


参考资料
- 官方网站:https://spark.apache.org/
- 官方文档:https://spark.apache.org/docs/latest/
- Spark 源码仓库:https://github.com/apache/spark
- 学习资源:
- 《Learning Spark, 2nd Edition》— O’Reilly
- Databricks Spark 教程
简介
Apache Spark 是一个开源的、基于内存(In-Memory)的分布式大数据计算框架。相比传统的 MapReduce,Spark 通过内存计算显著提升了批处理和迭代计算的性能,同时支持流处理、SQL 查询、机器学习和图计算等多种数据处理模式。
特点:
高性能:Spark 利用内存计算加快任务处理速度,并提供 DAG 调度优化。
多语言支持:提供 Scala、Java、Python (PySpark)、R 接口。
多种运行模式:
- 本地模式(Local Mode):单机多线程。
- Standalone 模式:Spark 自带的集群管理。
- YARN 模式:在 Hadoop YARN 上运行。
- Kubernetes (K8s) 模式:容器化部署。
统一计算引擎:同时支持批处理(Batch)、流处理(Stream)、交互式查询(SQL)、机器学习(ML)和图计算(Graph)等任务。
易扩展性:可水平扩展集群规模,从几台机器到上千台节点。
丰富生态:与 Hadoop、Kafka、Hive、HBase 等无缝集成。
核心概念
RDD(Resilient Distributed Dataset)
概念
Spark 的底层抽象,不可变的分布式数据集合。
简而言之,RDD 就是一个分布在集群中多个节点上的对象集合,你可以在上面执行各种并行计算(比如 map、filter、reduce)。特性:
- 弹性(Resilient):自动处理节点故障。
- 分布式(Distributed):数据分布在集群节点上。
- 数据集(Dataset):可执行并行操作。
操作类型:
- Transformation(转换):如
map、filter、flatMap,惰性执行。 - Action(行动):如
count、collect,触发计算。
- Transformation(转换):如
RDD对象的组成结构
一个 RDD 对象内部包含以下关键属性:
| 属性 | 说明 |
|---|---|
| 分区(Partitions) | RDD 被划分为多个分区,每个分区可在不同节点并行处理 |
| 依赖关系(Dependencies) | 记录当前 RDD 是由哪些 RDD 转换而来(用于容错恢复) |
| 计算函数(Compute Function) | 每个分区的数据如何被计算(map/filter 等) |
| 分区器(Partitioner) | 可选,用于决定键值对 RDD 的分区规则 |
| 存储位置(Preferred Locations) | 提示 Spark 哪些节点已有数据副本(提高 locality) |
RDD创建方式
- 从外部数据创建
1 | # 例子:从本地或HDFS文件中创建 |
- 从集合创建
1 | data = [1, 2, 3, 4, 5] |
- 从其他 RDD 转换得到
1 | rdd2 = rdd.map(lambda x: x * 2) |
DataFrame 与 Dataset
DataFrame:以列为基础的分布式数据集,类似 SQL 表格。
Dataset:结合 RDD 的类型安全和 DataFrame 的优化特性(主要在 Scala/Java 中)。
优点:
- Catalyst 优化器:自动生成高效执行计划。
- Tungsten 内存管理:提升内存和 CPU 使用效率。
- SQL 兼容:支持标准 SQL 查询。
核心组件
Spark Core
功能:任务调度、内存管理、故障恢复、分布式任务执行。
核心概念:
- Driver:负责调度任务和维护应用状态。
- Executor:在工作节点上执行任务,管理数据和计算。
- Task:执行单个计算单元。
- Job:用户提交的计算任务。
- Stage:任务划分为多个阶段,Stage 内部任务可以并行执行。
数据抽象:RDD 是 Spark Core 的基础,所有高级 API 都是基于 RDD 构建的。
Spark SQL
功能:
- 执行结构化数据查询。
- 提供 DataFrame、Dataset API。
- 支持标准 SQL 查询语句。
- 支持 Hive 表和 Parquet、ORC 等多种文件格式。
特点:
- Catalyst 优化器:自动生成优化执行计划。
- 与 BI 工具集成,便于做报表和分析。
示例:
1
2
3
4
5
6
7from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("SparkSQLExample").getOrCreate()
df = spark.read.json("people.json")
df.show()
df.createOrReplaceTempView("people")
spark.sql("SELECT name, age FROM people WHERE age > 20").show()
Spark Streaming
功能:处理实时流数据,如日志、消息队列(Kafka)等。
处理方式:
- DStream(离散流):将实时数据切分为微批(Micro-Batch)。
- 支持窗口操作、状态管理。
集成:
- 可以与 Kafka、Flume、Kinesis 等消息队列结合。
- 输出结果可写入 HDFS、数据库或外部系统。
MLlib(机器学习库)
功能:
- 提供常用的机器学习算法:分类、回归、聚类、协同过滤等。
- 提供特征工程工具:特征提取、转换、选择、标准化等。
- 支持管道(Pipeline)管理。
特点:
- 分布式计算能力强,适合大规模数据训练。
- 与 DataFrame API 紧密结合,方便集成数据处理和模型训练。
GraphX(图计算库)
功能:
- 分布式图计算框架,支持图的构建、计算和查询。
- 提供 PageRank、Connected Components 等图算法。
特点:
- RDD 基础构建,支持图的并行处理。
- 可结合 Spark SQL 和 MLlib 做复杂分析。
工作流程
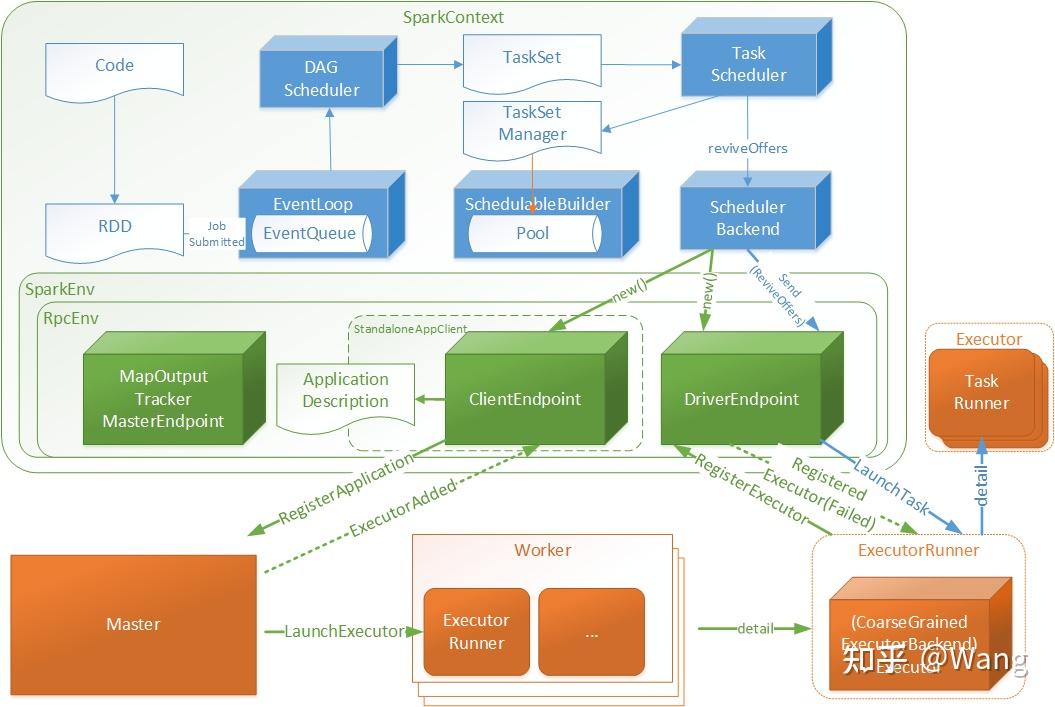

工作原理
Apache Spark 的核心是 基于内存的分布式计算引擎。其执行逻辑可以概括为以下几个步骤:
应用提交(Application Submission)
用户通过spark-submit或 Spark Shell 提交作业(Application),指定作业的代码和依赖。Driver 程序
Driver 是 Spark 应用的控制中心,负责:
- 创建 SparkContext / SparkSession
- 维护应用状态
- 将用户代码转换成计算任务
- 与集群管理器通信申请资源
集群管理器(Cluster Manager)
- Spark 支持多种集群管理模式:Standalone、YARN、Mesos、Kubernetes。
- 集群管理器负责分配 Executor 资源(工作节点上的 JVM 进程)。
Executor(执行器)
Executor 是在工作节点上运行的进程:
- 执行任务(Task)
- 存储计算结果和中间数据
- 与 Driver 通信反馈状态
任务(Task)与阶段(Stage)
Driver 将作业(Job)划分为一个或多个 Stage。
Stage 内部包含多个 Task,可在集群节点并行执行。
Stage 划分依据:RDD 的 窄依赖(Narrow Dependency) 与 宽依赖(Wide Dependency)
- 窄依赖:一个 partition 只依赖上游一个 partition → 可并行计算
- 宽依赖:一个 partition 依赖上游多个 partition → 需要 Shuffle
执行逻辑流程
下面以 DataFrame/RDD 为例说明 Spark 的计算流程:
步骤 1:创建数据源
- 从 HDFS、Hive、JSON、Parquet 等读取数据
1 | df = spark.read.json("people.json") |
- 此时只是创建 逻辑执行计划(Logical Plan),还没有真正计算。
步骤 2:转换操作(Transformation)
- 用户对 RDD/DataFrame 做 map/filter/join 等操作
1 | adults = df.filter(df.age > 18) |
特点:
- 惰性执行(Lazy Evaluation):不会立即计算
- Spark 会把所有 Transformation 构建成 DAG(有向无环图)
步骤 3:行动操作(Action)
- 用户触发 collect、count、show 等操作
1 | adults.show() |
特点:
- 才会触发 DAG 的 物理执行计划(Physical Plan)
- Driver 根据 DAG 划分 Stage
- 生成 Task 发送给 Executor
步骤 4:Shuffle & 任务调度
窄依赖:Task 可独立执行,不需要数据重分区
宽依赖:Task 需要 Shuffle,Executor 会将中间数据写入磁盘/网络传输
Task 调度:
- Driver 按 Stage 拆分 Task
- Task 分发到各 Executor 执行
- Executor 执行计算并返回结果给 Driver
步骤 5:结果返回
Action 完成后,Driver 收集结果:
- 写入外部存储(HDFS、数据库、Kafka)
- 返回给用户(collect/show)
内部逻辑结构
| 层次 | 作用 | 示例组件 |
|---|---|---|
| 应用层 Application | 用户提交 Spark 程序 | Driver、SparkContext |
| 核心调度 Core | 任务划分、DAG 调度 | DAG Scheduler、Task Scheduler |
| 执行层 Executor | 具体计算执行、存储中间数据 | Task、Shuffle、Block Manager |
| 数据抽象 RDD/DataFrame | 分布式数据管理、转换逻辑 | RDD、DataFrame、Dataset |
| 计算优化 | 提高性能、减少 I/O | Catalyst Optimizer、Tungsten Execution |
数据流示意图
1 | 用户代码 (Driver) |
核心特点
- 惰性计算:Transformation 不立即执行,优化 DAG。
- DAG 调度:比 MapReduce 更灵活高效。
- 内存计算:减少磁盘 I/O,加速迭代计算。
- 容错机制:RDD 可通过 lineage(血统)重算丢失分区。
- 分布式并行:Stage 内任务可并行执行,提高集群利用率。
应用场景
- 日志分析、实时监控。
- ETL 数据处理与数据仓库构建。
- 推荐系统、广告点击预测。
- 金融风控与风险计算。
- 社交网络图分析。
进阶学习方向
- Spark SQL 优化 (Catalyst Optimizer)
- DataFrame vs RDD 性能比较
- Spark Streaming 实时数据流
- MLlib 机器学习管线
- GraphX 图计算
- 在集群上部署 Spark (YARN/K8s)
安装
系统要求
- 支持的操作系统:Windows / macOS / Linux
- 需要安装:
- Java 8 或以上版本
- Python 3.7+(用于 PySpark)
- Scala 2.12+(如果使用 Scala)
- Hadoop 可选(用于集群或 HDFS 存储)
检查依赖
1 | java -version |
Windows
- 步骤 1:安装 Java
打开官网 https://www.oracle.com/java/technologies/downloads/
下载并安装 Java 8 或 11 (JDK)。
安装完成后,在命令行(Win+R → 输入 cmd)中输入:
1 | java -version |
如果能看到版本号(例如 java version “1.8.0_371”),说明成功。
- 步骤 2:安装 Spark
前往 Apache Spark 官网下载页面:
🔗 https://spark.apache.org/downloads.html
下载配置:
Choose Spark release: 3.5.0 (or latest)
Package type: Pre-built for Apache Hadoop 3
下载 .tgz 文件后,用 7-Zip 或 WinRAR 解压到一个目录(例如:C:\spark\spark-3.5.0-bin-hadoop3)。
- 步骤 3:安装 Hadoop Winutils
下载 Hadoop Windows 工具包:
🔗 https://github.com/steveloughran/winutils
进入与 Spark Hadoop 版本对应的文件夹(如 hadoop-3.2.2),下载整个文件夹。
放到:
C:\hadoop\bin\winutils.exe
- 步骤 4:设置环境变量
打开系统环境变量(搜索“编辑系统环境变量”)→“环境变量”:
1 | 变量名 值 |
Linux/MacOS
安装 Java(JDK)
Windows / macOS / Linux 通用方式
下载并安装 OpenJDK:
1 | # Ubuntu |
设置环境变量:
1 | export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 |
- 安装 Spark
从官网下载安装包:
访问 https://spark.apache.org/downloads.html
推荐配置:
- Spark version: 3.5.x(或最新稳定版)
- Package type: Pre-built for Apache Hadoop 3.3 and later
- Download type: Direct Download
- 下载后解压:
1 | tar -xvzf spark-3.5.0-bin-hadoop3.tgz |
- 环境变量配置
在 ~/.bashrc 或 ~/.zshrc 末尾添加:
1 | export SPARK_HOME=/usr/local/spark |
保存后执行:
1 | source ~/.bashrc |
验证安装
运行以下命令:
1 | spark-shell |
出现类似:
1 | Spark context Web UI available at http://localhost:4040 |
表示安装成功。
退出 shell:
1 | :quit |
使用
配置文件说明
配置路径:$SPARK_HOME/conf
常用配置:
spark-env.sh:环境变量(如 JAVA_HOME、PYSPARK_PYTHON)spark-defaults.conf:默认参数(如 master、driver-memory)log4j2.properties:日志配置
示例(spark-defaults.conf):
1 | spark.master local[*] |
运行 PySpark
PySpark: Python 交互式模式
1 | pyspark |
示例:
1 | from pyspark.sql import SparkSession |
输出:
1 | +---+-----+ |
提交 Spark 应用程序
将 Python 文件保存为 example.py:
1 | from pyspark.sql import SparkSession |
使用 spark-submit 运行:
1 | spark-submit example.py |
- 使用
spark-submit提交应用到集群:
1 | spark-submit \ |
Spark Web UI
启动任务后,可访问:
默认端口:
http://localhost:4040显示内容:
- Job、Stage、Executor 信息
- 存储与内存使用情况
Spark 运行模式
| 模式 | 启动命令 | 说明 |
|---|---|---|
| Local | spark-shell --master local[*] |
单机多线程模式 |
| Standalone | start-master.sh, start-worker.sh |
Spark 自带集群模式 |
| YARN | --master yarn |
Hadoop 集群上运行 |
| Kubernetes | --master k8s://... |
在 K8s 集群上运行 |
Standalone 集群模式示例
1 | # 启动 master |
运行任务:
1 | spark-submit --master spark://<master-ip>:7077 example.py |
Spark 与 Jupyter Notebook 集成
安装依赖:
1 | pip install findspark pyspark |
在 Notebook 顶部添加:
1 | import findspark |
验证:
1 | df = spark.createDataFrame([(1, "apple"), (2, "banana")], ["id", "fruit"]) |
数据分析简例
1 | from pyspark.sql import SparkSession |
输出:
1 | +-----+----------+ |
常见问题与解决
| 问题 | 原因 | 解决方案 |
|---|---|---|
JAVA_HOME not set |
环境变量缺失 | 在 spark-env.sh 设置 JAVA_HOME |
pyspark: command not found |
PATH 未配置 | 将 $SPARK_HOME/bin 添加到 PATH |
Connection refused (localhost:4040) |
UI 已占用端口 | 使用 --conf spark.ui.port=4050 |
| 内存不足错误 | 数据量过大 | 增加 driver/executor 内存 |
课程作业1
课程作业1—Spark安装及使用
任务1
任务1(5分):Spark安装。在Linux/Windows/Mac(三者里选一个)系统上安装Spark,不要求进行分布式集群配置,只需单机版跑通即可。
提交要求:安装成功后,启动Spark的屏幕截屏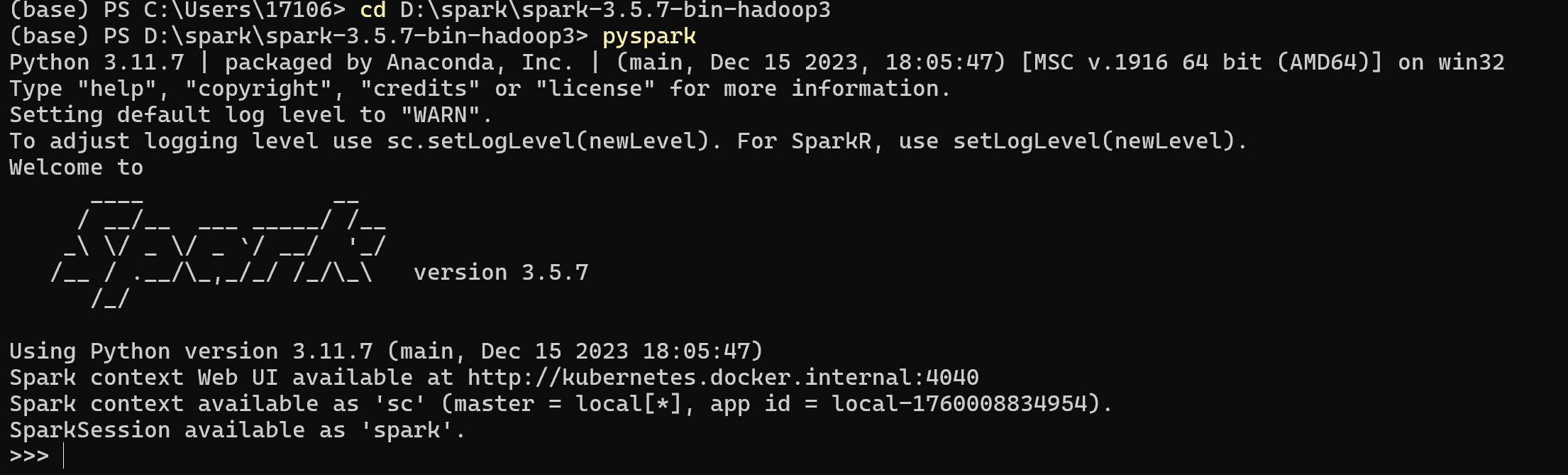
任务2
任务2(3分):Spark官方包中提供了多种语言编写的多个example程序,运行Spark自带的wordcount示例,功能是统计给定的文本文件中每一个单词出现的总次数。在熟悉wordcount示例之后,将food_delivery的Order_Date列提取出来,另存为一个文本文件,基于该输入文件运行wordcount示例,统计每一天的配送订单数量。
提交要求:提交程序运行输出的屏幕截屏,包括每一天的订单数量
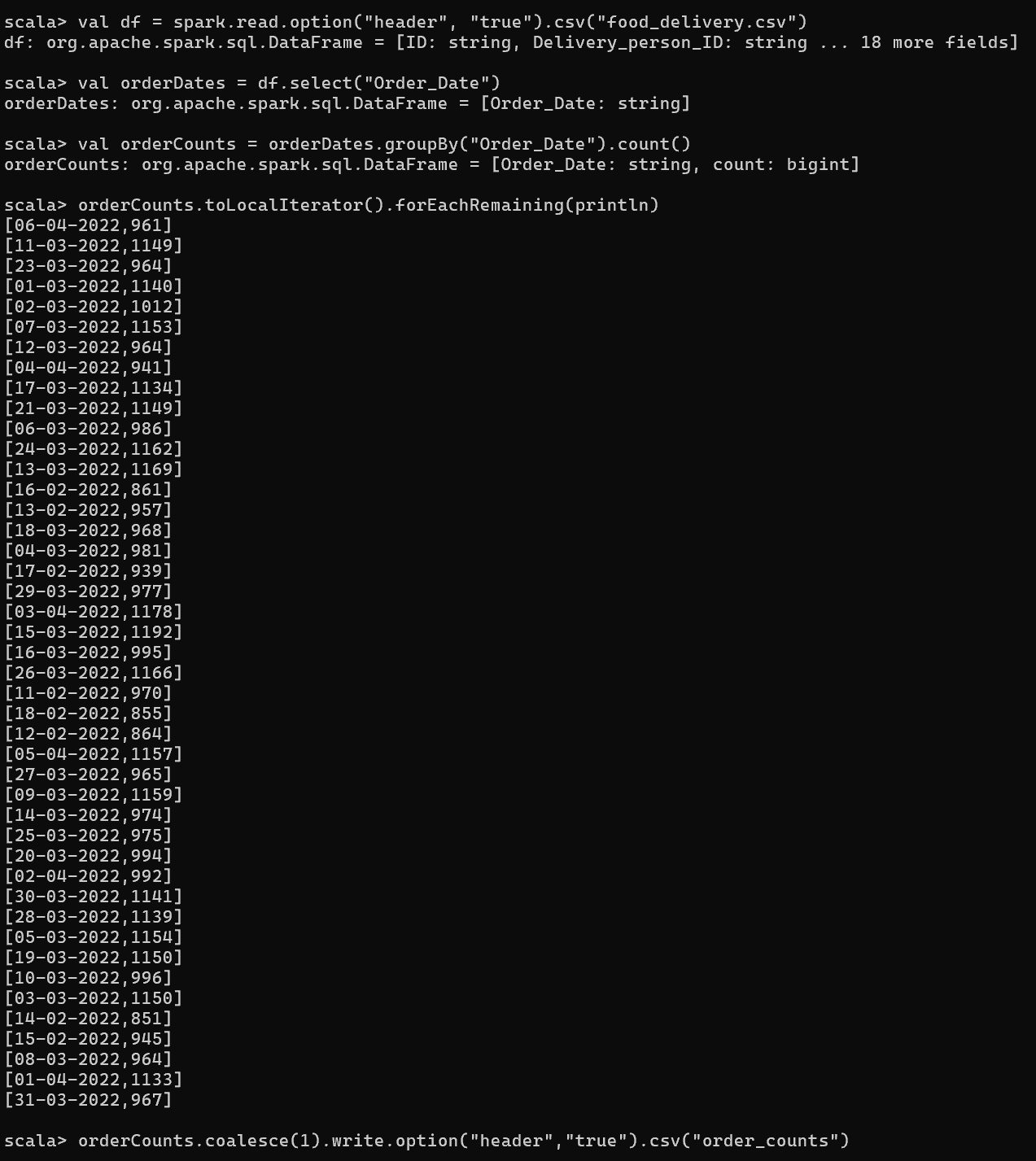
任务3
任务3(6分):基于Spark编写代码完成以下任务:查找年龄最大的配送人员的Delivery_person_ID。
提交要求:提交编写的代码,程序结果运行输出的截屏。
1 | import org.apache.spark.sql.SparkSession |
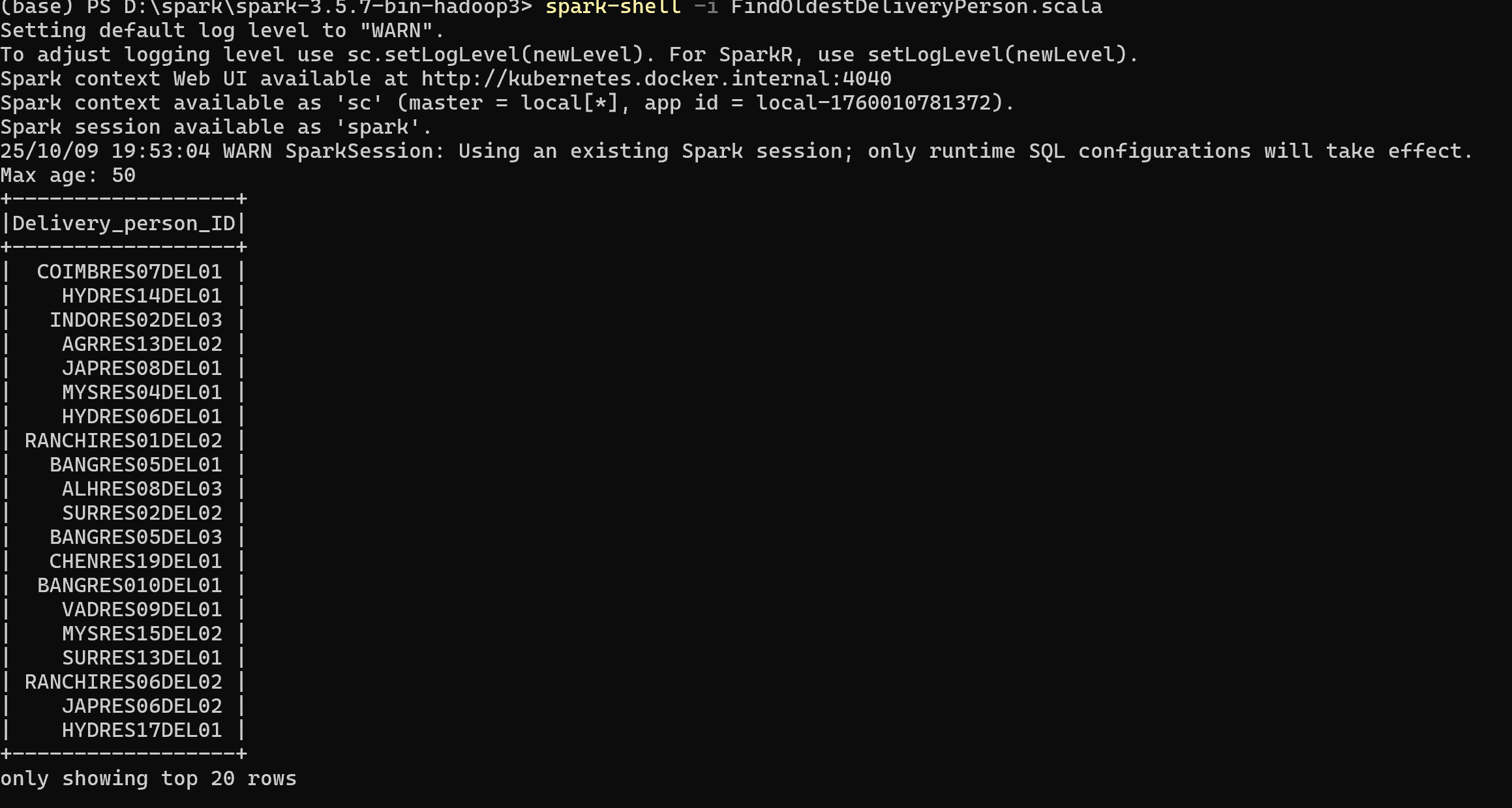
任务4
任务4(6分):基于Spark编写代码完成以下任务:统计2022年3月份的外卖订单的平均配送时间。
提交要求:提交编写的代码,程序结果运行输出的截屏。
1 | import org.apache.spark.sql.SparkSession |

执行方法:
将 Scala 代码保存为 FindOldestDeliveryPerson.scala 和 AvgDeliveryTimeMarch2022.scala。
使用 spark-shell 交互式运行,或者用 sbt / spark-submit 编译提交:
1 | spark-shell -i FindOldestDeliveryPerson.scala |
可能会有报错:java.nio.charset.MalformedInputException: Input length = 1
解决办法:将文件保存为UTF-8格式(VSCode右下角点击UTF-8),或者把注释改成英语or删除。