


参考:
基本概念
依存语法是自然语言处理中用于分析句子句法结构的重要方法。与编译器中的解析树类似,NLP中的解析树主要有两种类型:
- 短语结构(Phrase Structure):将句子分解为短语,形成层次化的结构
- 依存结构(Dependency Structure):表示词与词之间的依存关系
依存结构展示了单词之间的依赖关系,表现为从head(被修饰的主题)指向dependent(修饰语)的二元非对称关系。这些依存关系通常形成树状结构,并用语法关系(如主语、介词宾语、同位语等)来标注。
依存树示例
以句子”Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas”为例,其依存树结构如下:
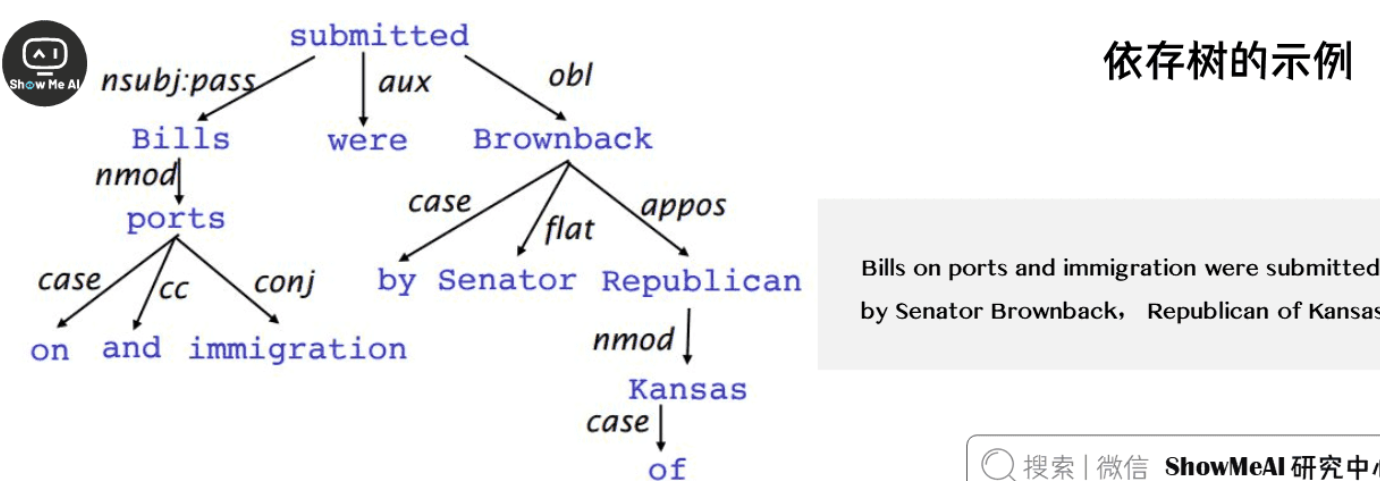
在这个依存树中:
- “submitted”是句子的核心谓语动词,作为根节点
- “Bills”是主语,依赖于”submitted”
- “on ports and immigration”是介词短语,修饰”Bills”
- “by Senator Brownback”是介词短语,表示动作的执行者
- “Republican of Kansas”是同位语,补充说明”Brownback”的身份
依存分析任务
依存分析是将输入句子映射到依存语法树的过程。具体包含两个子问题:
学习问题:给定用依赖语法图标注的句子的训练集D,创建一个可以用于解析新句子的解析模型M
- 输入:带有依存语法标注的句子训练集
- 输出:可用于解析新句子的解析模型
- 目标:学习从句子到依存结构的映射规则
- 方法:可以使用监督学习、半监督学习或迁移学习等方法
解析问题:给定解析模型M和句子S,根据M到S的最优依存语法图
- 输入:解析模型和待分析句子
- 输出:句子的最优依存语法图
- 挑战:需要处理歧义、长距离依赖等问题
- 评估:使用准确率、召回率等指标评估解析质量
基于转移的依存分析
基于转移(Transition-based)的依存分析使用状态机来创建从输入句子到依存句法树的映射。其核心思想是:
- 定义可能的状态转换:系统维护一个状态机,包含所有可能的转换操作
- 根据转移历史预测下一个转换:使用机器学习模型预测下一步操作
- 构建最优的转移序列:通过贪心或动态规划等方法找到最优解
状态机设计
状态机包含:
- 初始状态:所有词都在缓冲区,栈为空
- 中间状态:部分词已处理,形成部分依存树
- 终止状态:所有词都处理完毕,形成完整的依存树
转换预测
预测下一个转换时考虑:
- 当前栈顶的词
- 缓冲区中的词
- 已建立的依存关系
- 上下文信息
大多数 Transition-based 系统不会使用正式的语法。
贪心确定性转移解析
Greedy Deterministic Transition-Based Parsing
由Nivre在2003年提出的系统,包含以下关键组件:
状态State
对于任意句子 $S = w_0, w_1, …, w_n$,一个状态可以描述为一个三元组 $c = (\sigma, \beta, A)$:
- $\sigma$:来自 $S$ 的单词 $w_i$ 的堆(heap)
- $\beta$:来自 $S$ 的单词 $w_j$ 的缓冲区(buffer)
- $A$:一组形式为 $(w_i, r, w_j)$ 的依存弧,其中 $w_i, w_j$ 是来自 $S$ 的单词,$r$ 描述依存关系
因此,对于任意句子 $S = w_0, w_1, …, w_n$:
- 初始状态 $c_0$ 形式为 $( [w_0]_{\sigma}, [w_1, …, w_n]_{\beta}, \emptyset_A )$(只有ROOT在堆中,其他单词都在缓冲区)
- 终止状态形式为 $(\sigma, [ \ ], A)$(缓冲区为空)
转移Transition
在状态之间有三种不同类型的转移:
- SHIFT:移除缓冲区的第一个单词 $w_i$,然后将其放在堆的顶部(前提条件:缓冲区不为空)
- 适用场景:当前堆顶词与缓冲区第一个词之间没有直接依存关系
- 操作效果:减少缓冲区,增加堆
- Left-Arc$_r$:向依存弧集合 $A$ 中加入一个依存弧 $(w_j, r, w_i)$,其中 $w_i$ 是堆顶的第二个单词,$w_j$ 是堆顶的单词。从堆中移除 $w_i$(前提条件:堆必须包含两个单词且 $w_i$ 不是ROOT)
- 适用场景:堆顶词是栈顶第二个词的修饰语
- 操作效果:建立依存关系,移除堆顶词
- Right-Arc$_r$:向依存弧集合 $A$ 中加入一个依存弧 $(w_i, r, w_j)$,其中 $w_i$ 是堆顶的第二个单词,$w_j$ 是堆顶的单词。从堆中移除 $w_j$(前提条件:堆必须包含两个单词)
- 适用场景:堆顶第二个词是堆顶词的修饰语
- 操作效果:建立依存关系,移除堆顶第二个词
公式化定义
- Shift: $\quad (\sigma, w_i|\beta, A) \Rightarrow (\sigma|w_i, \beta, A)$
- Left-Arc$_r$: $\quad (\sigma|w_i|w_j, \beta, A) \Rightarrow (\sigma|w_j, \beta, A \cup {r(w_j, w_i)})$
- Right-Arc$_r$: $\quad (\sigma|w_i|w_j, \beta, A) \Rightarrow (\sigma|w_i, \beta, A \cup {r(w_i, w_j)})$
注:$\sigma$ 表示堆,$\beta$ 表示缓冲区,$A$ 表示依存弧集合,$r$ 表示依存关系类型。
决策过程
- 使用特征模板提取当前状态的特征
- 基于特征预测下一步操作
- 执行预测的操作,更新状态
- 重复直到达到终止状态
神经网络依存解析器
特征选择
模型使用以下特征:
词向量特征
- 使用预训练的词向量(如Word2Vec、GloVe等)
- 捕捉词的语义和上下文信息
- 可以包含词形、词根等形态学特征
词性标注(POS)
- 提供词的语法类别信息
- 帮助识别词的语法功能
- 减少歧义
依存标签
- 表示依存关系的类型
- 提供语法角色信息
- 帮助理解句子结构
模型架构
采用前馈神经网络结构:
输入层:特征向量
- 将离散特征转换为稠密向量
- 使用嵌入层处理不同类型的特征
- 特征拼接形成输入向量
隐藏层:非线性变换
- 使用ReLU等激活函数
- 可以包含多个隐藏层
- 使用dropout等正则化技术
输出层:softmax层,预测转移概率
- 输出每种可能转移的概率
- 使用交叉熵损失函数
- 支持多分类问题
训练过程
使用交叉熵损失函数
- 衡量预测分布与真实分布的差异
- 支持梯度下降优化
- 可以加入正则化项
通过反向传播更新参数
- 计算梯度
- 更新网络权重
- 优化词向量表示
同时优化词向量表示和模型参数
- 端到端训练
- 共享参数
- 提高模型性能
这种基于神经网络的依存解析器相比传统方法具有以下优势:
- 使用稠密特征表示而非稀疏特征
- 自动学习特征表示
- 性能更好,效果更优
- 可以处理复杂的语言现象
- 支持迁移学习
- 适应性强,可以处理不同语言