


机器翻译
机器翻译(Machine Translation, MT)是将一种语言(源语言)的文本自动翻译成另一种语言(目标语言)的过程。这是NLP中最具挑战性的任务之一,因为它需要深入理解源语言和目标语言的语法、语义和文化背景。
早期方法
基于规则的机器翻译
基于规则的机器翻译是最早的机器翻译方法之一,其核心思想是:
- 使用语言学家编写的规则进行翻译
- 需要大量人工工作来制定规则
- 难以处理例外情况和特殊表达
- 维护成本高,扩展性差
- 对语言变化不敏感
这种方法的主要问题是:
- 规则编写耗时且容易出错
- 难以覆盖所有语言现象
- 规则之间可能存在冲突
- 无法处理新出现的语言现象
统计机器翻译
统计机器翻译(SMT)是机器翻译的一个重要里程碑,它基于概率模型进行翻译:
核心思想
- 使用平行语料库(源语言和目标语言的对应文本)
- 基于概率模型学习翻译规则
- 通过最大似然估计优化模型参数
主要方法
IBM模型系列
- IBM Model 1-5
- 从词对齐到短语对齐
- 逐步引入更复杂的特征
基于短语的翻译
- 将句子分解为短语
- 学习短语级别的翻译规则
- 考虑短语重排序
优势
- 数据驱动,不需要人工规则
- 可以自动学习翻译模式
- 对语言变化有更好的适应性
局限性
- 需要大量平行语料
- 翻译结果可能不流畅
- 难以处理长距离依赖
神经机器翻译NMT
基本概念
神经机器翻译使用神经网络直接将源语言句子映射到目标语言句子,是当前主流的机器翻译方法。
神经网络架构称为sequence-to-sequence (又名seq2seq),它包含两个RNNs。
工作原理
- 将源语言句子编码为向量表示
- 使用解码器生成目标语言句子
- 整个过程端到端训练
核心组件
- 词嵌入层:将词转换为向量
- 编码器:处理源语言序列
- 解码器:生成目标语言序列
- 输出层:预测目标词
优势
端到端训练
- 不需要中间步骤
- 直接优化翻译质量
- 减少错误传播
更好的长距离依赖处理
- 通过循环神经网络捕获长距离关系
- 注意力机制提供全局信息
更好的泛化能力
- 可以处理未见过的词组合
- 对语言变化更敏感
更少的特征工程
- 自动学习特征表示
- 减少人工干预
Seq2Seq
基本架构
Seq2Seq(Sequence to Sequence)模型是神经机器翻译的基础架构,由编码器、解码器两个主要部分组成。
将编码器和解码器连起来,就构成了sequence to sequence的架构。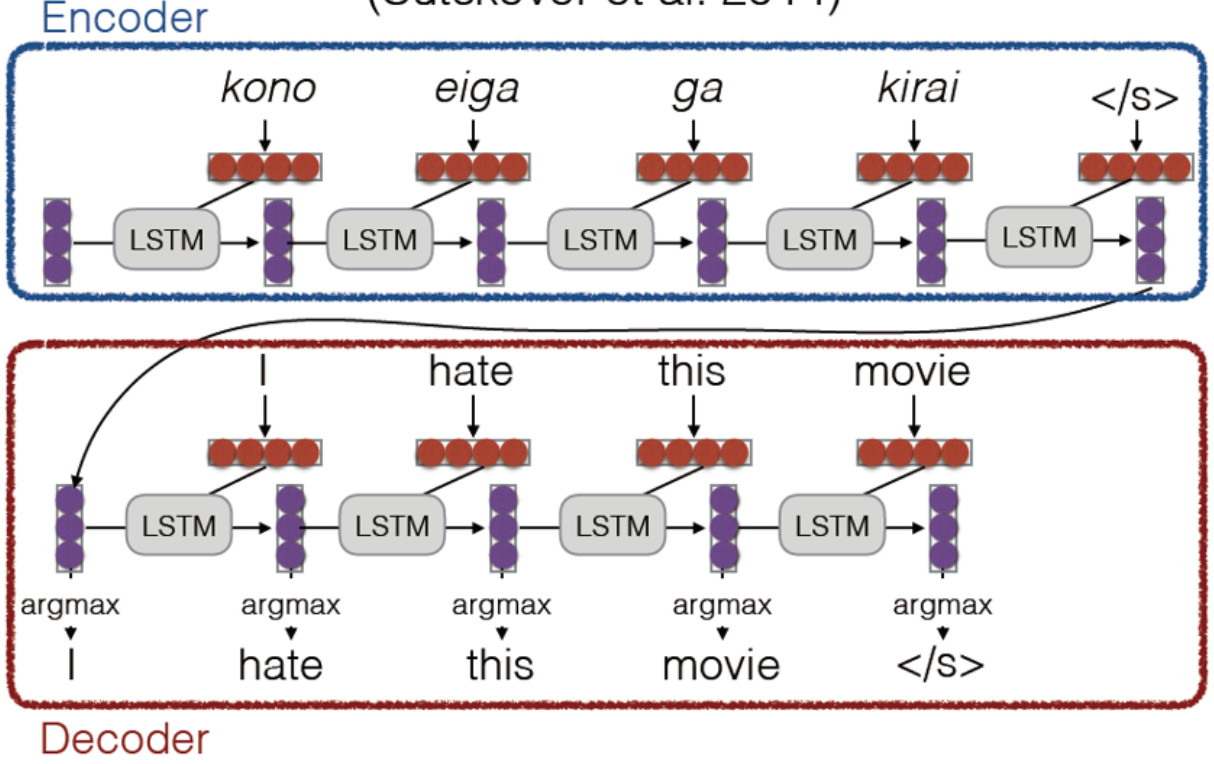
编码器(Encoder)
- 将输入序列编码为固定长度的向量
- 通常使用RNN、LSTM或GRU
- 捕获输入序列的语义信息
- 生成上下文向量
编码器详细结构
词嵌入层
- 将输入词转换为密集向量
- 维度通常为256-512
- 可以预训练或随机初始化
- 使用预训练词向量可以提升性能
- 可以微调或固定词向量
RNN层
- 可以是单向或双向
- 常用LSTM或GRU
- 隐藏状态维度通常为512-1024
- 可以堆叠多层
- 可以使用残差连接
- 可以使用层归一化
输出处理
- 最后一个时间步的隐藏状态作为上下文向量
- 可以连接所有时间步的隐藏状态
- 可以使用注意力机制
- 可以添加额外的投影层
- 可以使用dropout进行正则化
解码器(Decoder)
- 将编码向量解码为目标序列
- 逐词生成输出
- 使用前一个时间步的输出作为当前输入
- 可以访问编码器的信息
解码器详细结构
初始状态
- 使用编码器的最后一个隐藏状态
- 可以添加额外的初始化层
- 可以包含特殊标记(如开始标记)
- 可以使用双向编码器的连接状态
- 可以添加额外的投影层
循环层
- 处理当前输入和前一个状态
- 生成新的隐藏状态
- 可以包含注意力机制
- 可以使用LSTM或GRU
- 可以堆叠多层
- 可以使用残差连接
输出层
- 通常使用softmax
- 预测目标词汇表中的词
- 可以包含额外的投影层
- 可以使用共享权重
- 可以使用温度参数
- 可以使用束搜索
数学表示
对于输入序列 $x = (x_1, …, x_n)$ 和目标序列 $y = (y_1, …, y_m)$:
编码器
$$h_t = f_{enc}(x_t, h_{t-1})$$
其中:
- $h_t$ 是时间步 $t$ 的隐藏状态
- $f_{enc}$ 是编码器RNN单元
- $x_t$ 是输入序列的第 $t$ 个词
- $h_{t-1}$ 是前一个时间步的隐藏状态
具体实现
词嵌入:
$$e_t = E[x_t]$$
其中 $E$ 是词嵌入矩阵RNN计算:
$$h_t = \tanh(W_{xh}e_t + W_{hh}h_{t-1} + b_h)$$
对于LSTM:
$$f_t = \sigma(W_f[h_{t-1}, e_t] + b_f)$$
$$i_t = \sigma(W_i[h_{t-1}, e_t] + b_i)$$
$$o_t = \sigma(W_o[h_{t-1}, e_t] + b_o)$$
$$c_t = f_t \odot c_{t-1} + i_t \odot \tanh(W_c[h_{t-1}, e_t] + b_c)$$
$$h_t = o_t \odot \tanh(c_t)$$双向RNN:
$$\overrightarrow{h}_t = f_{enc}(\overrightarrow{h}_{t-1}, x_t)$$
$$\overleftarrow{h}_t = f_{enc}(\overleftarrow{h}_{t+1}, x_t)$$
$$h_t = [\overrightarrow{h}_t; \overleftarrow{h}_t]$$
解码器
$$s_t = f_{dec}(y_{t-1}, s_{t-1}, c)$$
$$P(y_t|y_{<t}, x) = g(y_{t-1}, s_t, c)$$
其中:
- $s_t$ 是解码器隐藏状态
- $f_{dec}$ 是解码器RNN单元
- $y_{t-1}$ 是前一个时间步的输出
- $c$ 是上下文向量
- $g$ 是输出层函数,通常使用softmax
具体实现
初始状态:
$$s_0 = \tanh(W_{init}h_n + b_{init})$$解码步骤:
$$s_t = \tanh(W_{ys}y_{t-1} + W_{ss}s_{t-1} + W_{cs}c + b_s)$$输出概率:
$$P(y_t|y_{<t}, x) = \text{softmax}(W_{out}s_t + b_{out})$$束搜索:
$$y_t = \argmax_{y \in V} P(y|y_{<t}, x)$$
其中 $V$ 是词汇表
注意力机制
什么是attention?即QKV 模型,transformer 是采用的这种建模方式。
具体看Transformer笔记
为什么需要
注意力机制解决了Seq2Seq模型中的几个关键问题:
信息压缩问题:
- 传统Seq2Seq将整个输入序列压缩为一个固定长度的向量
- 导致信息丢失,特别是对于长序列
- 难以保持所有重要信息
- 无法处理长距离依赖
- 难以捕获局部和全局信息
长序列处理:
- 允许模型关注输入序列的不同部分
- 动态调整关注点
- 提高长序列的翻译质量
- 更好地处理长距离依赖
- 可以捕获局部上下文
对齐问题:
- 帮助模型学习源语言和目标语言之间的对齐关系
- 提高翻译的准确性
- 更好地处理词序差异
- 可以处理一对多、多对一的翻译
- 提高翻译的流畅性
注意力计算
对于每个解码时间步 $t$,注意力权重计算如下:
计算注意力分数
$$e_{ti} = a(Q_t, K_i)$$
其中:
- $e_{ti}$ 是注意力分数
- $Q_t$ 是查询向量(Query)
- $K_i$ 是键向量(Key)
- $a$ 是注意力函数
具体过程
- 计算相似度:
- 点积:$e_{ti} = Q_t^T K_i$
- 加性:$e_{ti} = v^T \tanh(W_1Q_t + W_2K_i)$
- 缩放点积:$e_{ti} = \frac{Q_t^T K_i}{\sqrt{d_k}}$
在缩放点积注意力机制中,最后除以根号 k 是为了稳定训练过程中的梯度。解释如下:
问题:点积的大小会随着向量维度增加而增大:因为点积是多个乘积的和,维度越高,求和的项就越多。随着查询向量 q 和键向量 k 的维度增加,它们的点积 $q^Tk$ 的绝对值也会倾向于增大。
因为 softmax 函数对输入值的大小非常敏感,大的点积会导致 softmax 函数的输出值接近0/1。(看softmax函数图像)
小值——梯度消失:如果点积负值极大,softmax 的输出将接近于零。在反向传播过程中,梯度也会接近于零,导致梯度消失。这使得模型难以学习。
大值——梯度爆炸:如果点积正值极大,softmax 的输出对于一个元素将接近于 1,而对于所有其他元素将接近于 0。这可能导致训练不稳定,并可能导致梯度爆炸。
解决方案:除以根号 k。
- 将点积除以键向量维度 k 的平方根有助于规范化点积的大小。这将值保持在更合理的范围内,防止 softmax 函数产生极端输出。
- 为什么是平方根?
- 平方根缩放基于以下假设:查询向量和键向量的元素是独立的随机变量,均值为 0,方差为 1。在这种情况下,点积的方差大约等于维度 k。除以根号 k会将方差缩放回 1,这有助于稳定梯度。
总之,除以根号k是缩放点积注意力机制中的关键步骤,以防止点积变得太大或太小,这可能导致训练不稳定以及梯度消失/爆炸。它有助于确保 softmax 函数在更稳定的区域中运行,从而使模型能够更有效地学习。
归一化:
- 使用softmax确保权重和为1
- 可以添加温度参数控制分布
- 可以添加掩码处理填充标记
- 可以处理未来信息
多头注意力:
$$e_{ti}^h = a^h(Q_t, K_i)$$
$$e_{ti} = \sum_{h=1}^H W^h e_{ti}^h$$
计算注意力权重
$$\alpha_{ti} = \frac{\exp(e_{ti})}{\sum_{j=1}^n \exp(e_{tj})}$$
其中:
- $\alpha_{ti}$ 是注意力权重
- 使用softmax确保权重和为1
权重计算细节
指数化:
- 将分数转换为正数
- 放大差异
- 处理数值稳定性
- 可以添加温度参数
归一化:
- 确保权重和为1
- 可以添加温度参数
- 可以添加掩码
- 处理数值稳定性
掩码处理:
- 处理填充标记
- 处理未来信息
- 处理注意力范围
- 处理局部注意力
计算上下文向量
$$c_t = \sum_{i=1}^n \alpha_{ti}V_i$$
其中:
- $c_t$ 是上下文向量
- $V_i$ 是值向量(Value)
- 是编码器隐藏状态的加权和
上下文向量应用
与解码器状态结合:
$$s_t = f_{dec}(y_{t-1}, s_{t-1}, c_t)$$用于预测:
$$P(y_t|y_{<t}, x) = g(y_{t-1}, s_t, c_t)$$多头注意力:
$$c_t^h = \sum_{i=1}^n \alpha_{ti}^h V_i$$
$$c_t = \sum_{h=1}^H W^h c_t^h$$
类型
点积注意力
最简单的注意力计算方式:
$$a(Q, K) = Q^TK$$
优点:
- 计算效率高
- 实现简单
- 不需要额外参数
- 内存效率高
- 易于并行化
缺点:
- 对向量维度敏感
- 可能数值不稳定
- 需要向量归一化
- 可能梯度消失
实现细节
计算相似度:
1
scores = torch.matmul(query, key.transpose(-2, -1))
缩放:
1
scores = scores / math.sqrt(d_k)
掩码和softmax:
1
2
3if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(scores, dim=-1)应用注意力:
1
context = torch.matmul(attn_weights, value)
加性注意力
使用前馈神经网络计算注意力:
$$a(Q, K) = v^T\tanh(W_1Q + W_2K)$$
优点:
- 更灵活
- 可以学习更复杂的注意力模式
- 数值稳定性好
- 可以处理不同维度的向量
- 可以添加非线性变换
缺点:
- 计算成本较高
- 需要更多参数
- 内存消耗大
- 训练时间更长
实现细节
投影:
1
2W1_q = self.W1(query) # [batch_size, 1, d_k]
W2_k = self.W2(key) # [batch_size, seq_len, d_k]相加和激活:
1
tanh_output = torch.tanh(W1_q + W2_k)
计算分数:
1
scores = self.v(tanh_output).squeeze(-1)
应用注意力:
1
2attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights.unsqueeze(1), value)
缩放点积注意力
改进的点积注意力:
$$a(Q, K) = \frac{Q^TK}{\sqrt{d_k}}$$
优点:
- 数值稳定性好
- 计算效率高
- 是Transformer中的标准注意力
- 可以处理长序列
- 易于并行化
缺点:
- 需要向量归一化
- 可能梯度消失
- 需要较大的batch size
- 对学习率敏感
实现细节
计算点积:
1
scores = torch.matmul(query, key.transpose(-2, -1))
缩放:
1
scores = scores / math.sqrt(d_k)
掩码和softmax:
1
2
3if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(scores, dim=-1)应用注意力:
1
context = torch.matmul(attn_weights, value)
多头注意力:
多头注意力(Multi-Head Attention)是一种在Transformer模型中被广泛采用的注意力机制扩展形式,它通过并行地运行多个独立的注意力模块(称为”头”)来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语义关联。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def multi_head_attention(query, key, value, num_heads):
batch_size = query.size(0)
d_k = query.size(-1) // num_heads
# 线性投影
q = self.q_linear(query).view(batch_size, -1, num_heads, d_k)
k = self.k_linear(key).view(batch_size, -1, num_heads, d_k)
v = self.v_linear(value).view(batch_size, -1, num_heads, d_k)
# 计算注意力
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, v)
# 合并多头
context = context.view(batch_size, -1, num_heads * d_k)
return self.out_linear(context)
评估指标
机器翻译
BLEU
概念
在机器翻译领域,BLEU(Bilingual Evaluation Understudy)是一种常用的自动评价指标,用于衡量机器翻译的质量。BLEU 分数是通过比较机器翻译的输出和人工翻译的参考译文的 n-gram 相似度来计算的。
参数说明
- $P_n$:n-gram精确率,表示候选翻译中与参考翻译匹配的n-gram比例
- $BP$:长度惩罚因子,用于惩罚过短的翻译
- $c$:候选翻译的长度
- $r$:参考翻译的长度
- $w_n$:n-gram权重,通常取均匀权重(1/N)
- $N$:最大n-gram长度,通常取4
计算方式
计算n-gram精确率
$$P_n = \frac{\sum_{C \in \text{Candidates}} \sum_{n\text{-gram} \in C} \text{Count}_{\text{clip}}(n\text{-gram})}{\sum_{C’ \in \text{Candidates}} \sum_{n\text{-gram}’ \in C’} \text{Count}(n\text{-gram}’)}$$应用长度惩罚

- 计算最终得分
$$BLEU = BP \cdot \exp(\sum_{n=1}^N w_n \log P_n)$$
特点
- 范围:0-100
- 考虑n-gram重叠
- 对长度敏感
- 可以处理多个参考翻译
- 计算效率高
局限性
- 不考虑语义
- 对同义词不敏感
- 可能高估质量
- 对词序不敏感
- 对长句子效果差
改进版本
- BLEU-N:使用不同n-gram权重
- BLEU+:添加语义相似度
- BLEU-S:考虑句子结构
- BLEU-W:加权n-gram匹配
具体实现
1 | def compute_bleu(reference, candidate, max_n=4): |
ROUGE
概念
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一组用于评估文本生成质量(如摘要、翻译等)的指标,主要基于生成文本与参考文本之间的重叠程度计算,核心变体包括ROUGE-N(n-gram重叠)、ROUGE-L(最长公共子序列)、ROUGE-W(加权最长公共子序列)和ROUGE-S(跳跃二元组)。
ROUGE通过量化生成文本与参考文本的相似性来评估质量,其设计初衷是弥补BLEU指标偏重准确率而忽视召回率的缺陷。
主要用于摘要评估,也可用于翻译。
参数说明
- $S$:参考文本集合
- $n\text{-gram}$:n个连续词的序列
- $\text{Count}_{\text{match}}$:匹配的n-gram数量
- $\text{Count}$:总n-gram数量
- $LCS$:最长公共子序列
- $m$:参考文本长度
- $k$:跳跃距离(在ROUGE-S中)
计算方式
ROUGE-N(n-gram召回率)
$$ROUGE\text{-}N = \frac{\sum_{S \in \text{References}} \sum_{n\text{-gram} \in S} \text{Count}_{\text{match}}(n\text{-gram})}{\sum_{S \in \text{References}} \sum_{n\text{-gram} \in S} \text{Count}(n\text{-gram})}$$ROUGE-L(最长公共子序列)
$$ROUGE\text{-}L = \frac{LCS(X,Y)}{m}$$
其中:- $X$ 是候选摘要
- $Y$ 是参考摘要
- $m$ 是参考摘要的长度
ROUGE-W(加权最长公共子序列)
$$ROUGE\text{-}W = \frac{WLCS(X,Y)}{m}$$ROUGE-S(跳跃二元组)
$$ROUGE\text{-}S = \frac{\sum_{k=1}^{n} \text{Count}_{\text{match}}(k\text{-skip-bigram})}{\sum_{k=1}^{n} \text{Count}(k\text{-skip-bigram})}$$
| 指标 | 核心概念 | 适用场景 | 特点 |
|---|---|---|---|
| ROUGE-N | n-gram 匹配 | 翻译、摘要生成 | 强调词汇和短语的覆盖性 |
| ROUGE-L | 最长公共子序列 | 自动摘要、对话生成 | 允许跳跃,注重顺序和语义的相似性 |
| ROUGE-W | 加权最长公共子序列 | 文档摘要、内容生成 | 强调连续匹配,提升流畅性和连贯性 |
| ROUGE-S | 跳跃 n-gram 匹配 | 长文本生成、多文档摘要 | 捕捉长距离依赖,灵活但保持顺序 |
应用场景
- 摘要评估
- 翻译质量评估
- 文本生成评估
- 问答系统评估
- 对话系统评估
特点
优势
- 关注召回率
- 可以评估摘要质量
- 支持多种变体
- 计算效率高
- 易于实现
局限性
- 不考虑语义
- 对同义词不敏感
- 可能低估质量
- 对词序不敏感
- 需要参考文本
具体实现
1 | def compute_rouge_n(reference, candidate, n=2): |
METEOR
更全面的评估指标。支持同义词匹配(如 run 和 running)。结合精确率与召回率,更注重语义相关性。
特点
- 考虑同义词
- 考虑词形变化
- 使用WordNet等资源
- 考虑词序
- 考虑词义相似度
优势
- 更接近人工评估
- 考虑语义相似性
- 对同义表达更敏感
- 考虑词序
- 考虑词形变化
参数说明
- $P$:精确率,表示候选翻译中与参考翻译匹配的词比例
- $R$:召回率,表示参考翻译中与候选翻译匹配的词比例
- $\alpha$:精确率和召回率的权重参数,通常取0.9
- $\gamma$:碎片惩罚参数,用于惩罚不连续的匹配
- $\text{Fragmentation}$:碎片化程度,表示匹配词之间的间隔数
计算方式
词对齐
- 精确匹配
- 词形变化匹配
- 同义词匹配
- 使用WordNet
- 考虑词义相似度
计算分数
$$METEOR = (1 - \gamma \cdot \text{Fragmentation}) \cdot \frac{P \cdot R}{\alpha \cdot P + (1-\alpha) \cdot R}$$
具体实现
1 | def compute_meteor(reference, candidate, alpha=0.9, beta=3.0, gamma=0.5): |
文本生成
cs224n里没有,但是都是评估指标一并记录了。
PPL (Perplexity)
概念
困惑度(Perplexity)是评估语言模型性能的重要指标,用于衡量模型对测试集的预测能力。困惑度越低,表示模型对测试集的预测越准确。
参数说明
- $N$:测试集的词数
- $w_i$:第i个词
- $w_{<i}$:第i个词之前的所有词
- $P(w_i|w_{<i})$:模型预测第i个词的条件概率
- $\log$:自然对数
计算方式
$$PPL = \exp(-\frac{1}{N}\sum_{i=1}^N \log P(w_i|w_{<i}))$$
特点
- 值越小越好
- 可以跨模型比较
- 计算简单
- 不需要参考文本
- 反映模型的不确定性
优势
- 客观性强
- 计算效率高
- 易于理解
- 可比较性强
- 不需要人工标注
局限性
- 不考虑语义
- 对词序敏感
- 可能高估质量
- 对长文本效果差
- 需要完整概率分布
应用场景
- 语言模型评估
- 机器翻译评估
- 文本生成评估
- 模型选择
- 超参数调优
具体实现
1 | def compute_perplexity(model, test_data): |
BERTScore
概念
BERTScore是一种基于BERT的评估指标,通过计算生成文本和参考文本的BERT表示之间的相似度来评估文本生成质量。
参数说明
- $x_j$:参考文本中的第j个词的BERT表示
- $y_i$:候选文本中的第i个词的BERT表示
- $|x|$:参考文本的长度
- $|y|$:候选文本的长度
- $\cos$:余弦相似度
- $P$:精确率,表示候选文本中词的BERT表示与参考文本的匹配程度
- $R$:召回率,表示参考文本中词的BERT表示与候选文本的匹配程度
- $F$:F1分数,精确率和召回率的调和平均
计算方式
获取BERT表示
- 使用BERT模型获取词向量
- 考虑上下文信息
- 使用预训练模型
- 支持多语言
- 考虑语义信息
计算相似度
$$R = \frac{1}{|y|} \sum_{i=1}^{|y|} \max_{j=1}^{|x|} \cos(x_j, y_i)$$
$$P = \frac{1}{|x|} \sum_{j=1}^{|x|} \max_{i=1}^{|y|} \cos(x_j, y_i)$$
$$F = \frac{2PR}{P+R}$$
特点
- 考虑语义相似性
- 使用预训练模型
- 支持多语言
- 考虑上下文
- 计算效率高
优势
- 考虑语义
- 对同义词敏感
- 考虑上下文
- 支持多语言
- 计算效率高
局限性
- 需要预训练模型
- 计算资源要求高
- 对模型依赖性强
- 可能高估质量
- 需要参考文本
应用场景
- 机器翻译评估
- 文本摘要评估
- 对话系统评估
- 文本生成评估
- 问答系统评估
具体实现
1 | def compute_bertscore(candidate, reference, model_name='bert-base-uncased'): |
对比
| 特点 | BLEU | ROUGE | METEOR | PPL | BERTScore |
|---|---|---|---|---|---|
| 考虑语义 | ❌ | ❌ | ✅ | ❌ | ✅ |
| 考虑同义词 | ❌ | ❌ | ✅ | ❌ | ✅ |
| 考虑词序 | ❌ | ✅ | ✅ | ✅ | ✅ |
| 需要参考文本 | ✅ | ✅ | ✅ | ❌ | ✅ |
| 计算效率 | 高 | 高 | 中 | 高 | 低 |
| 多语言支持 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 人工相关性 | 中 | 中 | 高 | 低 | 高 |
使用建议
综合评估
- 建议同时使用多个指标
- 根据任务特点选择合适指标
- 考虑计算资源限制
- 注意指标间的互补性
- 结合人工评估
指标选择
- 机器翻译:BLEU + METEOR + BERTScore
- 文本摘要:ROUGE + BERTScore
- 语言模型:PPL
- 对话系统:BERTScore + METEOR
- 问答系统:ROUGE + BERTScore
注意事项
- BLEU适合评估翻译准确性
- ROUGE适合评估内容覆盖
- METEOR适合评估流畅性
- PPL适合评估语言模型
- BERTScore适合评估语义相似度
实际应用
- 开发阶段:使用计算效率高的指标
- 评估阶段:使用多个指标综合评估
- 发布阶段:结合人工评估
- 研究阶段:使用最新指标
- 生产环境:根据需求选择合适指标
实际应用的挑战
数据问题
平行语料库稀缺:
- 高质量平行语料难以获取
- 领域特定数据不足
- 低资源语言数据缺乏
领域适应:
- 不同领域翻译需求不同
- 专业术语处理
- 风格一致性
低资源语言:
- 数据量少
- 语言资源缺乏
- 评估困难
模型问题
长序列处理:
- 信息丢失
- 计算效率
- 内存限制
罕见词处理:
- 未知词处理
- 低频词翻译
- 专业术语
多语言支持:
- 语言对扩展
- 资源平衡
- 质量保证
解决方案
数据增强:
- 回译
- 同义词替换
- 数据清洗
迁移学习:
- 预训练模型
- 领域适应
- 知识迁移
多任务学习:
- 共享表示
- 任务相关
- 知识共享
预训练模型:
- 大规模预训练
- 微调策略
- 模型压缩