


参考资料
- 官方文档: https://www.elastic.co/guide/en/elasticsearch
- 《Elasticsearch 权威指南》
- 《Elasticsearch 实战》
- IK 分词插件: https://github.com/medcl/elasticsearch-analysis-ik
简介
Elasticsearch(简称 ES)是一个基于 Apache Lucene 的分布式搜索与分析引擎。它能够对结构化与非结构化数据进行存储、搜索和实时分析,广泛应用于日志检索、全文检索、监控分析等场景。
Elasticsearch 是 ELK(Elasticsearch、Logstash、Kibana)架构的核心组件。
特点
- 分布式架构:天然支持水平扩展与负载均衡。
- 高可用性:通过主分片与副本机制保证数据安全。
- 实时性强:近实时(Near Real-Time, NRT)搜索和索引。
- 全文检索:基于倒排索引的高效检索机制。
- RESTful API:通过 HTTP + JSON 接口访问。
- 丰富的查询与聚合能力:支持复杂布尔查询、嵌套查询和统计分析。
核心概念
| 概念 | 含义 | 对应关系 |
|---|---|---|
| Cluster | 由多个节点组成的集群 | 数据库实例集群 |
| Node | 集群中的单个实例 | 数据库节点 |
| Index | 存储文档的逻辑集合 | 数据库 |
| Document | 一条 JSON 格式的数据记录 | 数据库表中的一行 |
| Field | 文档的键值对属性 | 数据库字段 |
| Shard | 索引的物理分片单元 | 分区 |
| Replica | 分片的副本,用于容错与高并发 | 数据备份 |
架构与原理
系统架构
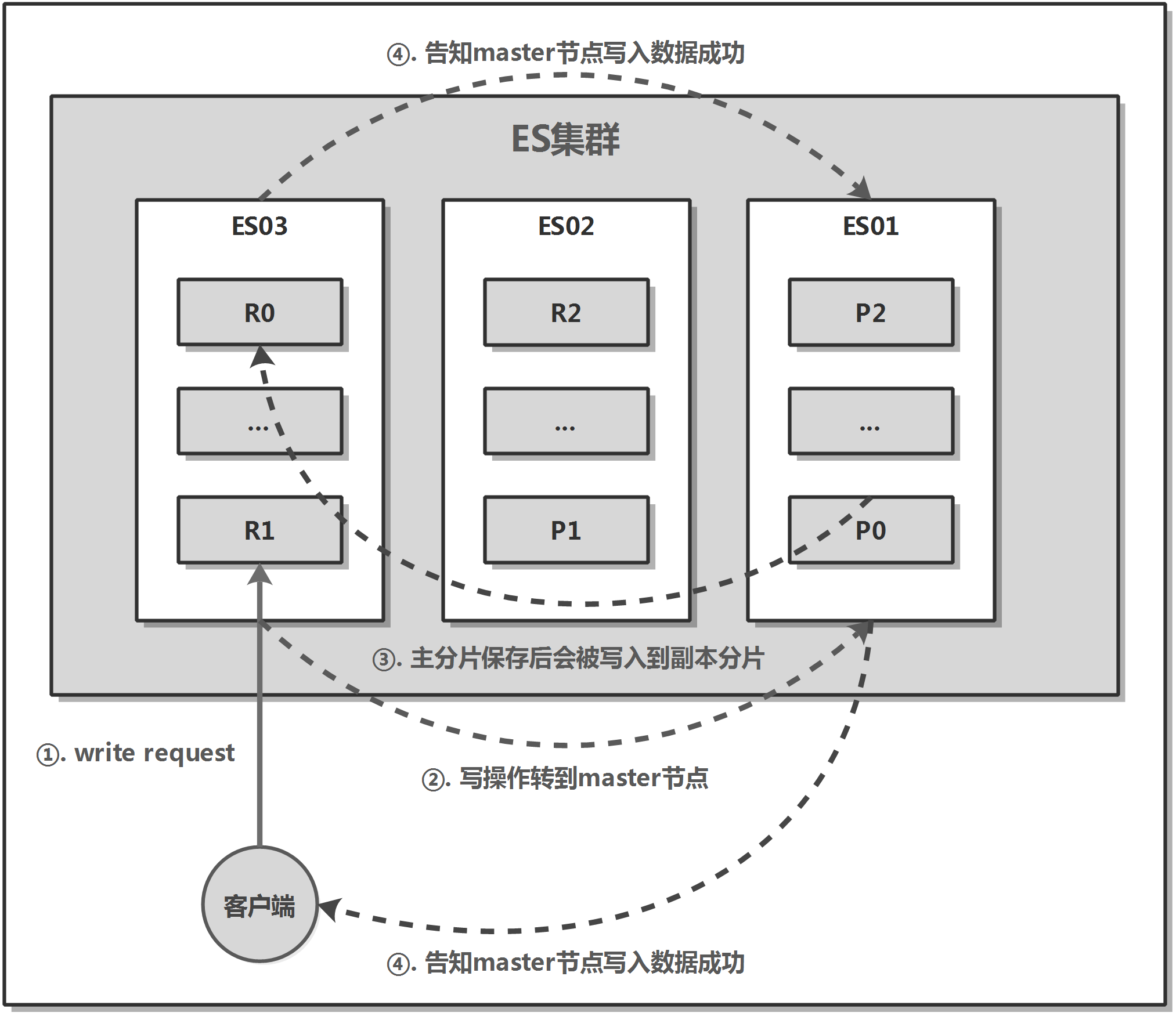
Elasticsearch 集群由多个节点组成。每个节点可能扮演不同角色:
- Master Node:负责管理集群状态、节点分配与索引创建。
- Data Node:负责存储数据、执行查询与聚合。
- Ingest Node:负责数据预处理(如字段提取与转换)。
- Coordinating Node:作为路由层,接收客户端请求并分发给数据节点。
数据以索引(Index)为单位存储。每个索引被划分为若干个主分片(Primary Shard)和副本分片(Replica Shard)。
Elasticsearch 自动管理分片的分布与副本的冗余。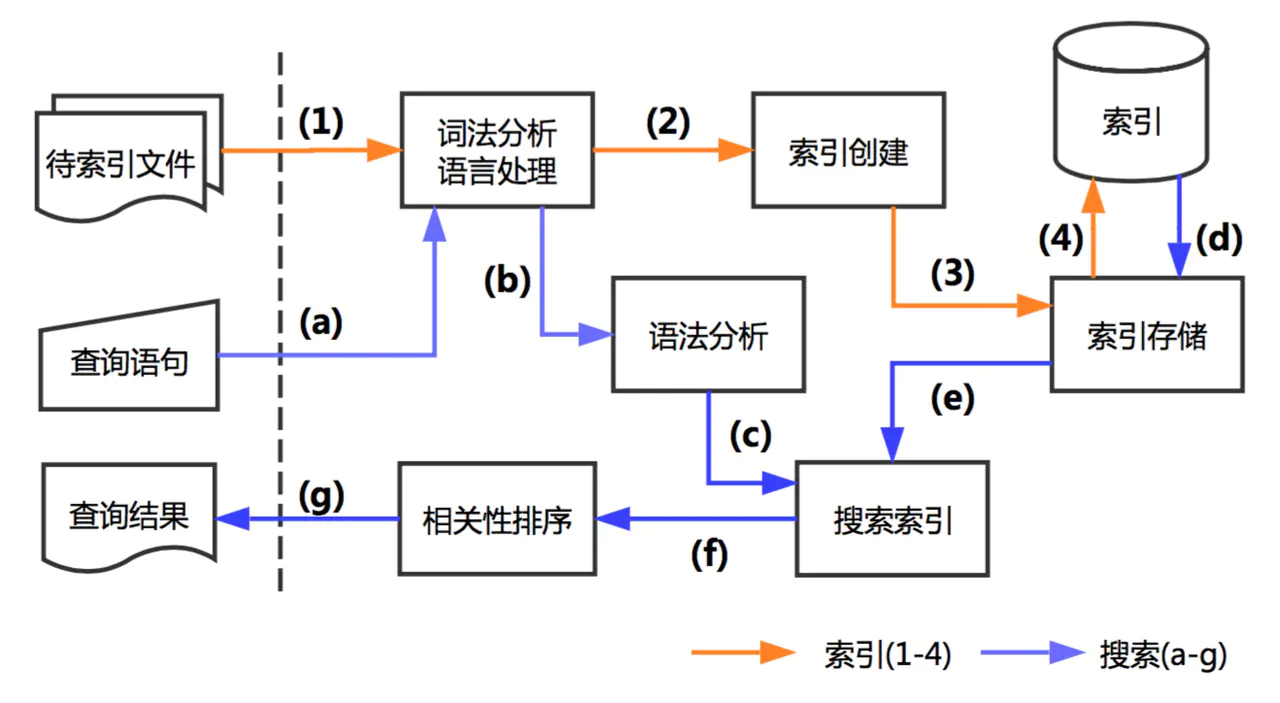
倒排索引原理
Elasticsearch 使用 倒排索引(Inverted Index) 实现高效的全文检索。
构建过程如下:
- 对文档进行分词(Tokenization),提取关键词。
- 将每个关键词映射到出现该词的文档 ID 列表。
- 存储倒排索引表以便快速查询。
例如:
| 文档ID | 内容 |
|---|---|
| 1 | 我喜欢Elasticsearch |
| 2 | 我使用Elasticsearch进行检索 |
倒排索引:
| 关键词 | 文档列表 |
|---|---|
| 我 | [1,2] |
| 喜欢 | [1] |
| Elasticsearch | [1,2] |
| 使用 | [2] |
| 检索 | [2] |
查询时直接根据关键词反查文档列表,从而实现快速匹配。
查询执行流程
- 客户端发送查询请求到协调节点。
- 协调节点将请求广播到包含相关分片的节点。
- 每个分片独立执行查询并返回部分结果。
- 协调节点合并结果、排序并返回给客户端。
安装
环境要求
- 操作系统:Linux / macOS / Windows
- Java 环境:JDK 11+
- 内存:建议至少 2GB
- 端口:默认 HTTP 端口 9200
Linux
下载
1 | wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.15.0-linux-x86_64.tar.gz |
启动
1 | ./bin/elasticsearch |
验证
访问:
1 | http://localhost:9200 |
返回集群信息 JSON 即表示成功。
配置文件说明
(config/elasticsearch.yml)
常用配置项:
1 | cluster.name: my-elasticsearch-cluster |
Windows
访问官方网站:
https://www.elastic.co/downloads/elasticsearch
下载
下载最新 Windows ZIP 版本,例如:elasticsearch-8.15.0-windows-x86_64.zip
解压到安装目录,例如:D:\elasticsearch-8.15.0
配置环境变量
将以下路径添加至系统环境变量 PATH:D:\elasticsearch-8.15.0\bin
启动 Elasticsearch
打开 PowerShell 或 CMD,执行:
1 | cd D:\elasticsearch-8.15.0\bin |
首次启动会自动生成:安全认证 token、访问密码、CA 证书文件(位于 config/certs/)
访问验证
启动完成后,访问:http://localhost:9200
若出现包含版本号与节点名的 JSON 输出,则启动成功。
- 基本操作(REST API):可通过浏览器、Postman 或命令行执行以下 API。
- 查看集群信息
1 | GET http://localhost:9200 |
使用
文档与索引
创建索引
1 | PUT /test_index |
插入文档
1 | POST /test_index/_doc/1 |
查询文档
1 | GET /test_index/_doc/1 |
更新文档
1 | POST /test_index/_update/1 |
删除文档
1 | DELETE /test_index/_doc/1 |
删除索引
1 | DELETE /test_index |
查询与过滤
Match 查询
1 | GET /test_index/_search |
Bool 查询(组合条件)
1 | GET /test_index/_search |
Term 查询(精确匹配)
1 | GET /test_index/_search |
Range 查询
1 | GET /test_index/_search |
聚合分析
(Aggregation)
基本聚合
计算平均年龄:
1 | GET /test_index/_search |
分组聚合
按城市分组统计平均年龄:
1 | GET /test_index/_search |
映射与分词器
自定义映射
1 | PUT /products |
中文分词(IK Analyzer)
安装插件后使用:
1 | GET /_analyze |
集群与分片管理
查看集群健康状态
1 | GET /_cluster/health |
查看分片分布
1 | GET /_cat/shards?v |
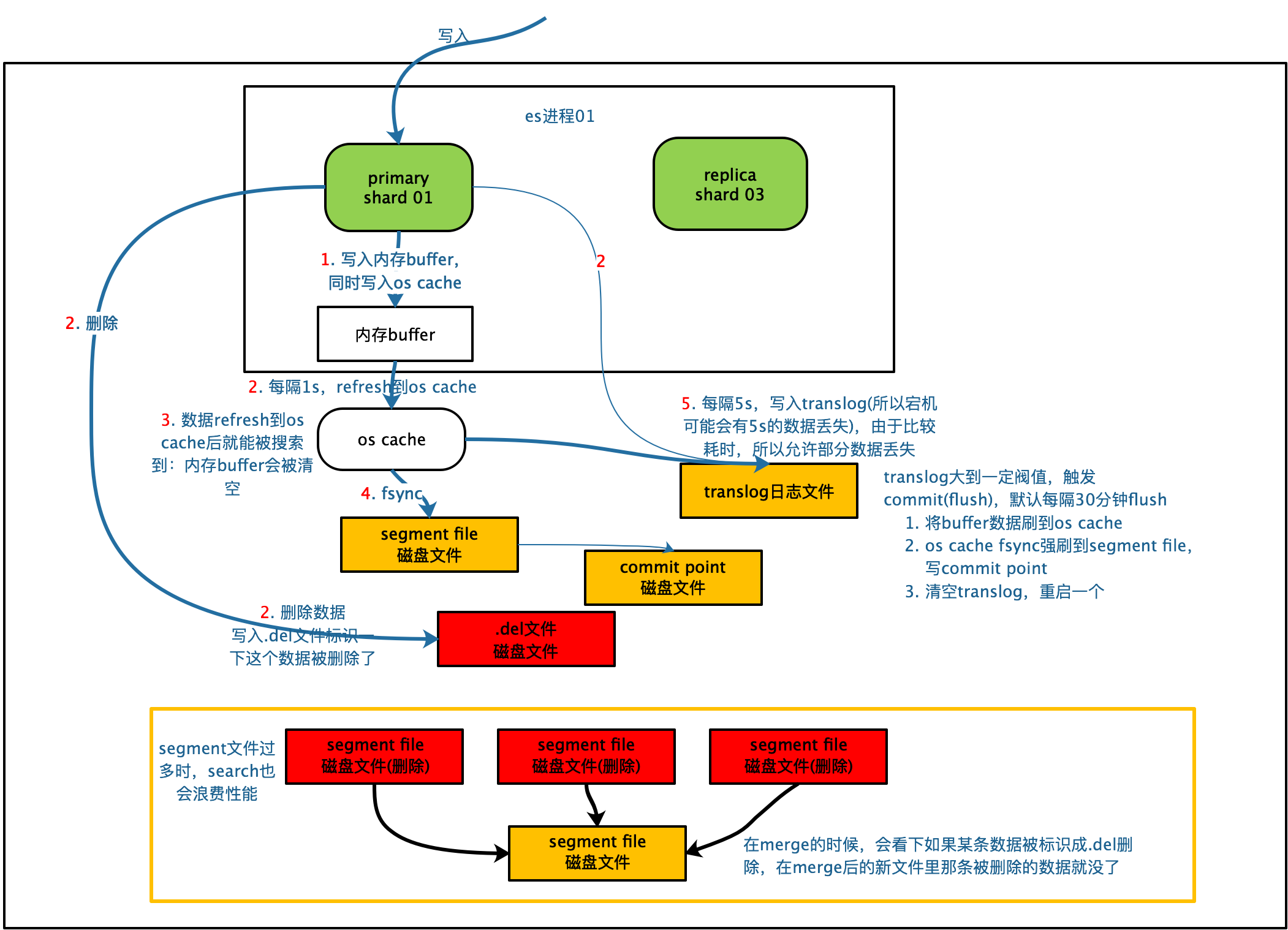
分片与副本机制
- 每个索引由若干主分片(Primary Shard)组成。
- 每个主分片可配置多个副本分片(Replica Shard)。
- 副本既可容灾,又能并行处理查询请求。
性能优化
| 优化方向 | 方法 |
|---|---|
| 分片设计 | 控制分片数量,避免过多小分片 |
| 索引写入 | 使用 _bulk 接口进行批量插入 |
| 查询优化 | 使用 filter 查询以启用缓存 |
| 映射优化 | 明确字段类型,禁用动态映射 |
| 硬件优化 | 使用 SSD 存储,提高 I/O 性能 |
| 内存配置 | 调整 jvm.options 中的 -Xms 和 -Xmx 参数 |
| 集群负载 | 合理规划节点角色,避免单节点压力过大 |
常见问题与解决方法
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 集群状态为 red | 主分片丢失 | 重新分配或重建索引 |
| 查询性能低 | 分片过多或映射不合理 | 优化索引结构与缓存 |
| 中文分词异常 | 未安装 IK 插件 | 安装并配置分词器 |
| 无法启动 | 内存不足或端口冲突 | 调整 JVM 内存配置或端口 |
| 写入失败 | 索引被设置为只读 | 清除 index.blocks.read_only_allow_delete |
- Spark connector 报
NoClassDefFoundError/ scala 版本不匹配:请确认 Spark 的 Scala 二进制版本(spark-submit --version),并选择相应elasticsearch-spark-30_2.12或_2.13以及spark-excel的_2.12/_2.13版本。spark-excel 与 elasticsearch-spark 的版本都要对应 Scala 二进制。([Maven Central][5]) - SSL / self-signed 证书导致连接失败:开发时可临时使用
es.net.ssl.cert.allow.self.signed=true、或在 Python 上用verify_certs=False,或临时关闭 xpack.security(仅限本地测试)。详见 ES-Hadoop 的安全配置文档。([Elastic][7]) - 写入后索引没有出现预期字段类型:请在写入前通过
PUT index明确 mapping,避免动态映射错误。 - 结果分页:ES 默认返回 10 条;若结果多,请用
size或helpers.scan获取全部。
实践应用场景
日志收集与分析(ELK Stack)
- Logstash 负责数据采集与清洗;
- Elasticsearch 负责存储与索引;
- Kibana 提供可视化展示与检索。
电商搜索系统
- 商品索引构建;
- 多条件过滤与排序;
- 热门搜索与推荐统计。
实时监控与告警
- 通过 Metricbeat/Logstash 推送数据;
- Kibana 配置可视化仪表盘;
- Watcher 实现自动告警。
课程作业2
任务1
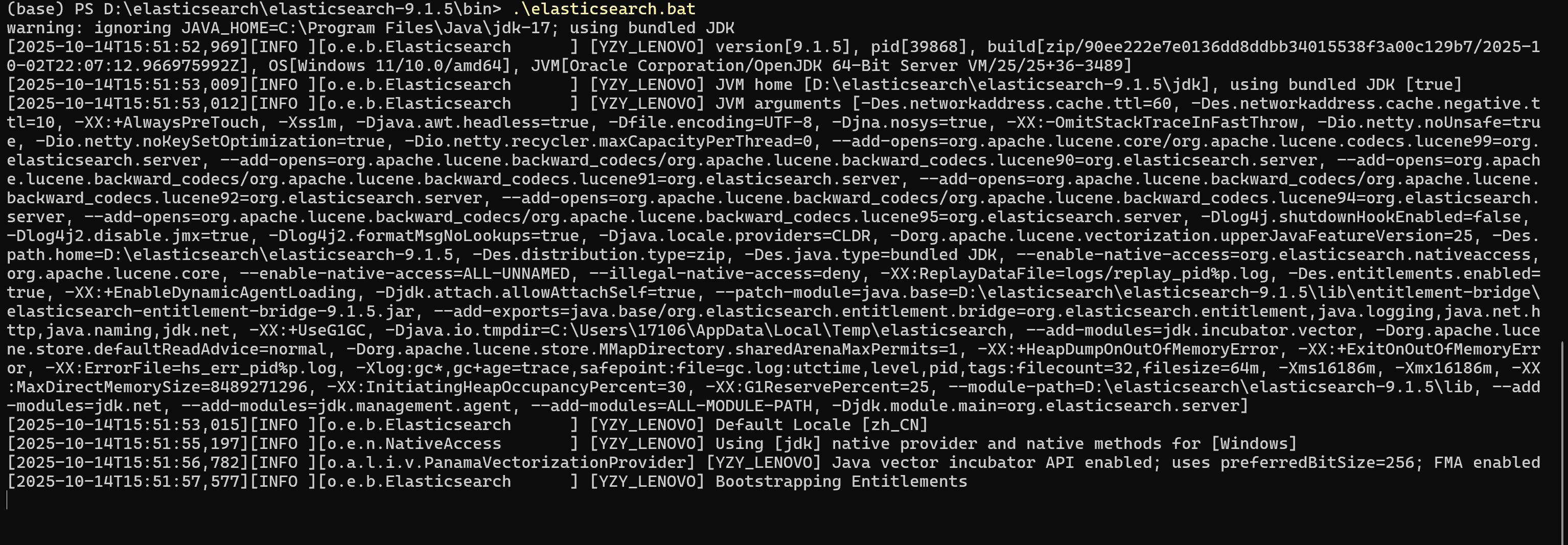
任务1(5分):ElasticSearch安装。在Linux/Windows/Mac(三者里选一个)系统上安装,不要求进行分布式集群配置,只需单机版跑通即可。
提交要求:安装成功后,启动ElasticSearch的屏幕截屏
- 下载 zip(Windows)并解压:
官方下载页面或 Release(选择 8.x 的 zip)。(参考官方安装说明) - 假设解压到
D:\elasticsearch\elasticsearch-9.1.5。进入D:\elasticsearch-9.1.5\bin目录,以管理员身份打开 PowerShell 或 CMD。 - 启动(前台方式,便于截图):
1 | cd D:\elasticsearch\elasticsearch-9.1.5\bin |
- 第一次启动会看到控制台生成 TLS 证书、创建内置账户并显示
elastic的初始密码 / enrollment token(请保存)。
- (可选)如果想安装成 Windows 服务:
1 | .\elasticsearch-service.bat install |
区别:
| 对比项 | elasticsearch.bat |
elasticsearch-service.bat |
|---|---|---|
| 运行模式 | 前台运行,手动启动,依赖当前命令行会话。关闭窗口即停止。 | 后台运行(Windows 服务),系统启动时自动运行。 |
| 运行环境 | 通过 PowerShell / CMD 启动,直接调用 JVM。 | 安装为 Windows Service,由 Windows 服务管理器控制。 |
| 主要用途 | 开发 / 调试 / 学习阶段。方便观察控制台日志、截图或修改配置后测试。 | 生产 / 长期运行环境。无需人工干预即可在后台稳定运行。 |
| 日志输出 | 输出到控制台(stdout),可实时看到启动日志。 | 日志写入 %ES_HOME%\logs 文件夹(如 elasticsearch.log),不显示在控制台。 |
| 停止方式 | 直接关闭窗口或使用 Ctrl + C。 |
使用服务控制命令停止,例如:.\elasticsearch-service.bat stop 或 Windows 服务面板停止。 |
| 安装步骤 | 无需安装,解压即可使用。 | 需先执行 install 安装服务:.\elasticsearch-service.bat install |
| 卸载方式 | 直接删除目录即可。 | 执行 .\elasticsearch-service.bat remove 卸载服务。 |
| 自动启动 | 否(每次手动执行 .bat)。 |
可设置为系统启动自动运行。 |
| 典型使用场景 | 学习、调试、截图、配置验证。 | 长期后台运行(如服务器部署)。 |
服务安装也会在首次运行时显示 enrollment token 与初始密码。
浏览器打开(注意:若启用安全,使用
https://localhost:9200并使用elastic+ 密码登录;浏览器会有自签名证书警告):命令行快速验证(PowerShell):
1 | # 若启用了安全并想跳过证书校验 |
- 屏幕截图要求(Task1 提交):启动控制台(
.\elasticsearch.bat的输出)或curl返回的集群信息页面。

任务2
任务2(6分):将《餐饮外卖商家样本数据》导入到ElasticSearch,并对“被推荐原因”这一列创建索引,然后查询被推荐原因包含“热情”这个关键词的“商家名称”。
提交要求:提交数据查询的代码以及程序运行输出的屏幕截屏,即被推荐原因包含“热情”的所有商家名称。
方案 A
(推荐,使用 Spark + elasticsearch-hadoop)
优点:既利用你已安装的 Spark,又能处理大表;可用 spark-submit 或 pyspark --packages 一次性下载依赖并运行。官方 elasticsearch-hadoop 提供 Spark 支持(使用 -30 位 Spark 3.x),请确保选择与 Spark 的 Scala 版本相匹配(通常 Spark 3.x 对应 elasticsearch-spark-30_2.12 或 _2.13 视你下载的 Spark build)。
- 确认 Spark 的 Scala 二进制版本(很重要)
在 PowerShell 运行:
1 | D:\spark\spark-3.5.7-bin-hadoop3\bin\spark-submit --version |
输出中会提示 Scala 目标(_2.12 或 _2.13),按此选择 connector jar(下面示例按常见的 _2.12 写)。
- 用
spark-submit(或pyspark)带--packages运行(示例)
我例子中使用两份 package:
elasticsearch-spark-30_2.12:8.16.0(用与 ES 8.x 兼容的 es-hadoop 8.16.0)与com.crealytics:spark-excel_2.12:0.13.5(读取 Excel)。如果你的 Scala 版本或 ES 版本不同,请改为对应版本。
在 PowerShell(或 cmd)执行(示例):
1 | D:\spark\spark-3.5.7-bin-hadoop3\bin\spark-submit --master local[2] --packages org.elasticsearch:elasticsearch-spark-30_2.12:8.16.0,com.crealytics:spark-excel_2.12:0.13.5 import_excel_to_es.py |
import_excel_to_es.py(把下面文件保存为该名)
修改
EXCEL_PATH与ES_PASSWORD为你的实际路径和 elastic 密码;若你禁用了安全(xpack.security.enabled: false),将es_scheme改为http并移除用户名/密码项或设为空。
1 | # import_excel_to_es.py |
注意:如果
es.net.ssl报 SSL 验证失败(自签名证书),你有两条路径:
- 推荐:把 ES 的证书导入 JVM truststore / 配置
es.net.ssl.truststore.location等(复杂);- 更简单(本机作业):在
elasticsearch.yml中临时禁用 security(xpack.security.enabled: false),然后用http://localhost:9200无需 ssl/auth 写入(请务必在作业后恢复安全配置)。有关 connector 的 SSL / auth 选项见官方文档。([Elastic][7])
- 创建 index mapping(推荐先创建,以保证
被推荐原因同时有text和keyword字段)
你可以用 curl(PowerShell)或 Python requests/elasticsearch 客户端:
curl(PowerShell)示例(启用 https 且有密码时用 -k -u):
1 | # mapping.json 内容见下 |
mapping.json(示例):
1 | { |
说明:上面把
被推荐原因设为text(便于全文检索)并增加.keyword子字段(便于做 wildcard/精确匹配)。如果你明显需要中文分词(大规模中文检索),需要安装中文分词插件(如 IK 分词器),但作业里只需匹配 “热情” 关键词,match或wildcard足够。
方案 B
(更直观,Python(pandas) + elasticsearch-py)
优点:步骤简单、对 Spark/Scala 版本无关,适合小 文件(数万行以内)。
步骤要点:
pip install pandas openpyxl elasticsearch- 读 Excel(pandas),把每行转成 JSON,使用
elasticsearch客户端bulk()批量索引。 - 建议先用 Python 创建 mapping(同上),再批量写入。
示例(伪代码,真实脚本可给出):
1 | import pandas as pd |
(Python 客户端官方示例与 search/index API 文档)。
查询(“被推荐原因” 包含 “热情” 的所有商家名称)
A python
1 | from elasticsearch import Elasticsearch, helpers |
如果你想更保险(子字段 wildcard):
1 | {"query":{"wildcard":{"被推荐原因.keyword":{"value":"*热情*"}}},"_source":["商家名称"],"size":1000} |
B. curl(PowerShell)
1 | curl -k -u elastic:YOUR_PASSWORD "https://localhost:9200/waimai/_search" -H "Content-Type: application/json" -d '{"query":{"match":{"被推荐原因":"热情"}},"_source":["商家名称"],"size":1000}' |
提交要求(Task2):把查询代码(上面任何一种)和 程序运行输出的屏幕截屏(显示被推荐原因包含“热情”的所有商家名称)。
任务3
任务3(6分):输出月售额>=500的所有商家名称(注:月售1000也符合月售额>=500的查询条件)。
提交要求:提交查询代码以及程序结果运行输出的截屏。
ES DSL 的 range 查询即可。示例 Python:
1 | q = { |
或 curl:
1 | curl -k -u elastic:YOUR_PASSWORD "https://localhost:9200/waimai/_search" -H "Content-Type: application/json" -d "{\"query\":{\"range\":{\"月售\":{\"gte\":500}}},\"_source\":[\"商家名称\"],\"size\":1000}" |
提交要求(Task3):提交查询代码及程序结果的截屏(在控制台显示所有符合条件的商家名称)。
任务4
任务4(3分):(开放题,可借助第三方模型或者大模型)查询在推荐原因中是因为喜欢某个或某些菜品而推荐该商家的记录,输出这些记录对应的“商家名称”和“被推荐原因”。
提交要求:提交编写的代码,程序结果运行输出的截屏。
我给两种实用方法(无需调用外部模型即可完成基本题目)——先试规则方法,再给可选的大模型方法(如果你愿意使用 API)。
方法 A
(规则/关键字匹配 —— 简单、无需外部 API)
用 pandas 读取 Excel,针对 被推荐原因 做正则过滤,关键词示例:喜欢|爱吃|很喜欢|必点|必吃|招牌|推荐菜|主打|特别喜欢|口味|最爱,并可以进一步匹配常见菜名列表(如果你有)。
示例脚本 find_likes.py:
1 | import pandas as pd |
这个方法对作业通常已经够用:输出 商家名称 与 被推荐原因 的行并截图即可。
方法 B
(可选:使用 LLM 对“被推荐原因”逐条分类)
如果你想更智能地识别“是否因喜欢某道菜而被推荐”并抽取菜名,可以把 被推荐原因 逐条发送给 LLM(如 OpenAI)做二分类 + 实体抽取(输出:是否因为喜欢菜品?—是/否 + 列出菜品名称)。示例思路(伪代码):
1 | # 伪代码:需要 openai 包和 API key |
注意:若你使用 LLM,请在报告中说明调用次数、模型、返回示例及如何抽取结果(提交截图时也把调用结果截屏)。