


一、无监督学习与生成建模目标
典型无监督任务:聚类(如 k-means)、降维(PCA)、特征学习(自编码)、密度估计(拟合 $p_{\mathrm{data}}$)。
生成模型从数据学习 $p_{\mathrm{model}}\approx p_{\mathrm{data}}$,以便采样新样本,并支持补全、超分辨率、强化学习模拟环境等。
分 显式密度(可写归一化密度,如 PixelCNN、VAE 下界)与 隐式(GAN 仅采样,不显式归一化)。
二、PixelRNN / PixelCNN
- 将图像像素展平为序列(如光栅顺序),用链式法则:
$$p(x)=\prod_i p(x_i\mid x_1,\ldots,x_{i-1}).$$
- PixelRNN 用自回归 RNN 建模条件分布,训练串行慢。PixelCNN 用 masked 卷积并行计算条件,训练快,但生成仍需逐步采样像素。
(论文:https://arxiv.org/abs/1606.05328)
- 优点:似然可精确评估;缺点:生成慢,高维图像序列长。
三、自编码与 VAE 思路
自编码器:编码器 $x\to z$,解码器 $z\to\hat{x}$,重构损失(如 MSE)学习表征;确定性瓶颈不能直接得生成分布。
VAE 引入潜变量:先验 $p(z)$(常为标准高斯),生成分布 $p_\theta(x\mid z)$ 与近似后验 $q_\phi(z\mid x)$(常为高斯,参数由网络输出)。
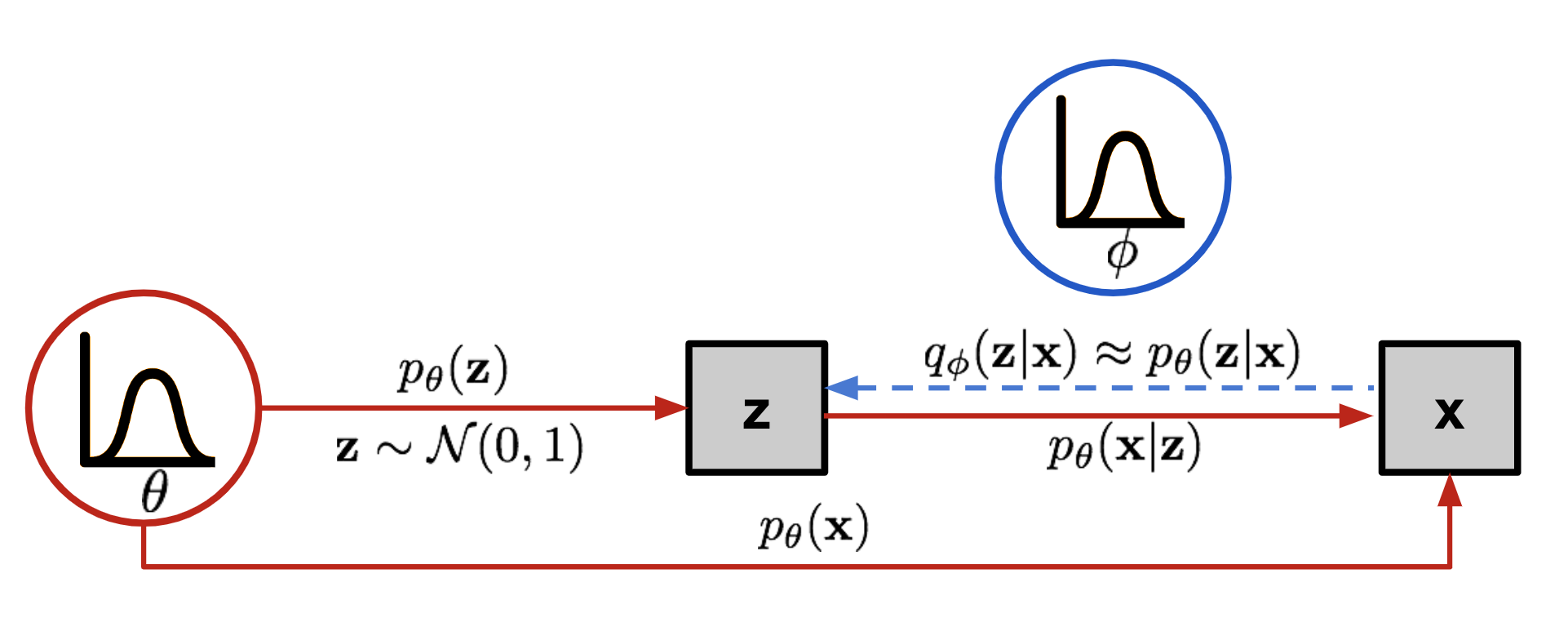
▸ELBO(证据下界)推导要点
$$\log p_\theta(x)\ge \mathbb{E}_{z\sim q_\phi(z\mid x)}[\log p_\theta(x\mid z)]-D_{\mathrm{KL}}(q_\phi(z\mid x),|,p(z)).$$
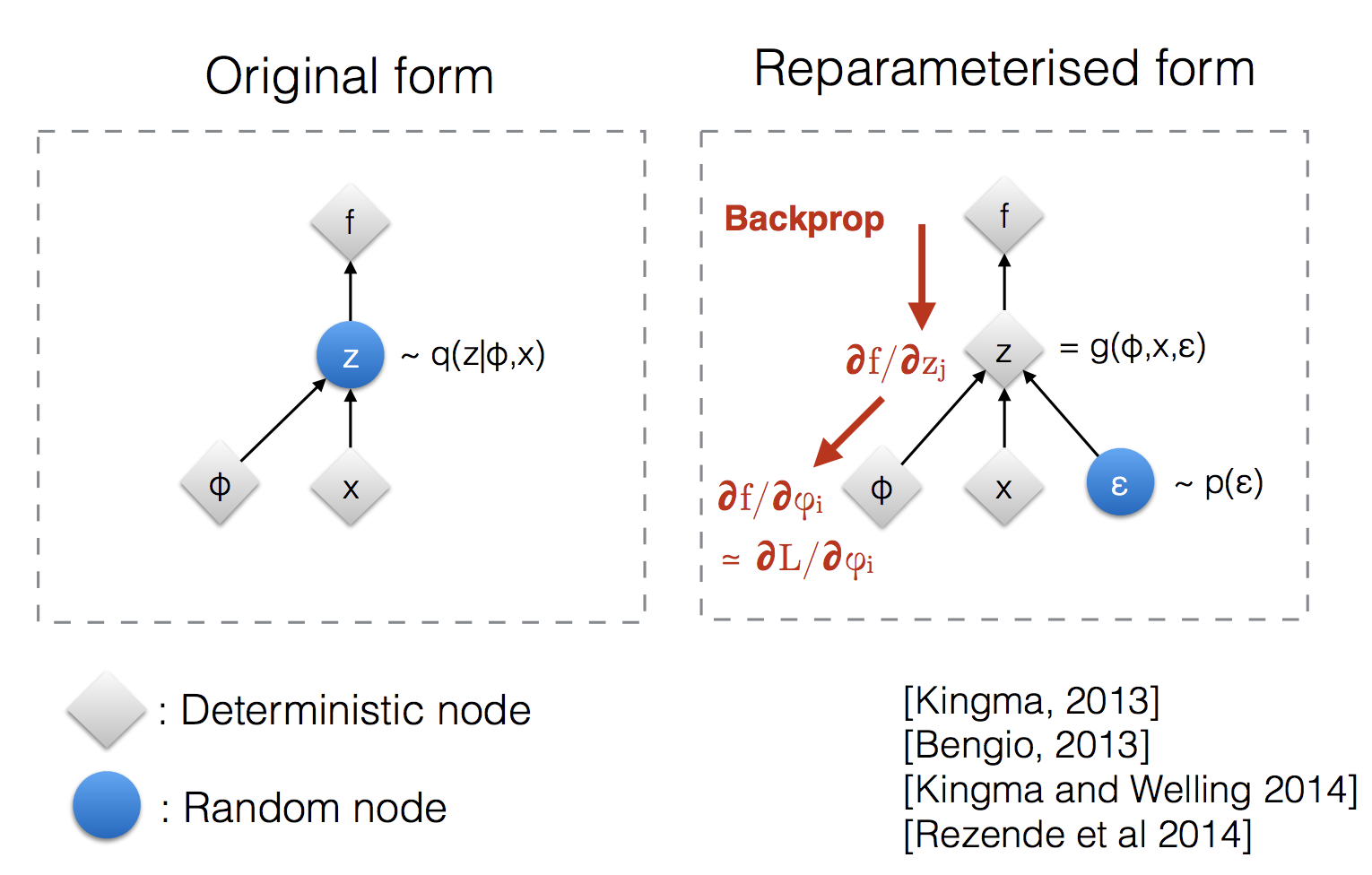
第一项为重构似然期望,第二项使后验接近先验。对 $\log p_\theta(x)$ 的第三项含真实后验 $p_\theta(z\mid x)$,不可解,但因其 KL 非负,前两项之和仍为下界。重参数化:$z=\mu_\phi(x)+\sigma_\phi(x)\odot\epsilon$,$\epsilon\sim\mathcal{N}(0,I)$,使梯度穿过采样。
- 优缺点:可推断 $q_\phi(z\mid x)$ 作表征;生成样本常较糊;似然为下界,不如 PixelCNN 可精确比较。
四、生成对抗网络(GAN)
- 生成器 $G$ 将噪声 $z\sim p(z)$ 映为样本,判别器 $D$ 区分真伪。极小极大目标(标准形式):

$$\min_{\theta_g}\max_{\theta_d}\ \mathbb{E}_{x\sim p_{\mathrm{data}}}[\log D_{\theta_d}(x)]+\mathbb{E}_{z\sim p(z)}[\log(1-D_{\theta_d}(G_{\theta_g}(z)))].$$
生成器早期常用等价目标 $\max_{\theta_g}\mathbb{E}_z[\log D(G(z))]$,减轻梯度消失。
训练:交替更新 $D$ 与 $G$,需平衡二者能力;不稳定时可换 Wasserstein、谱归一化、正则与架构改进等。
优缺点:样本质量常最佳;无显式密度;模式崩溃与训练难度仍是研究热点。
五、三类模型对照
| 类型 | 密度 | 训练 | 样本质量 | 备注 |
|---|---|---|---|---|
| PixelCNN 等 | 显式 | 似然最大化 | 较好,生成慢 | 可评估 NLL |
| VAE | 下界 | ELBO | 偏糊 | 表征与插值好 |
| GAN | 隐式 | 对抗 | 常最优 | 难训、难评估 |
六、与当前研究的关系
- 扩散模型、流模型、自回归 Transformer(如图像 token 化)在工业界已部分取代早期 PixelCNN/GAN 方案,但课程中的脉络仍是理解现代生成系统的基础。
七、推导与掌握要点(增补)
- 自回归似然与训练
对像素 $x_i$(可能含 RGB 多通道,常按扫描顺序展平),模型输出 $p_\theta(x_i\mid x_{<i})$。单张图对数似然
$$\log p_\theta(x)=\sum_i \log p_\theta(x_i\mid x_{<i}).$$
训练即最小化 $-\mathbb{E}_{x\sim\mathcal{D}}[\log p_\theta(x)]$(交叉熵)。PixelCNN 用 mask 保证卷积核只依赖左侧/上方已生成像素,与顺序一致。
- ELBO 推导骨架(VAE)
$$\log p_\theta(x)=\log\int p_\theta(x\mid z)p(z),dz=\log\int q_\phi(z\mid x)\frac{p_\theta(x\mid z)p(z)}{q_\phi(z\mid x)},dz.$$
由 Jensen 不等式或对 $\log$ 下界展开可得
$$\log p_\theta(x)\ge \mathbb{E}_{q_\phi}[\log p_\theta(x\mid z)]-D_{\mathrm{KL}}(q_\phi(z\mid x)|p(z)).$$
也可写成 $\log p_\theta(x)=\mathrm{ELBO}+D_{\mathrm{KL}}(q_\phi|p_\theta(\cdot\mid x))$,最后一项非负,故 ELBO 为 $\log p_\theta(x)$ 的下界。
▸对角高斯 $q_\phi$ 与 $\mathcal{N}(0,I)$ 的 KL 闭式
若 $q_\phi(z\mid x)=\mathcal{N}(\mu,\mathrm{diag}(\sigma^2))$,$p(z)=\mathcal{N}(0,I)$,则
$$D_{\mathrm{KL}}(q|p)=\frac{1}{2}\sum_j\left(\mu_j^2+\sigma_j^2-\log\sigma_j^2-1\right).$$
便于直接对 $\mu,\sigma$ 反向传播,无需蒙特卡洛估计 KL。
- 重参数化技巧
$z=\mu_\phi(x)+\sigma_\phi(x)\odot\epsilon$,$\epsilon\sim\mathcal{N}(0,I)$,则 $\frac{\partial \mathcal{L}}{\partial \phi}$ 经 $z$ 链式传到 $\mu,\sigma$,采样算子无梯度阻塞。
- GAN 与 JS 散度(形式直觉)
固定 $G$ 时最优 $D^{\ast}(x)=\frac{p_{\mathrm{data}}(x)}{p_{\mathrm{data}}(x)+p_G(x)}$。代入原目标可证(在适当条件下)生成器最小化 Jensen–Shannon 散度 $JSD(p_{\mathrm{data}}|p_G)$。实践上需平衡 $D$ 与 $G$ 能力,否则梯度消失或模式崩溃;WGAN 等改用 Wasserstein 距离改善优化几何性质。
- 生成器常用替代损失
$\min_G \mathbb{E}_z[-\log D(G(z))]$ 在 $D$ 很强时梯度更大(错误样本处),缓解原 $\log(1-D)$ 的饱和。二者不严格等价,属于工程上的 non-saturating 启发。
- 三类模型如何选读论文
要可比较 NLL(密度)→ PixelCNN / RealNVP 等;要 潜空间插值与推断 → VAE;要 样本逼真度 → GAN / 扩散。评估生成质量常用 FID(Inception 特征分布距离)、IS 等,与任务相关。
八、逻辑脉络(如何把前面几节串起来)
主线:无标签数据 $\rightarrow$ 想建模 $p(x)$:显式自回归(PixelCNN,可算 NLL)$\rightarrow$ 潜变量 + 难解边缘似然(VAE,用 ELBO 优化下界)$\rightarrow$ 放弃显式密度、改博弈采样(GAN)。三者不是互相否定,而是 权衡:可追踪似然 / 可推断 z / 样本质量。
训练稳定性直觉:PixelCNN 是 标准极大似然,最「像监督」;VAE 要平衡 重构与 KL,$\beta$-VAE 等通过加权 KL 控制解纠缠;GAN 要平衡 D 与 G 能力,否则梯度病态或模式崩溃。读论文时先找 损失项每一项在优化什么。
九、分步例题(便于自检)
▸例1:自回归链式法则(与第二节、第七节 1 对照)
若一维三像素 $x_1,x_2,x_3$,则联合分布分解为
$$p(x_1,x_2,x_3)=p(x_1),p(x_2\mid x_1),p(x_3\mid x_1,x_2).$$
图像按光栅顺序把像素拉成序列,道理相同;PixelCNN 用 mask 保证卷积依赖只来自「已生成」一侧。对数似然为三项对数概率之和,训练时最小化负对数似然。
▸例2:一元高斯 VAE 的 KL 闭式(与第七节 INFO 对照)
设 $q_\phi(z\mid x)=\mathcal{N}(\mu,\sigma^2)$,$p(z)=\mathcal{N}(0,1)$,一维时
$$D_{\mathrm{KL}}(q|p)=\frac{1}{2}\left(\mu^2+\sigma^2-\log\sigma^2-1\right).$$
若 $\mu=0$ 且 $\sigma=1$,则 KL=0:后验与先验一致,此时 重构项 单独承担拟合数据;若 $\sigma\to 0$,KL 中 $-\log\sigma^2$ 项会惩罚过小方差,避免后验坍塌(具体还与实现中的数值下界有关)。
▸例3:GAN 固定 $G$ 时判别器的目标(与第七节 4 对照)
对真实样本项 $\mathbb{E}[\log D(x)]$,希望 $D(x)\to 1$;对生成样本项 $\mathbb{E}[\log(1-D(G(z)))]$,希望 $D(G(z))\to 0$。故 判别器 在标准博弈下是 二分类对数似然;生成器 则试图提高 $D(G(z))$。二者交替时,学习率与每轮 $D$、$G$ 步数需防止一方过强。