


一、任务定义与分类体系
目标检测同时解决分类(是什么)与定位(在哪里):对每张图输出若干检测框及类别,常含背景类。与图像分类只给整图一个标签相比,检测需处理多实例与尺度变化。
两阶段(Two-stage):先产生候选区域(region proposals),再对每个区域分类与回归框。一阶段(One-stage):将检测直接做成密集预测 + 回归,典型如 YOLO、SSD。一般两阶段精度与定位略优,一阶段速度与工程部署更友好。
二、R-CNN 系列脉络
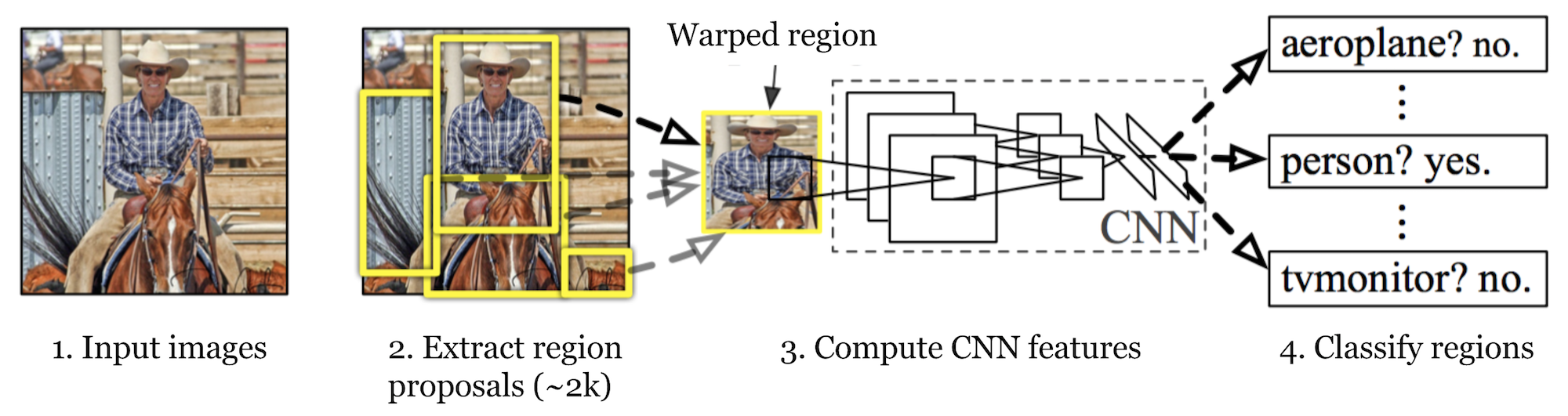
- R-CNN:Selective Search 约 2000 个 proposal $\rightarrow$ 各自 warp 到固定尺寸 $\rightarrow$ CNN 提特征 $\rightarrow$ SVM 分类 + 线性回归修正框。缺点:重复卷积、慢;模块分训,非端到端。
SPP-Net:整图一次卷积得特征图,将 proposal 映射到特征图上,用 空间金字塔池化(SPP) 得到固定长度向量再送全连接,避免对原图重复卷积。
Fast R-CNN:单网络联合训练分类与框回归;ROI Pooling 把各 proposal 对应特征划成 $7\times 7$ 网格做 max pool,得到固定大小;多任务损失为分类交叉熵 + Smooth L1 框回归。瓶颈仍在 CPU 上的 Selective Search。
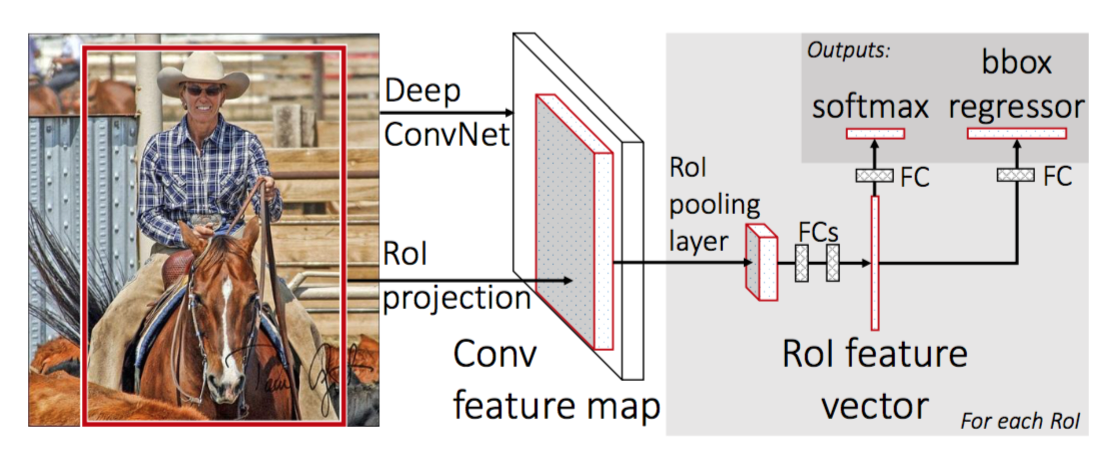
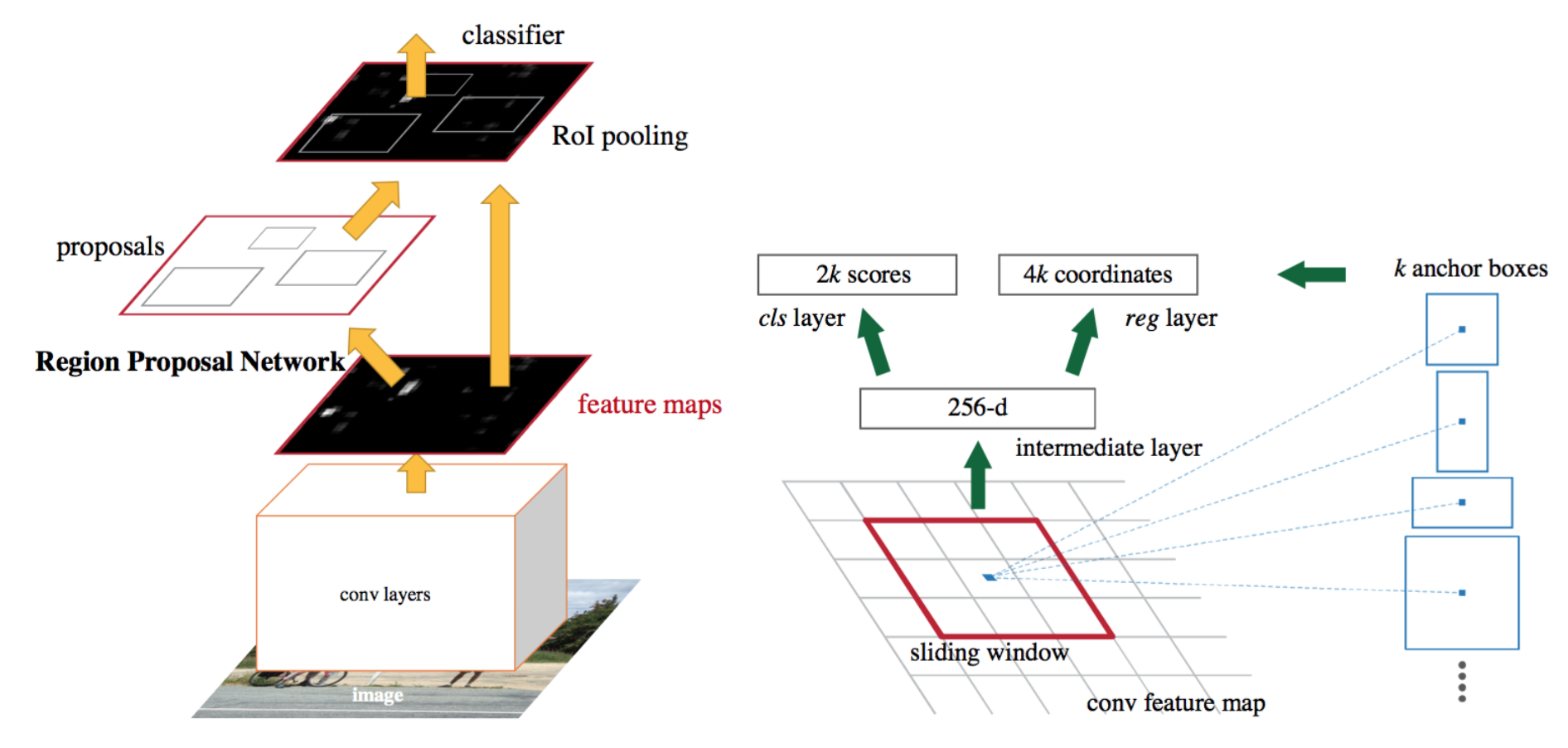
- Faster R-CNN:用 区域提议网络(RPN) 在特征图上滑动小网络,对每个空间位置和 Anchor(多尺度、宽高比预设框)预测「前景/背景」二分类与相对 anchor 的偏移;NMS 后得到 proposal,再经 ROI 头精修。
▸IoU(交并比)
对两框 $A,B$,$\mathrm{IoU}(A,B)=\frac{|A\cap B|}{|A\cup B|}$。训练时常用 IoU 阈值划分正负样本(如 RPN 中 IoU$>0.7$ 为正,$<0.3$ 为负)。
▸Smooth L1
$$\mathrm{smooth}_{L_1}(x)=\begin{cases}0.5 x^2 & |x|<1\ |x|-0.5 & \text{otherwise}\end{cases}$$
在误差大时梯度有界,比纯 $L_2$ 更稳;小误差区接近 $L_2$。
三、Anchor、ROI Pooling 与 ROI Align
Anchor:在特征图每个 cell 上铺 $k$ 个先验框(如 3 尺度 $\times$ 3 宽高比),回归的是相对 anchor 的中心偏移与宽高缩放(具体编码依实现)。
ROI Pooling 的量化误差:proposal 坐标映射到特征图时常向下取整;池化划分网格再次取整,小目标映射回原图误差大。ROI Align(Mask R-CNN 等)用双线性插值按连续坐标采样,避免两次量化,对小物体与实例分割更友好。
四、一阶段方法要点
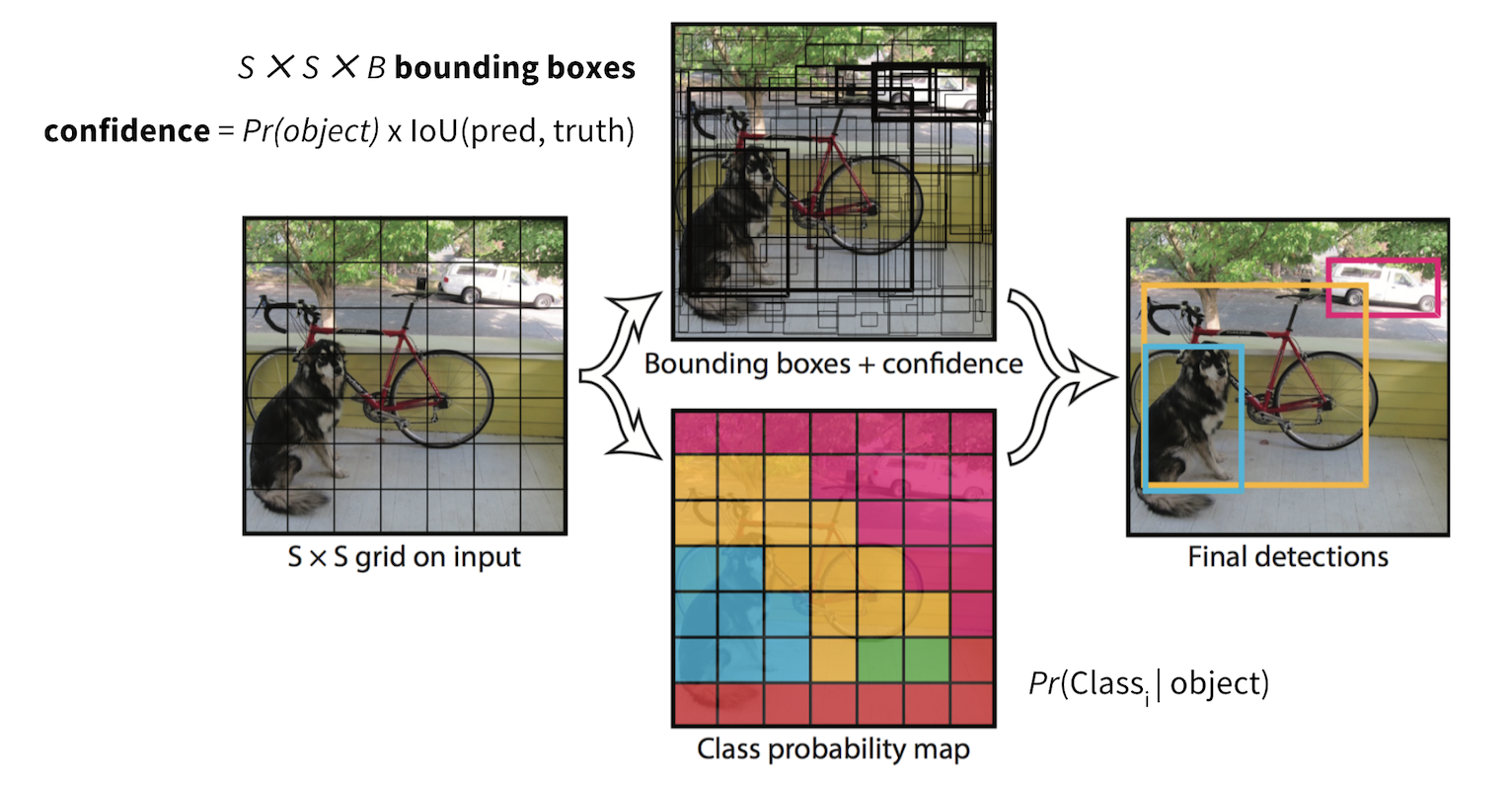
- YOLO(v1 思想):将图像划成网格,每个 cell 负责中心落在其中的目标,预测边界框与类别概率,单次前向完成检测,速度快;早期版本对小物体与密集框处理较弱,后续版本改进骨干、锚框与损失。
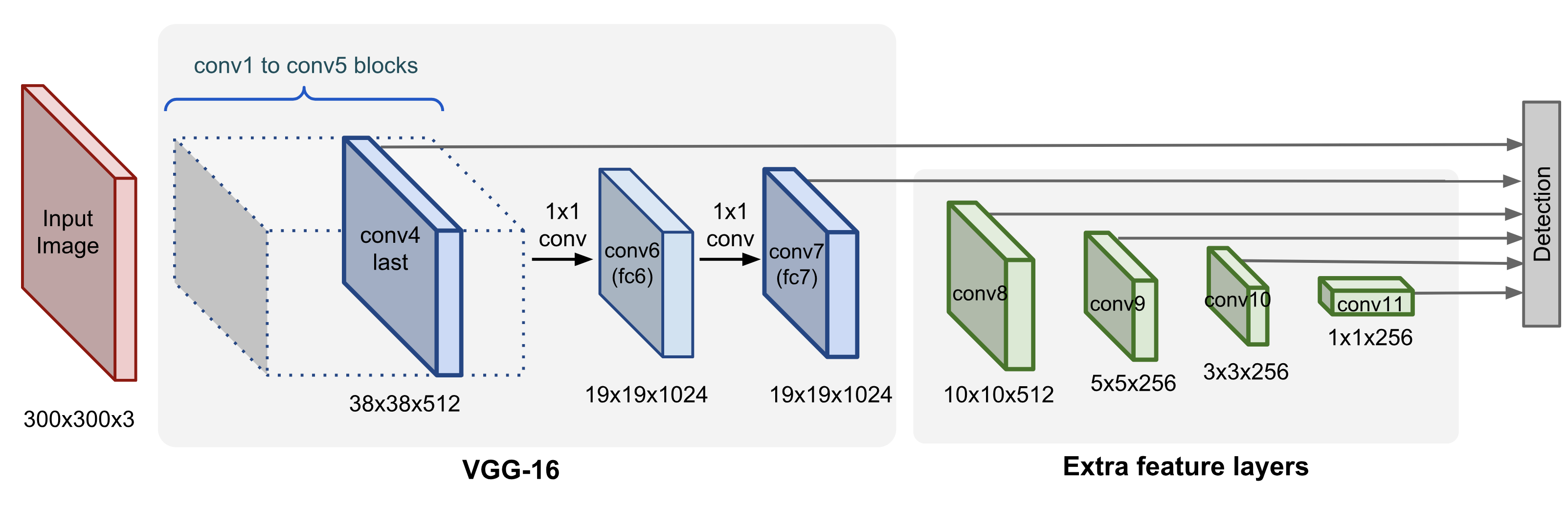
- SSD:在多个尺度的特征图上用卷积做密集检测,浅层特征分辨率高利于小目标,深层语义强;默认框类似 anchor。
- 训练技巧共性:难例挖掘、多尺度训练/测试、数据增强、Focal Loss(缓解前景背景极度不平衡)等。
五、推理后处理
NMS:按得分排序,贪心保留高分框并删除与其 IoU 超过阈值的其他框,减少重复检测。
评价常用 mAP(多类平均精度):在不同 IoU 阈值或 COCO 的 AP、AP50、AP75 等协议下汇总。
六、与分割、关键点
- Mask R-CNN 在 Faster R-CNN 上加并行 mask 分支,ROI Align 保证 mask 对齐,实现实例分割。
七、推导与掌握要点(增补)
- 从分类到检测的多任务损失(Fast/Faster R-CNN)
对每个 ROI(或最终检测头),分类分支用多类 softmax 交叉熵(含背景类);回归分支只对「属于某前景类」的框计算。总损失常写为
$$\mathcal{L}=\mathcal{L}_{\mathrm{cls}}+\lambda,\mathcal{L}_{\mathrm{reg}}.$$
其中 $\mathcal{L}_{\mathrm{reg}}$ 为 Smooth L1 对编码后偏移的均值。RPN 还有二元交叉熵(前景/背景)+ 框回归,与检测头类似但 anchor 更多、正负样本需采样平衡。
▸Smooth L1 对梯度的含义
令 $u$ 为预测与目标的编码差,$\mathrm{smooth}_{L_1}(u)$ 在 $|u|<1$ 内等价 $\frac{1}{2}u^2$,梯度为 $u$;在 $|u|\ge 1$ 时梯度为 $\mathrm{sign}(u)$,绝对值不超过 1。故大误差时不会像纯 $L_2$ 那样梯度爆炸。
- 边界框参数化(常见编码)
设 anchor 中心 $(x_a,y_a)$、宽高 $(w_a,h_a)$,真值框 $(x^{\ast},y^{\ast},w^{\ast},h^{\ast})$。一种编码(Faster R-CNN 类)为
$$t_x=\frac{x^{\ast}-x_a}{w_a},\quad t_y=\frac{y^{\ast}-y_a}{h_a},\quad t_w=\log\frac{w^{\ast}}{w_a},\quad t_h=\log\frac{h^{\ast}}{h_a}.$$
网络预测 $\hat{t}_{\cdot}$,用 Smooth L1$(\hat{t}-t)$。这样不同尺度的 anchor 上回归量数值范围更稳定。
- YOLO v1 网格与责任(便于建立直觉)
将输入划为 $S\times S$ 网格,若某物体中心落在 cell $(i,j)$,则该 cell「负责」该物体。每个 cell 预测 $B$ 个框及置信度 $\mathrm{Pr}(\mathrm{obj})\cdot \mathrm{IoU}$,以及 $C$ 类条件概率。训练时只对「负责」的框计算坐标与分类损失,其余框参与置信度学习。v1 对同一 grid 多目标、小物体有限制,后续版本用多尺度特征与 anchor 改进。
- NMS 步骤(贪心)
对同一类别,按得分降序排列框;取最高分框保留,删除与其 IoU 大于阈值 $\tau$(如 0.5)的框;重复直至无剩余。多类则每类独立做一遍。Soft-NMS 等变体用衰减得分代替硬删除,略提即可。
- mAP 直观
对每一类画 PR 曲线(横轴召回、纵轴精度),曲线下面积即 AP。mAP 为各类 AP 的平均。COCO 还会在 IoU=0.50:0.05:0.95 上平均,更严格。mAP 同时惩罚漏检与重复框,比单纯准确率更适合检测。
- 两阶段 vs 一阶段(损失与采样)
两阶段:RPN 从海量 anchor 中筛 proposal,再精修,正样本相对少但质量高。一阶段:在全部先验上直接分类+回归,类别不平衡严重,故需 Focal Loss、OHEM 等。理解这一点有助于读论文中的采样比例与 loss 权重设计。
八、逻辑脉络(如何把前面几节串起来)
主线:检测 = 在哪儿 + 是什么 $\rightarrow$ 传统两阶段先 proposal 再 分类/回归(R-CNN $\rightarrow$ Fast:单图卷积 + ROI;Faster:RPN 学 proposal)$\rightarrow$ 框与真值用 IoU 匹配,训练用 多任务损失 $\rightarrow$ 推理用 NMS 去重 $\rightarrow$ Mask R-CNN 在框内再分割。一阶段则跳过独立 proposal 模块,把密集 anchor 与检测头合一,读论文时重点看 正负样本定义 与 Focal 等平衡手段。
不要混淆:RPN 的正负(前景/背景)与 检测头各类别 是两件事;anchor 编码 把不同尺度框映射到相近数值范围,与 Smooth L1 搭配是工程惯例,换实现需核对编码细节。
九、分步例题(便于自检)
▸例1:IoU 手算(与 INFO 中定义一致)
设两轴对齐矩形在同一平面,区域 $A$ 面积 4,区域 $B$ 面积 4,交集面积 1,则并集面积 $|A\cup B|=4+4-1=7$,故
$$\mathrm{IoU}(A,B)=\frac{1}{7}.$$
若 $A\subseteq B$ 且面积相等,则 IoU=1;若不相交,IoU=0。训练时用阈值(如 0.5、0.7)划分正负样本,即基于同一公式。
▸例2:中心编码一步(与第七节式子对照)
设某 anchor 宽度 $w_a=10$,真值框宽度 $w^{\ast}=15$,则宽度方向回归目标 $t_w=\log(w^{\ast}/w_a)=\log(1.5)$。网络若预测 $\hat{t}_w=\log(1.5)$,则该维 无误差;Smooth L1 在小残差区呈二次,适合精细回归。中心 $(t_x,t_y)$ 用相对 anchor 宽高的 归一化偏移,使不同尺度 anchor 上数值可比。
▸例3:NMS 示意(与第四节、第七节一致)
同一类三个框得分 0.9、0.8、0.7,两两 IoU 均大于阈值 $\tau$。先保留 0.9,删去与其 IoU$>\tau$ 的框;若剩下第二、第三仍互斥,再保留 0.8 并删 0.7。多类检测时对每个类别独立做一遍,避免不同类框互相抑制。