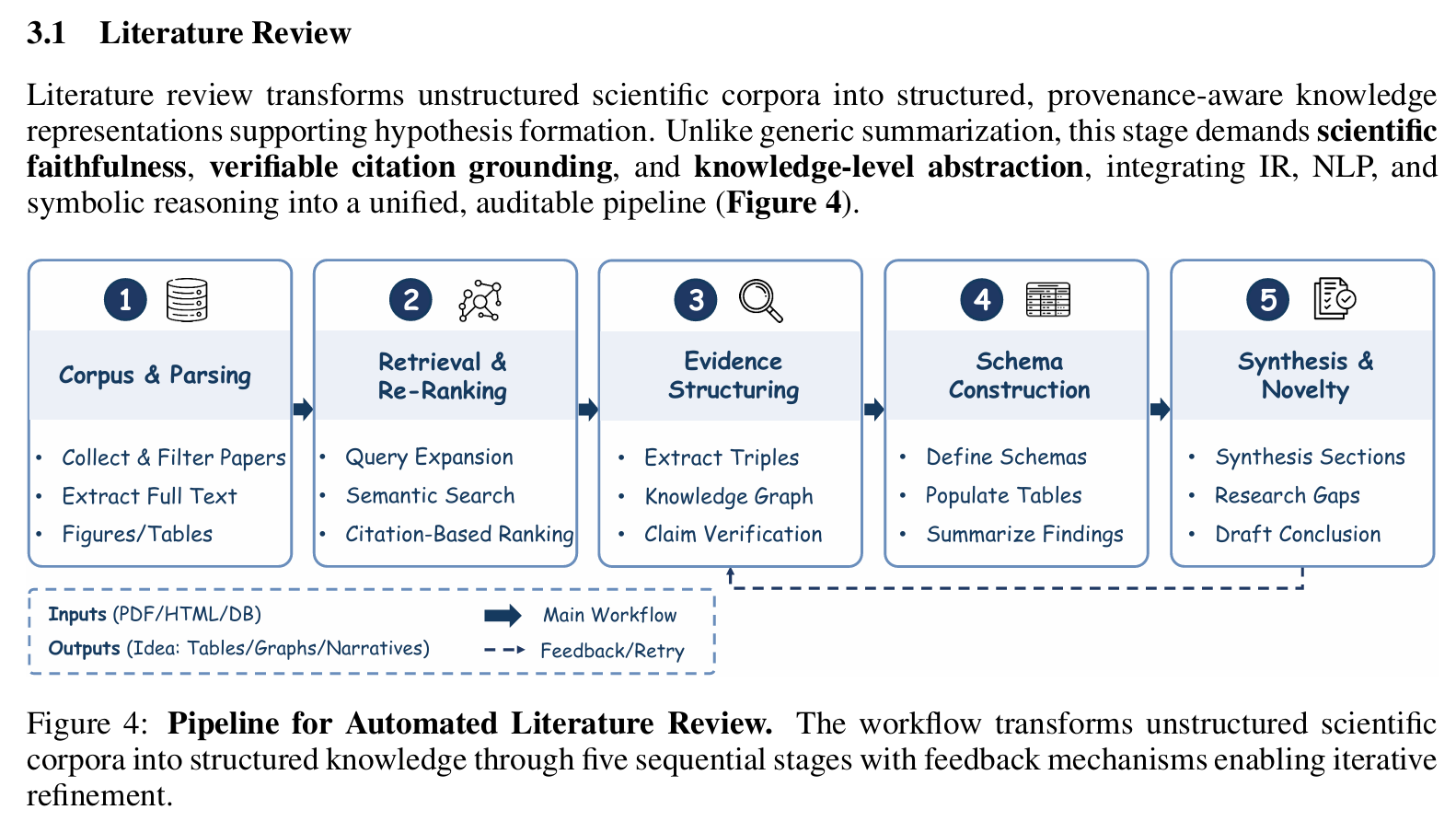
- 输入:研究主题关键词(如”large language models in drug discovery”)
- 输出:领域知识图谱、研究空白识别、关键论文摘要
- 技术方法:
- 使用 Semantic Scholar / arXiv / PubMed API 进行语义检索
- 构建 citation graph,计算节点中心性以识别奠基性工作
- 应用 RAG(Retrieval-Augmented Generation)生成连贯综述
- 使用 BERT-based 模型对论文进行细粒度分类(方法/实验/理论)
- 代表系统:
- LitLLM:基于引用网络的总结和知识提取,生成知识演化路径
- HypER:引用驱动的文献筛选与总结(如”寻找支持 GNN 可解释性的证据”)
- SciAgents:利用网络规模的交互和图推理来映射现有知识
- DeepResearcher:在真实网络环境中进行图推理,为下游任务提供坚实基础
想法生成(Idea Generation)
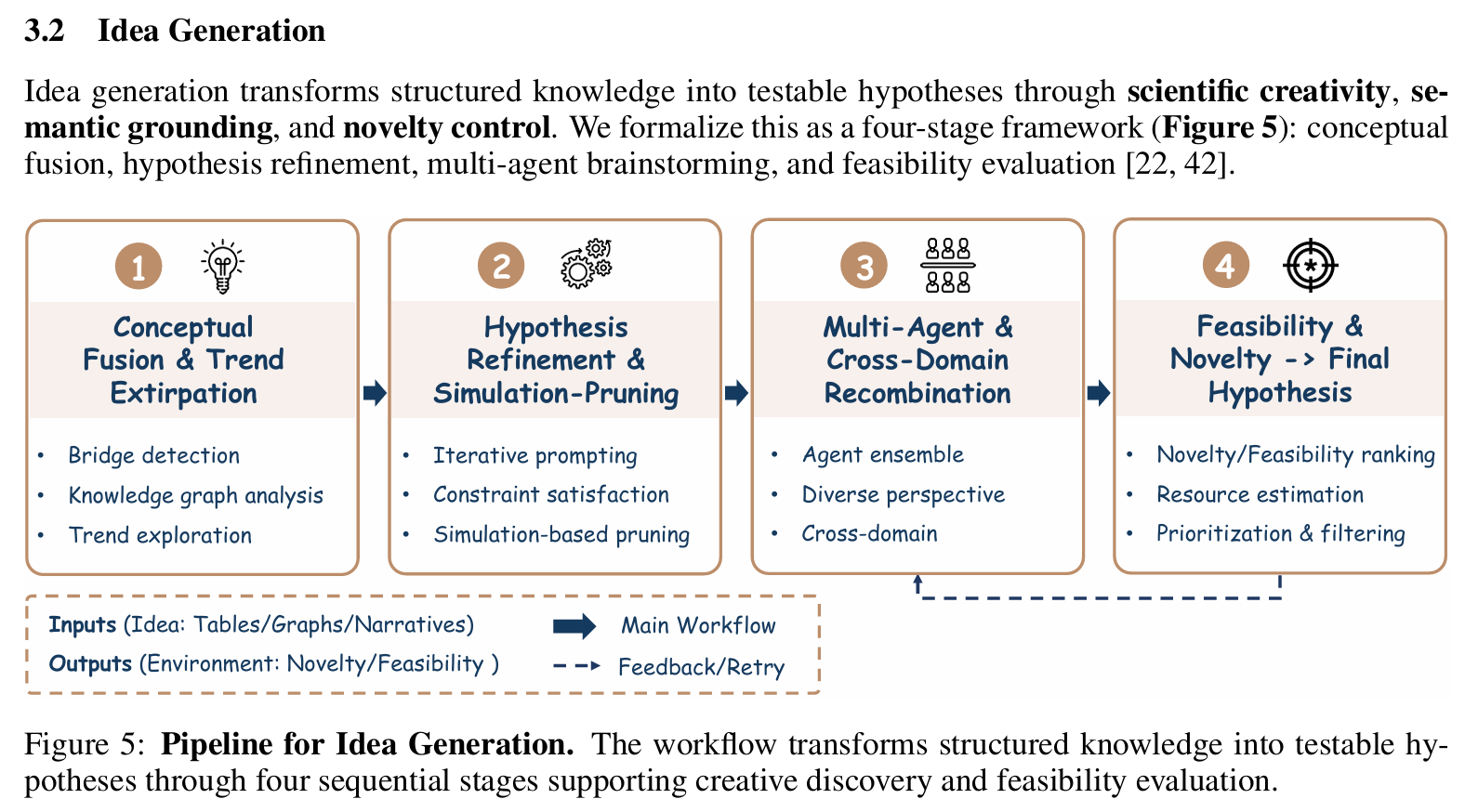
- 输入:文献综述结果 + 领域约束
- 输出:新颖、可行的研究假设(如”将 diffusion model 用于蛋白质折叠”)
- 技术方法:
- 在知识图谱上进行多跳推理(A → B → C ⇒ A → ?)
- Prompt engineering 引导 LLM 进行反事实思考(”What if we replace X with Y?”)
- 使用强化学习优化假设质量,奖励函数 = α·新颖性 + β·可行性 + γ·影响力
- 结合专家标注数据微调 idea 生成模型
- 代表系统:
- IdeaBench:提供标准化 benchmark,由人类专家对假设打分,明确评估该能力
- Coscientist:领域特定系统,具备假设发现和问题表述能力
- DeepScientist:端到端框架,将想法生成作为核心组件
实验准备(Experimental Preparation)
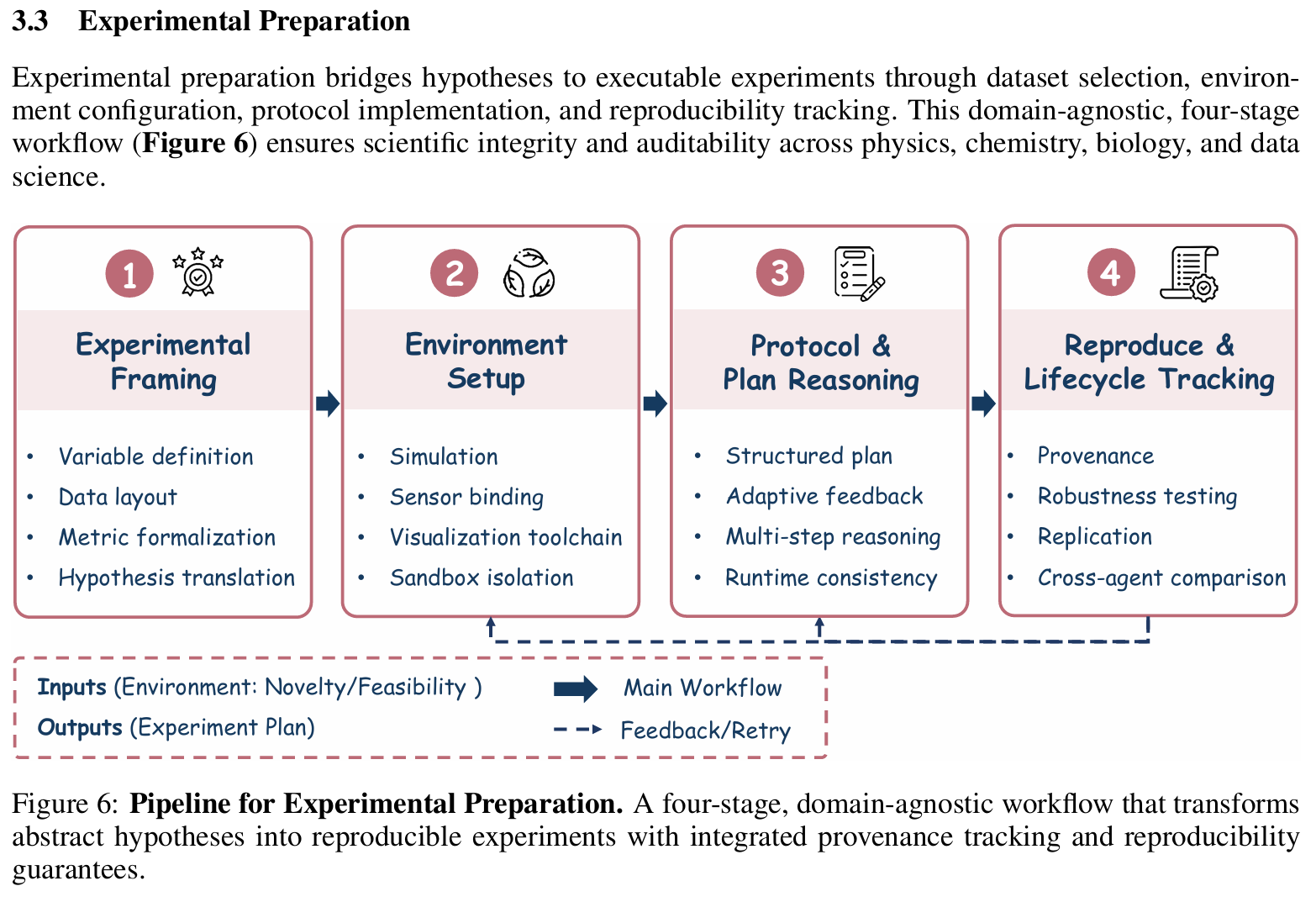
- 输入:研究假设
- 输出:可执行实验方案(含数据集、模型、指标、超参范围)
- 技术方法:
- 将假设转化为可操作变量(如”测试不同 dropout rate 对泛化的影响”)
- 自动生成数据选择逻辑(如”使用 CIFAR-10 而非 MNIST,因后者过于简单”)
- 使用 CSP(Constraint Satisfaction Problem)求解器确保方案可行性(如 GPU 显存 ≥ 模型参数量 × 4 bytes)
- 支持多智能体协商资源分配
- 定义变量、选择数据集、生成分析代码、设计实验协议
- 代表系统:
- DS-1000:数据科学导向的 benchmark,评估实验方案生成能力
- MLAgentBench:数据科学导向的 benchmark,提供标准化 ML 实验环境
- The AI Scientist v1:集成系统,包含实验准备作为关键步骤
- freephdlabor:集成系统,将抽象假设转化为可执行计划
实验执行(Experimental Execution)
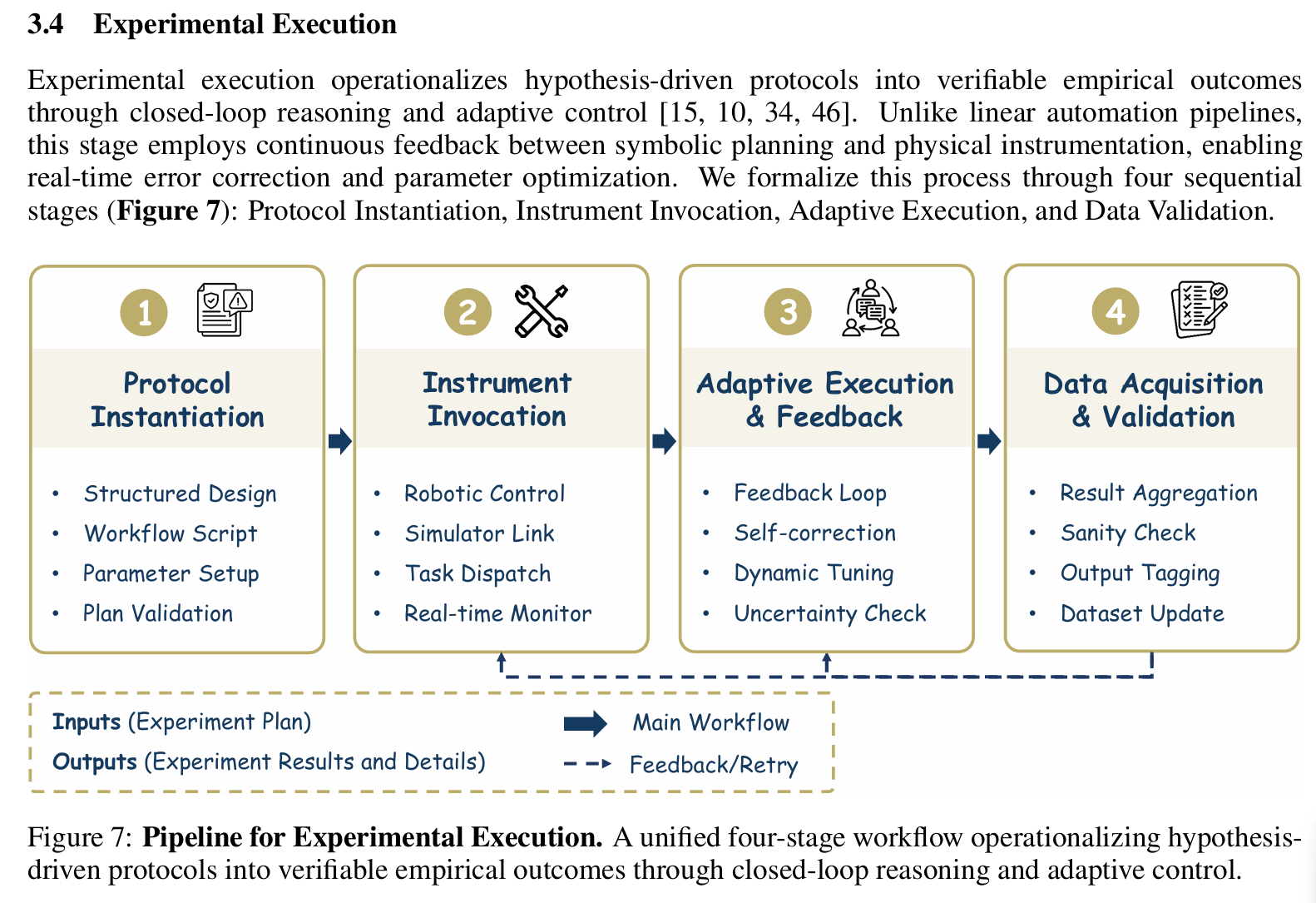
- 输入:实验方案
- 输出:原始结果(指标、日志、模型 checkpoint)
- 技术方法:
- 在隔离沙箱中运行代码(Python/R/Julia/Matlab)
- 自动管理依赖:生成
requirements.txt、environment.yml或Dockerfile - 实时监控资源使用,支持超时与异常中断
- 支持分布式执行(如 Ray + Optuna 实现 AutoML 并行搜索)
- 与工具交互、控制机器人、根据实时反馈调整计划
- 代表系统:
- Coscientist:协调物理实验室硬件,在真实实验环境中执行实验
- Quantum-Agent-SDL:协调物理实验室硬件,在量子算法领域执行实验
- Curie:在模拟环境中展示实验执行能力
- DeepResearcher:在真实世界网络环境中展示实验执行能力
科学写作(Scientific Writing)
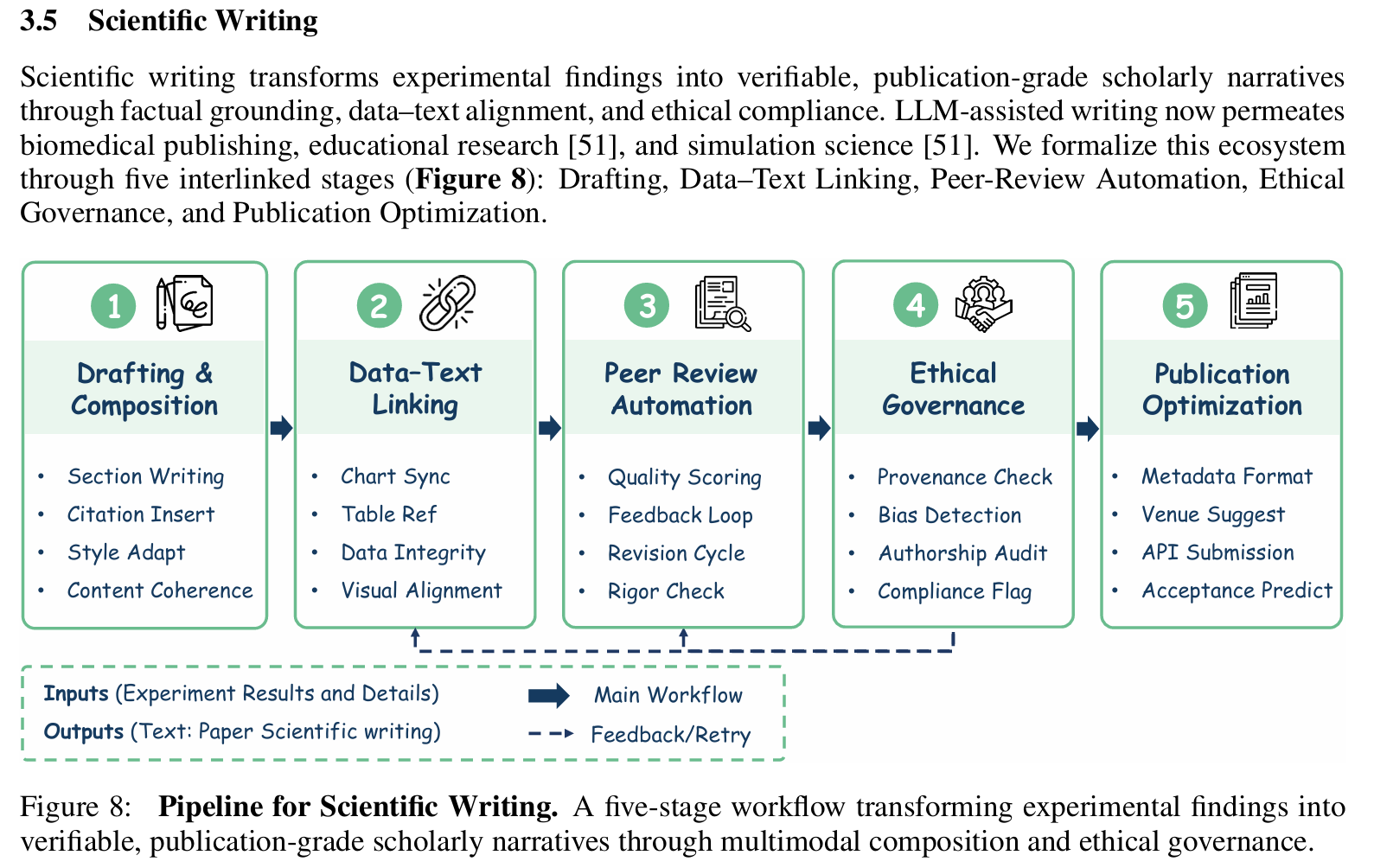
- 输入:实验结果
- 输出:符合学术规范的章节文本(Methods, Results, Discussion)
- 技术方法:
- 使用 LaTeX 模板填充内容(如
\section{Results}) - 控制生成风格:被动语态、第三人称、避免主观表述
- 自动插入统计显著性标记(如 “p < 0.01***”)
- 结合领域术语库确保用词准确(如”sensitivity” vs “recall”)
- 将结构化结果转化为连贯、引用支撑的叙述
- 从段落感知总结到数据到文本的合成
- 使用 LaTeX 模板填充内容(如
- 代表系统:
- Research Bench:端到端系统的关键功能,支持科学写作
- freephdlabor:人在回路的框架,AI 起草内容供人类审查和完善
论文生成(Paper Generation)
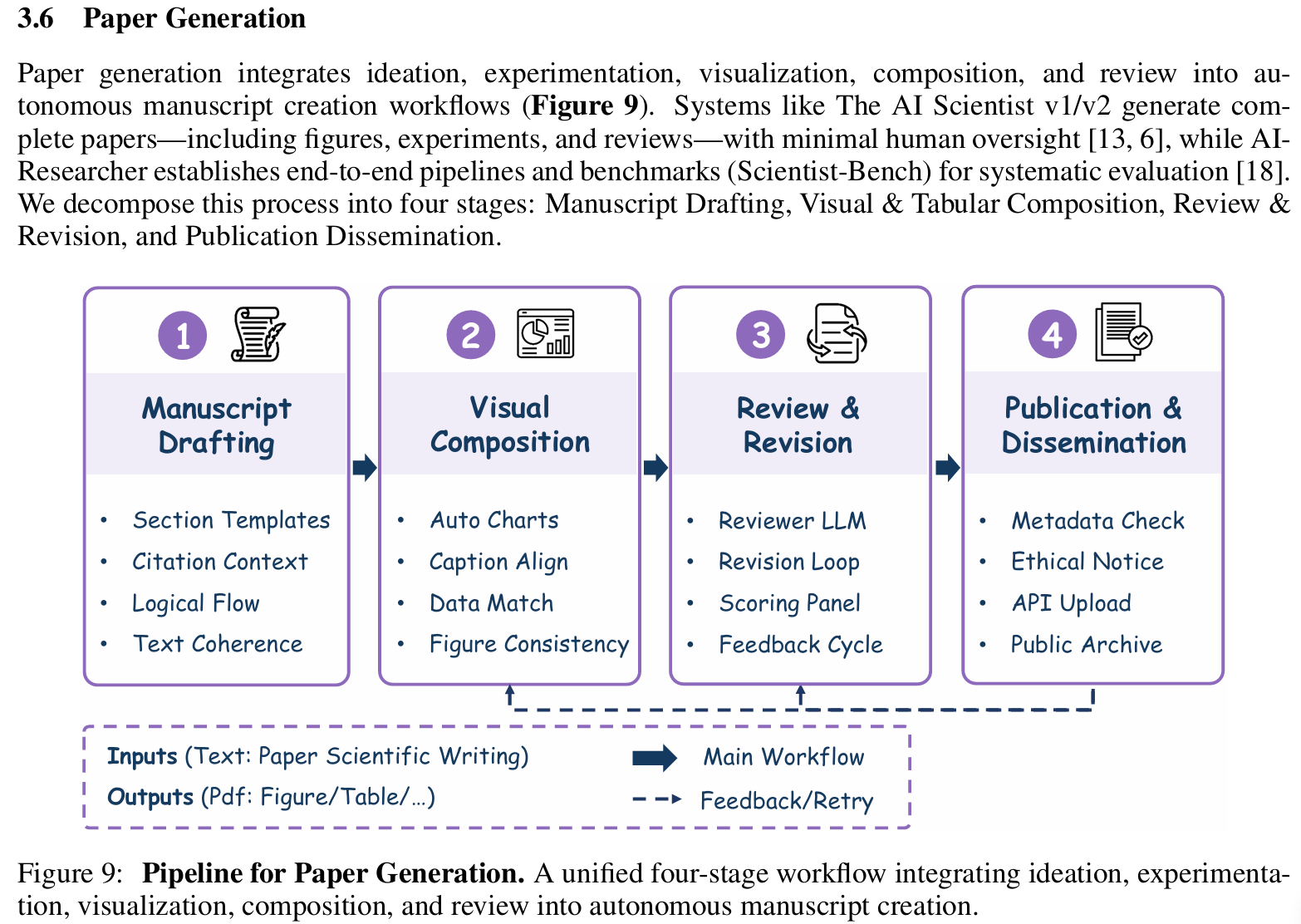
- 输入:全文各章节 + 图表 + 参考文献
- 输出:可提交的 PDF 论文(符合 arXiv / ACL / NeurIPS 格式)
- 技术方法:
- 多模态融合:将 matplotlib/seaborn 图表嵌入 LaTeX
- 自动引用管理:匹配 BibTeX 条目,避免重复引用
- 格式校验:使用 latexmk 编译并检查错误
- 支持多语言输出(英文为主,部分系统支持中文摘要)
- 需要紧密集成所有先前阶段的能力
- 代表系统:
- The AI Scientist v1/v2:完全自主系统,可生成完整 publication-ready 手稿
- AI-Researcher:完全自主系统,实现端到端论文生成
- DeepScientist:完全自主系统,代表最高级的端到端能力
系统能力覆盖矩阵
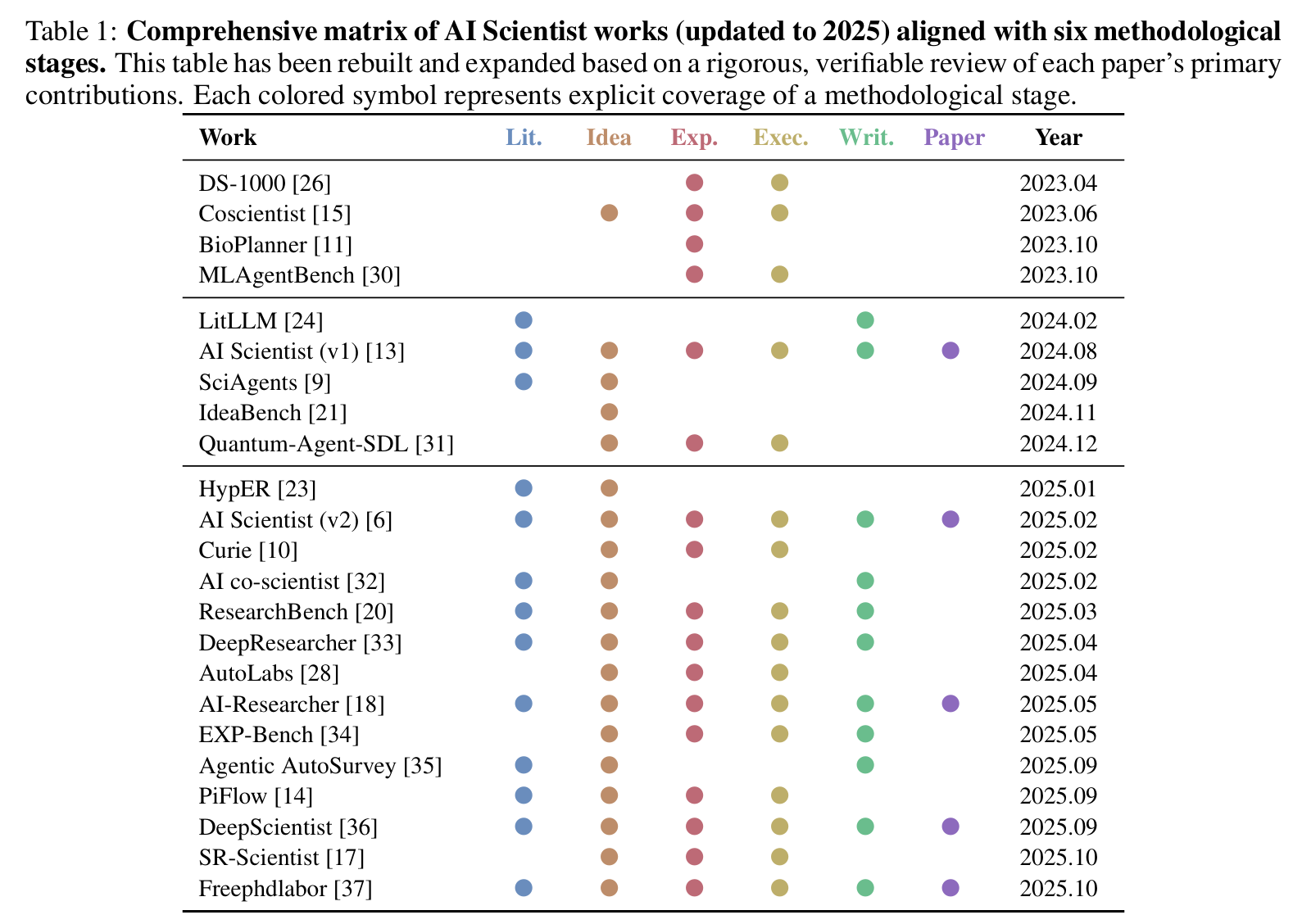
应用领域
AI Scientist 系统现已能够自主生成假设、设计实验、分析数据并产出论文手稿,覆盖多个科学领域。现有实现可分为两个层级:(1)通用 AI Scientist 系统,追求端到端、跨领域的自主性;(2)领域特定的 AI Scientist 系统,专门针对化学、生物学、物理学和元科学等领域。
通用
通用 AI Scientist 系统体现了领域无关的框架,复现完整的科研工作流——从问题表述到实验执行、结果解释和成果传播——既作为发现加速器,也作为探索机器智能的认识论工具。
The AI Scientist v1:采用模块化多智能体架构(规划、编码、分析、写作),由元科学家模块协调,自主选择主题、生成可执行代码、起草论文,并复现经典机器学习研究。
The AI Scientist v2:在 v1 基础上通过智能体树搜索规划推进,动态探索并行假设,通过反思反馈循环评估新颖性和有效性。
AI-Researcher:优先考虑透明度,通过溯源追踪记忆图记录所有产物(代码、数据日志),与 Scientist-Bench 共同开发用于可复现性评估。
Curie:通过因果感知规划循环实现严格的实验控制,在明确因果假设下自动化机器学习假设检验。
化学与材料
化学和材料科学为 AI Scientist 系统提供了成熟的测试平台,通过结构化分子表示、明确定义的协议和自主实验室(SDLs),实现了数字推理与物理实验的闭环集成,支持从头发现。
Coscientist:整合 GPT-4 推理与机器人液体处理系统,自主规划反应、生成控制代码、解释光谱反馈,并迭代优化假设。
A-Lab:结合贝叶斯优化与 LLM 引导的实验设计,每周自主合成和表征数千种新型无机材料。
Robotic AI Chemist:将认知自主性(基于文献的推理)与物理自主性(机器人操作)融合,实现端到端的反应设计与执行。
AutoLabs:部署多智能体自校正循环(规划、控制、安全审计),检测异常并重新校准仪器,提高通量和安全性。
生物医学
生物学和生物医学需要语义解释复杂协议,从噪声高维数据中进行因果推理,目标包括疾病通路发现和药物靶点识别。
BioPlanner:为 LLM 驱动的生物协议设计建立基准,形式化地将研究目标转化为可执行的实验工作流。
LLM4GRN:整合 LLM 推理与生物信息学工具,发现因果基因调控网络,自动化复杂数据分析以推断生物学机制。
Hierarchically Encapsulated Representation:采用分层架构进行多级协议推理(从宏观工作流到微观参数),实现鲁棒的、上下文感知的自主实验室规划。
物理与工程
物理和工程领域通过溯因推理追求基本方程发现——通过数值模拟、符号推理和实时仪器控制的协同集成,从观测数据中提取符号原理。
Agentic Physics Experiments:在粒子加速器设施部署 AI 智能体,通过闭环反馈自主协调数据采集和束线配置,优化校准。
SR-Scientist:采用智能体工作流进行符号回归,从观测数据中自主发现基本方程。
AIFeynman:引入物理约束的符号搜索(量纲一致性),从原始数据中重新发现经典定律,启发现代符号推理架构。
Quantum-Agent-SDL:结合强化学习与基于 LLM 的假设优化,在量子计算中实现自优化的量子比特校准和纠错。
元科学与社会科学
元科学应用分析科学事业本身(映射知识流动、识别范式、评估可复现性),将 AI 系统从研究执行者转变为元研究者,将科学作为复杂自适应系统进行研究。
SciAgents:采用多智能体协作和动态图推理遍历发表/作者网络,识别知识空白、跨学科连接,并预测研究趋势。
AI for Social Science (AI4SS):概述 AI 驱动的大规模社会建模、政策模拟以及创新扩散和协作模式分析的路线图。
Ethical Governance Frameworks:解决 AI 生成科学的社会影响,提出作者管理、信用归属和责任维护的框架。
挑战与解决方案
除了定义部分提到的差异侧重外,二者也具有很多共性。
领域知识注入不足
- 问题表现:LLM 误用统计检验(如对非正态数据使用 t-test)、混淆专业术语(如“precision” vs “positive predictive value”)
- 解决方案:
- RAG 增强:在生成前检索权威来源(如《Statistical Inference》教材、Stack Overflow 高赞回答)
- 微调专用模型:使用 SciBench、BioCoder、DS-1000 等领域代码数据集微调 Code Llama 或 StarCoder
- 规则约束层:在代码生成后应用静态分析器(如 pylint + 自定义规则)拦截常见错误
可复现性保障
- 问题表现:随机种子未固定、依赖版本不明,导致他人无法复现结果
- 解决方案eg:
- 强制在代码开头插入:
1
2
3
4
5
6
7import numpy as np, random, torch
SEED = 42
np.random.seed(SEED)
random.seed(SEED)
torch.manual_seed(SEED)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(SEED) - 自动生成
environment.yml(Conda)或requirements.txt(pip) - 输出完整执行日志,包含 package versions(通过
pip freeze或conda list) - 支持导出 Docker 镜像,实现环境完全封装
- 强制在代码开头插入:
多模态内容处理
- 问题表现:无法解析公式、图表、表格等非纯文本内容
- 技术进展:
- LaTeX 解析:使用 pandoc 或 Mathpix 将公式转为 MathML 或结构化 AST
- 图表理解:集成 Qwen-VL 或 LLaVA,从 matplotlib 输出中提取趋势(如“准确率随 epoch 上升”)
- 表格生成:使用 pandas-styled 或 tabulate 生成符合期刊格式的表格(含 p 值星号标记)
评估体系缺失
- 现状:缺乏统一 benchmark 衡量“科研能力”
- 已有基准:
- DS-1000:1000 个真实数据任务,评估代码正确性、鲁棒性、效率
- ResearchBench:基于“灵感分解”的科研任务链评估(如从文献到假设再到实验)
- EXP-Bench:聚焦实验设计合理性(如对照组设置、样本量功效分析)
- IdeaBench:由领域专家对生成假设的新颖性(novelty)、可行性(feasibility)、影响力(impact)打分(1–5 分)
未来发展
当前,LLM-Based 数据科学智能体已在标准化、确定性高的任务上达到实用水平(如 Kaggle 风格分析),而 AI Scientist 系统正从“演示原型”迈向“可部署科研工具”。未来五年,随着评估体系完善、领域知识深度融合、人机协同机制成熟,AI 将逐步成为科研工作者的可信协作者,而非仅是自动化脚本生成器。其核心价值不在于取代科学家,而在于降低科研门槛、加速知识发现、提升研究可复现性。
可验证研究(Verifiable Research)基础设施
构建端到端可审计的科研流水线,每一步输出附带元数据:- 数据来源哈希(SHA-256)
- 代码版本 ID(Git commit hash)
- 统计检验 p 值与置信区间
- 敏感性分析结果(如不同随机种子下的性能波动)
多智能体科研协作平台
不同专业 Agent 协同工作:- Statistician Agent:负责假设检验设计与功效分析
- Domain Expert Agent:提供领域约束(如“排除非生物可降解材料”)
- Writer Agent:负责语言润色与期刊格式适配
人机协同科研协议
定义标准接口(如 JSON-RPC over WebSocket),允许人类科学家:- 注入先验知识(如“X 机制已被证伪”)
- 审批关键决策(如“是否接受该假设进入实验阶段”)
- 标注错误反馈用于在线强化学习
跨学科知识图谱构建
整合 PubMed、arXiv、USPTO、GitHub、ClinicalTrials.gov 等多源数据,构建统一科研知识底座,支持跨领域类比推理(如“将 NLP 中的 attention 机制迁移到基因调控网络”)。